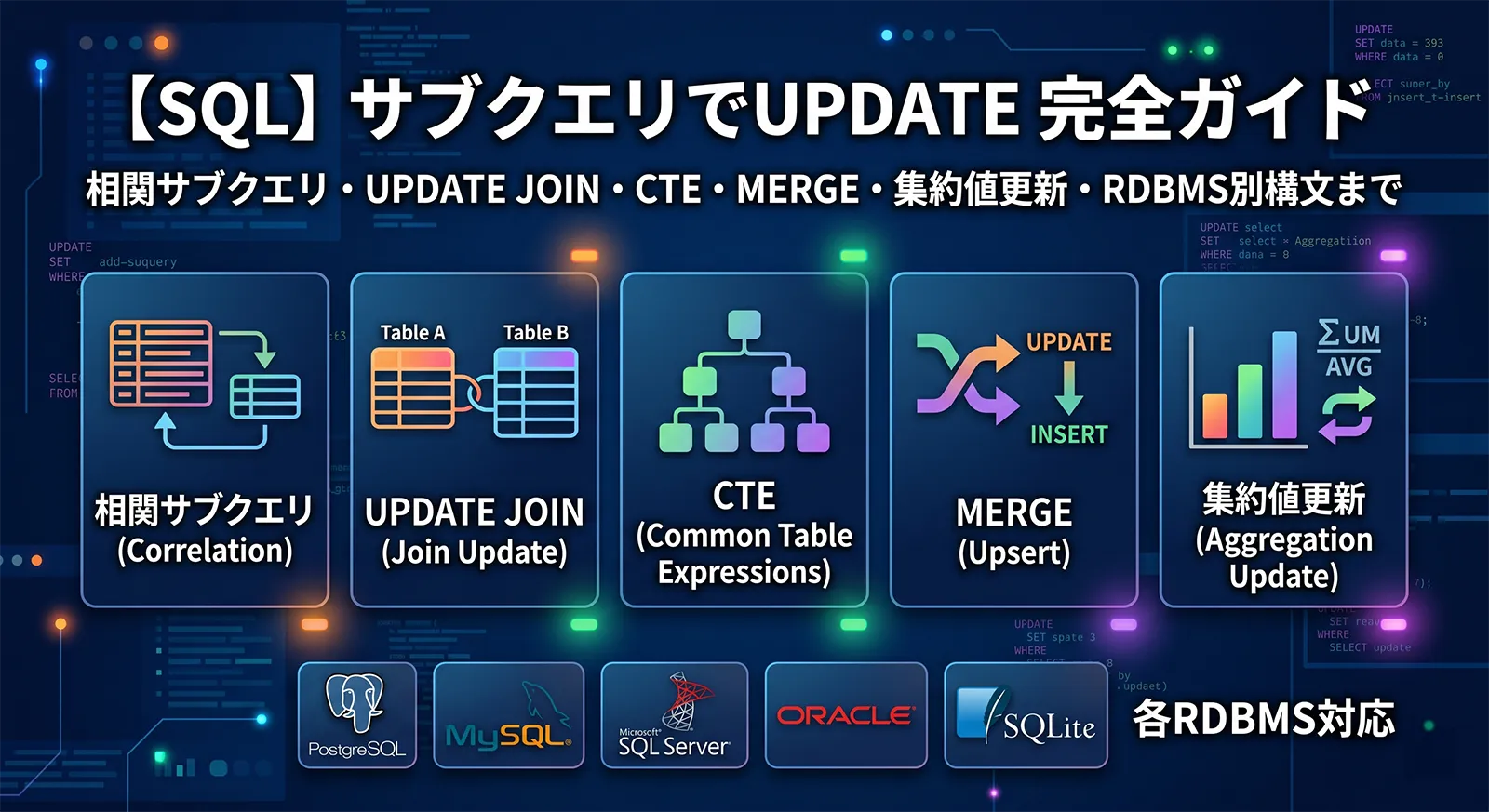
「別テーブルから値を取得してUPDATEしたい」という要件はSQL開発で頻出します。しかし、サブクエリを使ったUPDATEはRDBMSごとに構文が異なり、パフォーマンスにも差が出やすいポイントです。
本記事では、MySQL・PostgreSQL・SQL Server・Oracleでサブクエリを使ったUPDATEの書き方を体系的に解説します。どの方法をいつ使うべきかの判断基準も示します。
この記事で分かること
- SET句に相関サブクエリを使って別テーブルの値で更新する方法
- WHERE句にEXISTS / INを使って更新対象を絞り込む方法
- UPDATE JOIN(FROM句)でサブクエリを使わずに更新する方法
- CTE(WITH句)を使ったUPDATEの書き方
- MERGE文で条件付きUPDATE/INSERTを1文で行う方法
- 集約関数の結果で更新する方法(SUM/AVG/MAXなど)
- 複数列を同時にサブクエリで更新する方法
方法の選び方
サブクエリでのUPDATEにはいくつかの方法があります。状況に応じて最適な方法を選びましょう。
| 方法 | 使いどころ | 対応RDBMS |
|---|---|---|
| SET句の相関サブクエリ | 標準SQL。どのRDBMSでも使える基本形 | 全RDBMS |
| UPDATE JOIN(FROM句) | JOINで結合した結果で更新。高速・直感的 | MySQL / PostgreSQL / SQL Server |
| CTE(WITH句)+ UPDATE | 複雑な集計結果を使って更新 | PostgreSQL / SQL Server / Oracle(一部) |
| MERGE文 | 一致行は更新・不一致行は挿入(UPSERT) | SQL Server / Oracle / PostgreSQL(15+) |
SET句の相関サブクエリ — 全RDBMS共通
最も基本的な方法です。SET句のサブクエリが更新対象の各行に対して実行され、別テーブルの値を取得して更新します。標準SQLに準拠しているため、どのRDBMSでも動作します。
-- 給与変更テーブルの最新値で従業員テーブルを更新
UPDATE employees e
SET e.salary = (
SELECT sc.new_salary
FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
ORDER BY sc.change_date DESC
LIMIT 1 -- MySQL: 最新の1件
)
WHERE e.employee_id IN (
SELECT sc.employee_id FROM salary_changes sc
);
WHERE句を忘れない:WHERE句がないと、salary_changesに対応する行がない従業員のsalaryがNULLになります。WHERE IN / WHERE EXISTS で更新対象を絞り込むのが鉄則です。
-- EXISTS のほうが IN より高速になることが多い(特に大量データ)
UPDATE employees e
SET e.salary = (
SELECT sc.new_salary
FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
ORDER BY sc.change_date DESC
LIMIT 1
)
WHERE EXISTS (
SELECT 1 FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
);
Oracle / SQL Server での相関サブクエリ
Oracle では LIMIT 1 の代わりに ROWNUM や FETCH FIRST を使います。SQL Server は TOP 1 です。
-- Oracle: FETCH FIRST 1 ROW ONLY(12c+)
UPDATE employees e
SET e.salary = (
SELECT sc.new_salary
FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
ORDER BY sc.change_date DESC
FETCH FIRST 1 ROW ONLY
)
WHERE EXISTS (
SELECT 1 FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
);
-- Oracle: ROWNUM(11g以前)
UPDATE employees e
SET e.salary = (
SELECT new_salary FROM (
SELECT sc.new_salary
FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
ORDER BY sc.change_date DESC
) WHERE ROWNUM = 1
)
WHERE EXISTS (
SELECT 1 FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
);
UPDATE e
SET e.salary = (
SELECT TOP 1 sc.new_salary
FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
ORDER BY sc.change_date DESC
)
FROM employees e
WHERE EXISTS (
SELECT 1 FROM salary_changes sc
WHERE sc.employee_id = e.employee_id
);
UPDATE JOIN(FROM句) — 結合して更新
サブクエリの代わりにJOINで結合した結果を直接SETに使う方法です。相関サブクエリより読みやすく、パフォーマンスも良い場合が多いです。
UPDATE JOIN はRDBMSごとに構文が異なります。MySQL は UPDATE ... JOIN ... SET、PostgreSQL / SQL Server は UPDATE ... SET ... FROM です。
-- MySQL: UPDATE ... JOIN ... SET の構文
UPDATE employees e
INNER JOIN salary_changes sc
ON e.employee_id = sc.employee_id
SET e.salary = sc.new_salary,
e.updated_at = NOW()
WHERE sc.change_date = (
SELECT MAX(sc2.change_date)
FROM salary_changes sc2
WHERE sc2.employee_id = sc.employee_id
);
-- PostgreSQL: FROM句にJOIN先を書く
UPDATE employees e
SET salary = sc.new_salary,
updated_at = NOW()
FROM salary_changes sc
WHERE e.employee_id = sc.employee_id
AND sc.change_date = (
SELECT MAX(sc2.change_date)
FROM salary_changes sc2
WHERE sc2.employee_id = sc.employee_id
);
-- SQL Server: PostgreSQLと似た FROM句構文
UPDATE e
SET e.salary = sc.new_salary,
e.updated_at = GETDATE()
FROM employees e
INNER JOIN salary_changes sc
ON e.employee_id = sc.employee_id
WHERE sc.change_date = (
SELECT MAX(sc2.change_date)
FROM salary_changes sc2
WHERE sc2.employee_id = sc.employee_id
);
-- Oracle: 更新可能なインラインビュー(キー保存表が必要)
UPDATE (
SELECT e.salary AS old_salary,
sc.new_salary AS new_salary
FROM employees e
INNER JOIN salary_changes sc
ON e.employee_id = sc.employee_id
)
SET old_salary = new_salary;
-- ※ sc.employee_id に一意制約/PKが必要(キー保存表の条件)
Oracle のインラインビューUPDATE:結合先テーブルの結合キーに一意制約(PK / UNIQUE)がないと「ORA-01779: キー保存されていない表にマップする列は変更できません」エラーになります。この制限がある場合は MERGE 文を使います。
CTE(WITH句)で更新する
複雑な集計結果をサブクエリで使いたい場合、CTE(WITH句)で先に結果セットを定義してからUPDATEに使うと読みやすくなります。
-- 部署ごとの平均給与で従業員テーブルを更新
WITH dept_avg AS (
SELECT department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
UPDATE employees e
SET salary = da.avg_salary
FROM dept_avg da
WHERE e.department_id = da.department_id
AND e.role = 'junior'; -- ジュニアの給与を部署平均に揃える
-- SQL Serverでも同様にCTEでUPDATE可能
WITH dept_avg AS (
SELECT department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
UPDATE e
SET e.salary = da.avg_salary
FROM employees e
INNER JOIN dept_avg da
ON e.department_id = da.department_id
WHERE e.role = 'junior';
-- MySQL 8.0+ でCTEが使用可能
WITH dept_avg AS (
SELECT department_id,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
UPDATE employees e
INNER JOIN dept_avg da
ON e.department_id = da.department_id
SET e.salary = da.avg_salary
WHERE e.role = 'junior';
MERGE文 — 条件付き更新と挿入を同時に
MERGE文は「一致すれば更新、不一致なら挿入」を1つのSQLで行えます。いわゆるUPSERT処理に最適です。
-- salary_changes をもとに employees を更新(なければ挿入)
MERGE INTO employees AS target
USING salary_changes AS source
ON target.employee_id = source.employee_id
WHEN MATCHED THEN
UPDATE SET target.salary = source.new_salary,
target.updated_at = GETDATE()
WHEN NOT MATCHED THEN
INSERT (employee_id, salary, updated_at)
VALUES (source.employee_id, source.new_salary, GETDATE());
MERGE INTO employees target
USING salary_changes source
ON (target.employee_id = source.employee_id)
WHEN MATCHED THEN
UPDATE SET target.salary = source.new_salary,
target.updated_at = SYSDATE
WHEN NOT MATCHED THEN
INSERT (employee_id, salary, updated_at)
VALUES (source.employee_id, source.new_salary, SYSDATE);
-- MySQL には MERGE がないが、INSERT ON DUPLICATE KEY UPDATE で代替
INSERT INTO employees (employee_id, salary, updated_at)
SELECT employee_id, new_salary, NOW()
FROM salary_changes
ON DUPLICATE KEY UPDATE
salary = VALUES(salary),
updated_at = VALUES(updated_at);
-- employee_id に一意制約が必要
集約値で更新する
SUM / AVG / MAX / COUNT の結果で別テーブルを更新するパターンは、集計テーブルの定期更新などで頻出します。
-- 全RDBMS共通
UPDATE customers c
SET c.total_spent = (
SELECT SUM(o.amount)
FROM orders o
WHERE o.customer_id = c.customer_id
)
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id
);
-- PostgreSQL: FROM句で集約結果をJOIN
UPDATE customers c
SET total_spent = o_sum.total_amount
FROM (
SELECT customer_id,
SUM(amount) AS total_amount
FROM orders
GROUP BY customer_id
) o_sum
WHERE c.customer_id = o_sum.customer_id;
-- MySQL: JOINでサブクエリを結合
UPDATE customers c
INNER JOIN (
SELECT customer_id,
SUM(amount) AS total_amount
FROM orders
GROUP BY customer_id
) o_sum ON c.customer_id = o_sum.customer_id
SET c.total_spent = o_sum.total_amount;
-- 複数の集約値を一度に更新する
UPDATE customers c
SET c.order_count = (
SELECT COUNT(*)
FROM orders o WHERE o.customer_id = c.customer_id
),
c.last_order_date = (
SELECT MAX(o.order_date)
FROM orders o WHERE o.customer_id = c.customer_id
)
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id
);
複数列を同時にサブクエリで更新する
複数の列を別テーブルの値で一度に更新する場合、SET句にサブクエリを複数書く方法と、行コンストラクタを使う方法があります。
-- 全RDBMS共通: SET句にサブクエリを複数書く
UPDATE products p
SET p.price = (
SELECT s.new_price FROM price_updates s
WHERE s.product_id = p.product_id
),
p.updated_at = (
SELECT s.effective_date FROM price_updates s
WHERE s.product_id = p.product_id
)
WHERE EXISTS (
SELECT 1 FROM price_updates s WHERE s.product_id = p.product_id
);
-- ※ サブクエリが2回実行されるためパフォーマンスに注意
-- Oracle: (列1, 列2) = (サブクエリ) で1回のサブクエリで済む
UPDATE products p
SET (p.price, p.updated_at) = (
SELECT s.new_price, s.effective_date
FROM price_updates s
WHERE s.product_id = p.product_id
)
WHERE EXISTS (
SELECT 1 FROM price_updates s WHERE s.product_id = p.product_id
);
-- サブクエリの実行が1回で済むため効率的
-- MySQL
UPDATE products p
INNER JOIN price_updates s ON p.product_id = s.product_id
SET p.price = s.new_price,
p.updated_at = s.effective_date;
-- PostgreSQL
UPDATE products p
SET price = s.new_price,
updated_at = s.effective_date
FROM price_updates s
WHERE p.product_id = s.product_id;
-- SQL Server
UPDATE p
SET p.price = s.new_price,
p.updated_at = s.effective_date
FROM products p
INNER JOIN price_updates s ON p.product_id = s.product_id;
複数列の更新には UPDATE JOIN が最も効率的:相関サブクエリを複数書くと列の数だけサブクエリが実行されます。UPDATE JOIN なら1回の結合で済みます。
自テーブルのサブクエリで更新する
同じテーブルの別の行の値を使って更新する場合も、サブクエリが使えます。
-- 上司の給与を部下のMAX給与 + 10% に設定
UPDATE employees e
SET e.salary = (
SELECT MAX(sub.salary) * 1.1
FROM employees sub
WHERE sub.manager_id = e.employee_id
)
WHERE e.employee_id IN (
SELECT DISTINCT manager_id FROM employees WHERE manager_id IS NOT NULL
);
-- MySQL の場合: 同一テーブルのサブクエリは直接UPDATE+SELECTできない制限あり
-- → サブクエリをさらにサブクエリで包む
UPDATE employees e
SET e.salary = (
SELECT max_salary FROM (
SELECT manager_id, MAX(salary) * 1.1 AS max_salary
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id
) tmp
WHERE tmp.manager_id = e.employee_id
)
WHERE e.employee_id IN (
SELECT DISTINCT manager_id FROM employees WHERE manager_id IS NOT NULL
);
MySQL の制限:MySQL では UPDATE 文のサブクエリで更新対象と同じテーブルを直接参照すると「ERROR 1093: You can’t specify target table for update in FROM clause」が発生します。サブクエリをさらにサブクエリで囲む(派生テーブル化する)ことで回避できます。
パフォーマンスの注意点
| 注意点 | 対処方法 |
|---|---|
| 相関サブクエリは行ごとに実行される | UPDATE JOIN や MERGE に書き換えて結合1回で済ませる |
| サブクエリの結合キーにインデックスがない | WHERE句の結合キーにインデックスを追加する |
| 大量行のUPDATEでロックが広がる | バッチ分割(WHERE id BETWEEN … AND …)でコミット |
| NOT INサブクエリがNULLで誤動作 | NOT EXISTS に書き換える(NOT IN完全ガイドを参照) |
-- 10万行を1000行ずつバッチ更新(MySQL例)
SET @batch = 0;
REPEAT
UPDATE employees e
INNER JOIN salary_changes sc ON e.employee_id = sc.employee_id
SET e.salary = sc.new_salary
WHERE e.employee_id > @batch
ORDER BY e.employee_id
LIMIT 1000;
SET @batch = @batch + 1000;
UNTIL ROW_COUNT() = 0 END REPEAT;
まとめ
| 方法 | メリット | デメリット | 対応RDBMS |
|---|---|---|---|
| SET句の相関サブクエリ | 標準SQL・全RDBMS対応 | 行ごとに実行・遅い場合あり | 全RDBMS |
| UPDATE JOIN | 高速・直感的 | 構文がRDBMSごとに異なる | MySQL / PG / SQL Server |
| CTE + UPDATE | 複雑な集計が読みやすい | Oracle非対応(一部) | PG / SQL Server / MySQL 8.0+ |
| MERGE | UPSERT が1文で完結 | MySQL非対応 | SQL Server / Oracle / PG 15+ |
- 全RDBMSで動く基本形はSET句の相関サブクエリ + WHERE EXISTS
- パフォーマンスを優先するならUPDATE JOIN(構文はRDBMS別に覚える)
- 複雑な集計結果で更新するならCTE(WITH句)で可読性を確保
- 「あれば更新・なければ挿入」にはMERGE(MySQL は INSERT ON DUPLICATE KEY UPDATE)
- WHERE句の絞り込みを忘れるとNULLで上書きされるので必ず EXISTS / IN で対象を限定する
- UPDATE文の基礎についてはUPDATE完全ガイドを、CASE WHENによる条件付き更新はCASE WHEN完全ガイドを参照してください