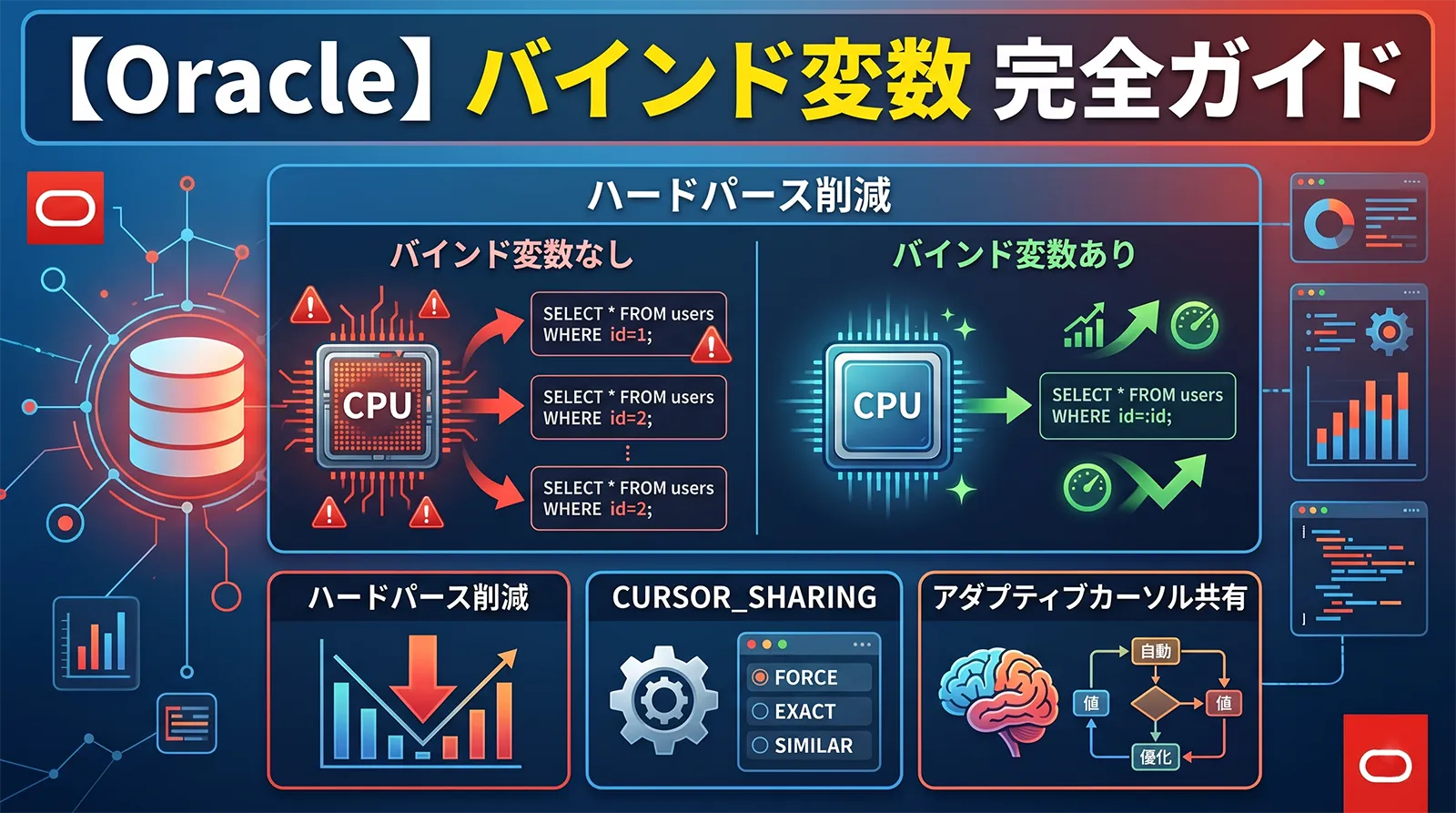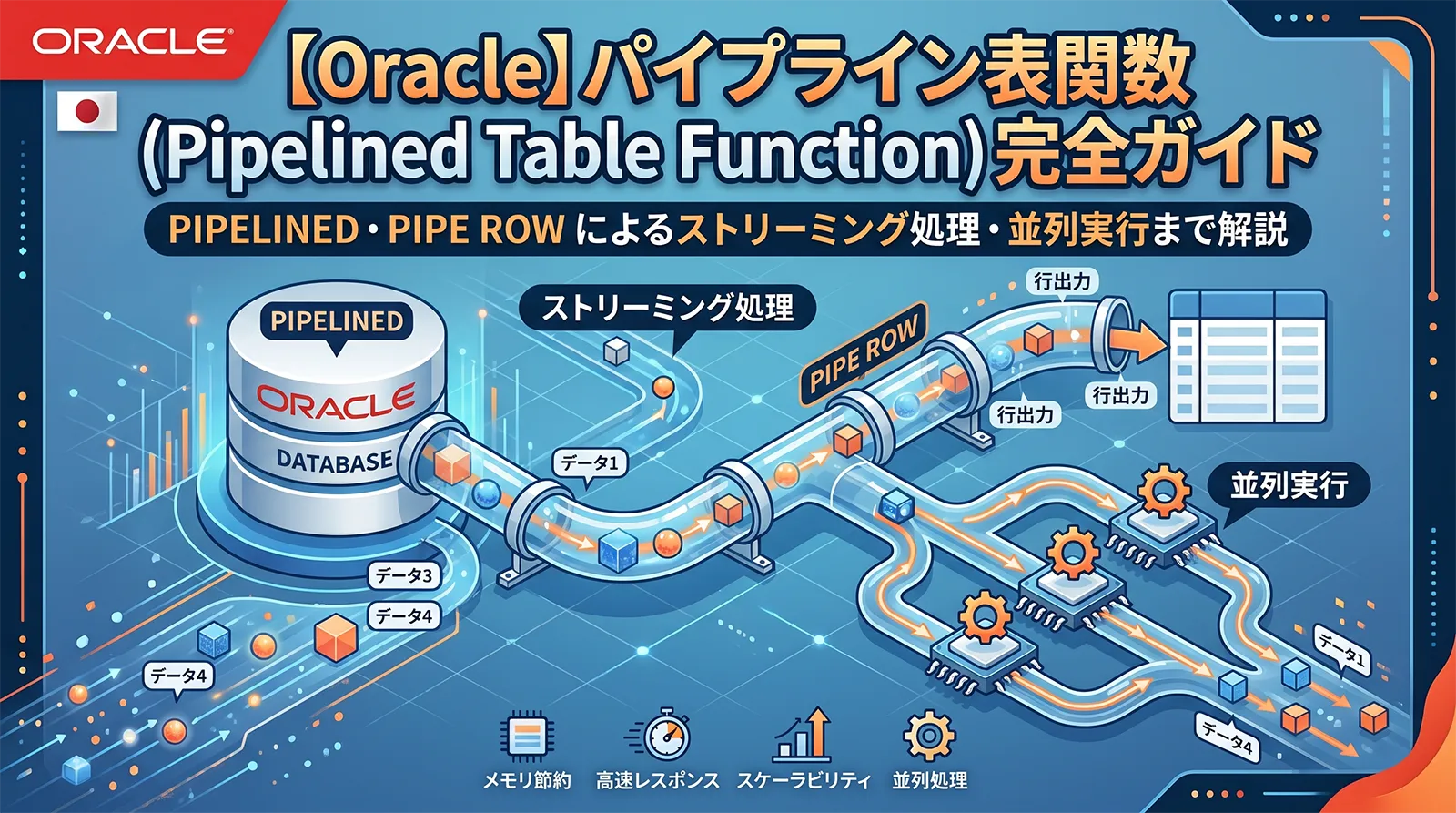
Oracle のパイプライン表関数(Pipelined Table Function)は、FROM 句でテーブルのように呼び出せる PL/SQL 関数です。通常の TABLE 関数と違い、PIPE ROW() で行を1件ずつ返しながら処理を続けるため、全件をメモリに溜め込まずにストリーミングで結果を返せます。
大量レコードの変換・ETL 処理・複雑なビジネスロジックを SQL として扱いたい場面で特に威力を発揮します。PARALLEL ENABLE 句と組み合わせると並列クエリにも対応できます。
この記事でわかること
- パイプライン表関数の仕組みと通常の関数・TABLE 関数との違い
- PIPELINED キーワードと PIPE ROW() の使い方
- 戻り値の型(コレクション型・オブジェクト型)の定義方法
- FROM 句・TABLE() でパイプライン表関数を呼び出す方法
- PARALLEL ENABLE PARTITION BY で並列クエリに対応する方法
- ETL・ログ変換・CSV 生成など実務的なユースケース
パイプライン表関数の仕組みと通常関数との違い
| 種別 | 戻り方 | メモリ | FROM 句使用 | 用途 |
|---|---|---|---|---|
| 通常の関数 | スカラー値 1 件を RETURN | – | 不可 | 計算・変換 |
| TABLE 関数(非パイプライン) | コレクション全体を RETURN | 全件をメモリに保持 | 可(TABLE()) | 中〜小規模の行生成 |
| パイプライン表関数 | PIPE ROW() で1行ずつストリーミング | 少量(随時解放) | 可(TABLE()) | 大規模行生成・ETL |
パイプライン表関数は処理中に PIPE ROW(value) を呼ぶたびに、呼び出し元の SQL に1行を即座に送信します。関数全体の処理が終わるまで結果を待たずに済むため、大規模データの変換処理でもメモリ消費が一定に保たれます。
パイプライン表関数の基本構文
パイプライン表関数を作成するには次の3つが必要です。
- 返す行の型(オブジェクト型)と、その型のコレクション型(TABLE OF)を定義する
- 関数に
PIPELINEDキーワードを付けて RETURN 型をコレクション型にする - 行を返す箇所で
PIPE ROW(値)を呼ぶ。関数末尾ではRETURN;(値なし)で終了する
パイプライン表関数の基本構文
-- ステップ1: 返す行の型をオブジェクト型として定義する
CREATE OR REPLACE TYPE emp_row_t AS OBJECT (
emp_id NUMBER,
emp_name VARCHAR2(100),
dept_name VARCHAR2(100),
salary NUMBER
);
/
-- ステップ2: 上記オブジェクト型のコレクション型(テーブル型)を定義する
CREATE OR REPLACE TYPE emp_row_tab_t AS TABLE OF emp_row_t;
/
-- ステップ3: パイプライン表関数を作成する
CREATE OR REPLACE FUNCTION get_emp_with_dept
RETURN emp_row_tab_t
PIPELINED -- ← パイプライン宣言(必須)
AS
BEGIN
FOR rec IN (
SELECT e.employee_id, e.last_name, d.department_name, e.salary
FROM employees e
JOIN departments d ON e.department_id = d.department_id
) LOOP
PIPE ROW(emp_row_t( -- ← 1行ずつ返す(PIPE ROW が核心)
rec.employee_id,
rec.last_name,
rec.department_name,
rec.salary
));
END LOOP;
RETURN; -- ← 値なし RETURN(必須)
END get_emp_with_dept;
/
-- FROM 句で TABLE() を使って呼び出す
SELECT emp_id, emp_name, dept_name, salary
FROM TABLE(get_emp_with_dept())
WHERE salary > 50000
ORDER BY salary DESC;
-- 通常のテーブルと同じように WHERE・ORDER BY・JOIN が使える
スカラー型を返すシンプルなパイプライン表関数
オブジェクト型を使わなくても、VARCHAR2 や NUMBER などのスカラー型の TABLE 型を使ったシンプルな関数も作れます。
文字列配列を返すパイプライン表関数
-- VARCHAR2 のコレクション型をあらかじめ定義しておく
CREATE OR REPLACE TYPE str_tab_t AS TABLE OF VARCHAR2(4000);
/
-- CSV 文字列を分割して行に変換するパイプライン表関数
CREATE OR REPLACE FUNCTION split_csv(
p_csv VARCHAR2,
p_delimiter VARCHAR2 DEFAULT ','
)
RETURN str_tab_t
PIPELINED
AS
v_start PLS_INTEGER := 1;
v_end PLS_INTEGER;
v_len PLS_INTEGER := LENGTH(p_csv);
BEGIN
LOOP
v_end := INSTR(p_csv, p_delimiter, v_start);
IF v_end = 0 THEN
-- 最後のトークン
PIPE ROW(TRIM(SUBSTR(p_csv, v_start)));
EXIT;
END IF;
PIPE ROW(TRIM(SUBSTR(p_csv, v_start, v_end - v_start)));
v_start := v_end + LENGTH(p_delimiter);
END LOOP;
RETURN;
END split_csv;
/
-- 使い方: CSV 文字列を行に分割する
SELECT COLUMN_VALUE AS item
FROM TABLE(split_csv('apple, banana, cherry, date'));
-- 出力:
-- item
-- ------
-- apple
-- banana
-- cherry
-- date
-- テーブルの列に格納された CSV をすべて展開する
SELECT t.id, s.COLUMN_VALUE AS tag
FROM articles t,
TABLE(split_csv(t.tags, ';')) s;
-- articles.tags = 'oracle;plsql;performance' などをバラして結合できる
PARALLEL ENABLE で並列クエリに対応する
パイプライン表関数に PARALLEL ENABLE PARTITION BY を付けると、オラクルの並列クエリ基盤が複数のスレーブプロセスでこの関数を並列実行できます。大量データの ETL 処理で効果的です。
PARALLEL ENABLE で並列実行に対応したパイプライン表関数
-- 並列クエリ対応のパイプライン表関数
-- 入力は REF CURSOR(並列スレーブが分割した行群を受け取る)
CREATE OR REPLACE TYPE transformed_row_t AS OBJECT (
order_id NUMBER,
total_amount NUMBER,
category VARCHAR2(50),
processed_at DATE
);
/
CREATE OR REPLACE TYPE transformed_tab_t AS TABLE OF transformed_row_t;
/
-- 入力 REF CURSOR の型を定義する(パッケージで定義することが多い)
CREATE OR REPLACE PACKAGE order_transform_pkg AS
TYPE orders_cur_t IS REF CURSOR RETURN orders%ROWTYPE;
END order_transform_pkg;
/
-- PARALLEL ENABLE + PARTITION BY ANY: どの行がどのスレーブに渡されても問題ない処理
CREATE OR REPLACE FUNCTION transform_orders(
p_cursor order_transform_pkg.orders_cur_t -- 並列スレーブが分割した入力
)
RETURN transformed_tab_t
PIPELINED
PARALLEL ENABLE (PARTITION p_cursor BY ANY) -- ← 並列実行を宣言
AS
v_rec orders%ROWTYPE;
BEGIN
LOOP
FETCH p_cursor INTO v_rec;
EXIT WHEN p_cursor%NOTFOUND;
-- 変換ロジック(ここが各並列スレーブで並列実行される)
PIPE ROW(transformed_row_t(
v_rec.order_id,
v_rec.quantity * v_rec.unit_price, -- 合計金額の計算
CASE
WHEN v_rec.quantity > 100 THEN 'BULK'
ELSE 'STANDARD'
END,
SYSDATE
));
END LOOP;
RETURN;
END transform_orders;
/
-- 並列クエリとして実行する(Degree Of Parallelism = 4)
SELECT /*+ PARALLEL(o, 4) */ *
FROM TABLE(transform_orders(
CURSOR(SELECT * FROM orders WHERE order_date >= DATE '2024-01-01')
));
-- Oracle が自動的に CURSOR の内容を4つの並列スレーブに分割して処理する
-- PARTITION BY 3種類:
-- BY ANY : どの行がどのスレーブに来てもよい(順序不問・最も柔軟)
-- BY HASH(col): 同じ col 値は必ず同じスレーブへ(GROUP BY 的な集計に使う)
-- BY RANGE(col): 範囲でスレーブに振り分ける(ソート済み出力が必要な場合)
実務ユースケース: ETL・ログ変換・レポート生成
ETL: ステージングテーブルを変換して返すパイプライン表関数
-- ステージングテーブルのデータを検証・変換して返す
CREATE OR REPLACE TYPE order_fact_t AS OBJECT (
order_id NUMBER,
customer_id NUMBER,
product_code VARCHAR2(20),
qty NUMBER,
unit_price NUMBER,
total_amount NUMBER,
order_date DATE,
is_valid CHAR(1), -- Y: 正常, N: エラー
error_message VARCHAR2(500)
);
/
CREATE OR REPLACE TYPE order_fact_tab_t AS TABLE OF order_fact_t;
/
CREATE OR REPLACE FUNCTION validate_and_transform_orders
RETURN order_fact_tab_t
PIPELINED
AS
v_total NUMBER;
v_valid CHAR(1);
v_errmsg VARCHAR2(500);
BEGIN
FOR rec IN (
SELECT * FROM stg_orders WHERE processed = 'N'
) LOOP
-- 検証ロジック
v_valid := 'Y';
v_errmsg := NULL;
v_total := rec.qty * rec.unit_price;
IF rec.qty IS NULL OR rec.qty <= 0 THEN
v_valid := 'N';
v_errmsg := '数量が不正: ' || rec.qty;
ELSIF rec.unit_price IS NULL OR rec.unit_price < 0 THEN
v_valid := 'N';
v_errmsg := '単価が不正: ' || rec.unit_price;
ELSIF rec.customer_id NOT IN (SELECT customer_id FROM customers) THEN
v_valid := 'N';
v_errmsg := '顧客が存在しない: ' || rec.customer_id;
END IF;
PIPE ROW(order_fact_t(
rec.order_id, rec.customer_id, rec.product_code,
rec.qty, rec.unit_price, v_total,
rec.order_date, v_valid, v_errmsg
));
END LOOP;
RETURN;
END validate_and_transform_orders;
/
-- 正常レコードだけ本番テーブルに INSERT する
INSERT INTO orders_fact (order_id, customer_id, product_code, qty, unit_price, total_amount, order_date)
SELECT order_id, customer_id, product_code, qty, unit_price, total_amount, order_date
FROM TABLE(validate_and_transform_orders())
WHERE is_valid = 'Y';
-- エラーレコードをログに INSERT する
INSERT INTO orders_error_log (order_id, error_message, logged_at)
SELECT order_id, error_message, SYSDATE
FROM TABLE(validate_and_transform_orders())
WHERE is_valid = 'N';
-- 注意: 上記2つの INSERT で関数は2回実行される。
-- 1回の実行で済ませるには CTAS か WITH MATERIALIZE ヒントを使う
INSERT INTO orders_fact ...
SELECT ...
FROM (SELECT /*+ MATERIALIZE */ * FROM TABLE(validate_and_transform_orders())) t
WHERE t.is_valid = 'Y';
パイプライン表関数での例外処理
PIPE ROW 中の例外をハンドルする
-- PIPE ROW の途中で例外が発生した場合の処理
CREATE OR REPLACE FUNCTION safe_transform
RETURN str_tab_t
PIPELINED
AS
v_result VARCHAR2(4000);
BEGIN
FOR rec IN (SELECT raw_data FROM data_source) LOOP
BEGIN
-- 変換ロジック(例外が発生する可能性がある)
v_result := transform_data(rec.raw_data); -- 変換処理
PIPE ROW(v_result);
EXCEPTION
WHEN OTHERS THEN
-- エラーをスキップして次の行を処理する(ログだけ記録)
DBMS_OUTPUT.PUT_LINE('変換エラー: ' || SQLERRM || ' データ: ' || SUBSTR(rec.raw_data, 1, 100));
PIPE ROW('ERROR: ' || SQLERRM); -- エラー情報を返すこともできる
END;
END LOOP;
RETURN;
END safe_transform;
/
-- 呼び出し元が途中でフェッチを止めた場合(NO_DATA_NEEDED):
-- Oracle は関数を途中で停止するが、これは正常な動作
-- EXCEPTION WHEN NO_DATA_NEEDED でクリーンアップ処理を書ける
CREATE OR REPLACE FUNCTION streaming_with_cleanup
RETURN str_tab_t
PIPELINED
AS
BEGIN
FOR i IN 1..1000000 LOOP
PIPE ROW(TO_CHAR(i));
END LOOP;
RETURN;
EXCEPTION
WHEN NO_DATA_NEEDED THEN
-- 呼び出し元がFETCHを止めた場合のクリーンアップ(リソース解放など)
NULL; -- 通常は何もしなくて良い
END;
/
まとめ
- パイプライン表関数の特徴:PIPELINED キーワードで宣言し PIPE ROW() で1行ずつ返す。全件をメモリに保持せずストリーミング処理できる
- 型の定義:オブジェクト型(AS OBJECT)とそのコレクション型(AS TABLE OF)を事前に CREATE TYPE で作成する。VARCHAR2 などスカラーのコレクション型でもよい
- FROM 句での使い方:TABLE(関数名(引数)) で呼び出す。WHERE・JOIN・GROUP BY を通常のテーブルと同じように使える
- PARALLEL ENABLE:REF CURSOR を入力に取る構成で PARTITION BY ANY/HASH/RANGE を指定すると、並列クエリの各スレーブで並列実行できる
- NO_DATA_NEEDED:呼び出し元が FETCH を途中で止めた場合に発生する。EXCEPTION 句でキャッチしてリソースを解放できる
- ユースケース:大量データの ETL・CSV 分割・ログ変換・複雑なビジネスロジックを SQL として扱いたい場面に適している
大量データを効率よく INSERT するダイレクト・パス INSERT と組み合わせる方法は ダイレクト・パス INSERT 完全ガイドを参照してください。BULK COLLECT と FORALL を使ったバルク処理との使い分けは PL/SQL コレクション完全ガイドも参照してください。