「このプロジェクトでは pnpm を使う、と先週も教えたのに——」。Claude Code を複数のプロジェクトや複数のデバイスで使っていると、この感覚は避けられません。Claude Code のメモリはデフォルトでプロジェクトごとに完全に分断されているため、あるプロジェクトで学習させたフィードバックは別プロジェクトに引き継がれません。デバイスを変えた瞬間、その学習はリセットされます。
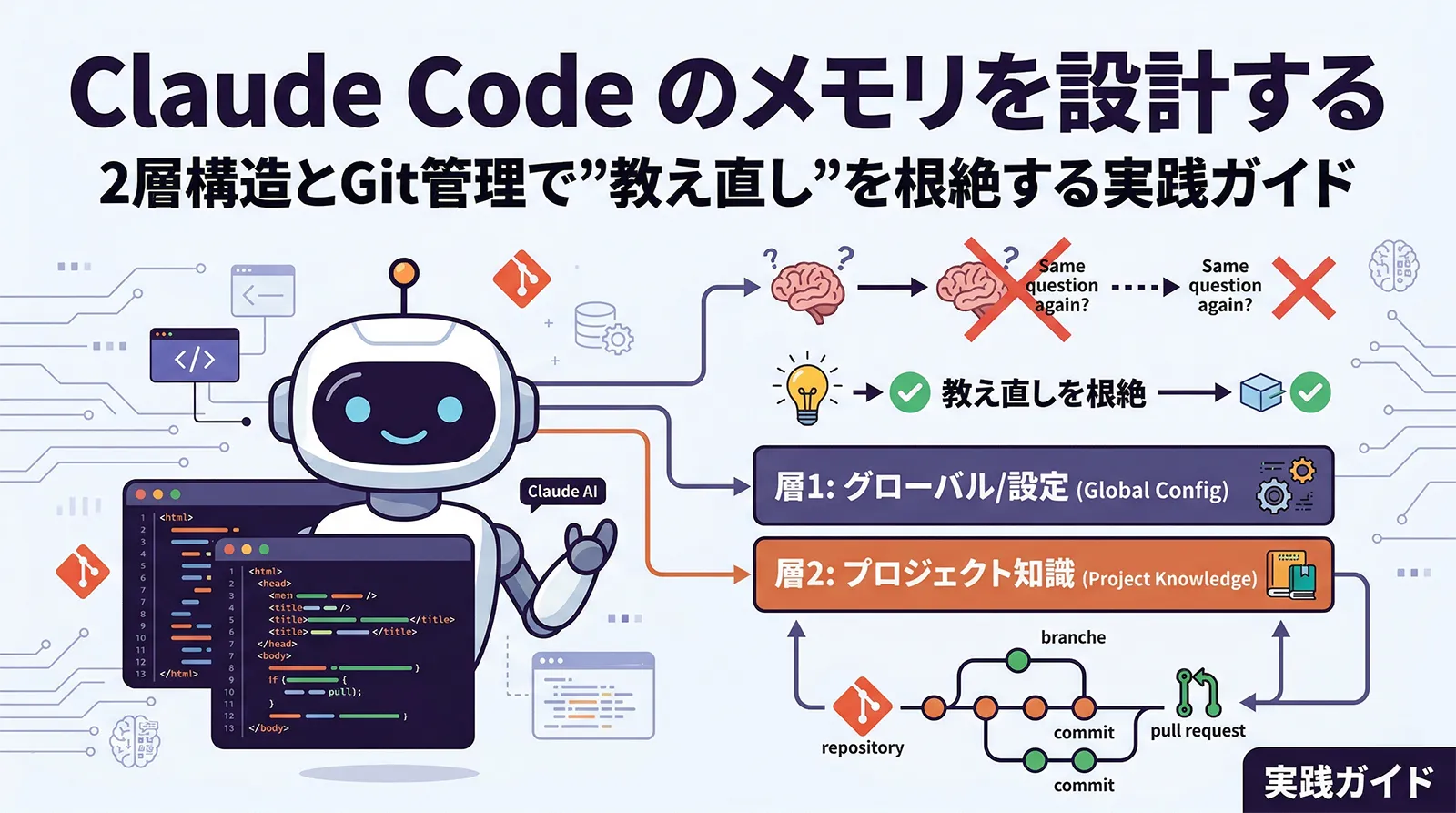
この問題の解決策は「メモリをどこに置くか」ではなく「メモリをどう設計するか」です。本記事では、Claude Code のメモリを Global 層と Project 層の2層に分けてGitで管理する設計アーキテクチャを体系的に解説します。単なるセットアップ手順ではなく、「なぜ2層か」「どの知識をどの層に置くか」「description の書き方でパフォーマンスがどう変わるか」「メモリが腐敗するとどうなるか」という設計の根拠まで掘り下げます。
- 「教え直し」の根本原因:メモリの分断
- Claude Code のメモリ構造:ファイル・読み込み・種別
- 2層設計の原則:Global と Project の役割分担
- description の書き方:読まれるメモリ・読まれないメモリ
- 昇格ルール:どの知識をいつ Global に上げるか
- セットアップ手順:GitHub リポジトリ + CLAUDE.md 設定
- 同期の運用:手動同期と Hooks による自動化
- Memory Rot を防ぐ:メモリが腐敗するとどうなるか
- auto-memory との役割分担を整理する
- よくある失敗パターンと対処法
- 昇格の具体的なシナリオ:Before / After で見る
- Global メモリの実践的なサンプル集
- 実践的な運用フロー:日常の使い方
- よくある質問
- まとめ:設計することで Claude Code は”賢くなり続ける”
「教え直し」の根本原因:メモリの分断
Claude Code にフィードバックを与えたとき、そのフィードバックはどこに保存されるのでしょうか。
デフォルトでは ~/.claude/projects/<hash>/memory/ 配下に保存されます。<hash> はプロジェクトディレクトリのパスから生成されるため、プロジェクトが違えば別のハッシュになり、記憶が共有されません。
| 状況 | 起きること | 根本原因 |
|---|---|---|
| 別プロジェクトで同じ指示 | 「Co-Authored-By を付けないで」を再度言わされる | プロジェクトハッシュが異なるためメモリが共有されない |
| 別デバイスに切り替え | 「pnpm を使う」を再学習させる | ~/.claude/ がデバイスごとに独立 |
| 同じツールの別バージョン問題 | 「ESLint 9 は flat config が必要」を毎回教える | 過去のフィードバックが他プロジェクトに伝播しない |
| チームメンバーとの共有 | チーム全員が同じ罠にはまる | メモリはユーザーローカルでチームに展開できない |
この問題はメモリの「物理的な分断」から来ています。分断を解消するには、メモリの保存場所を変えるのではなく、どの知識をどこに置くかを意識的に設計する必要があります。
Claude Code のメモリ構造:ファイル・読み込み・種別
設計を始める前に、Claude Code のメモリが内部でどう動いているかを理解しておきます。
ファイルの保存場所と読み込みの仕組み
Claude Code のメモリシステムは2つのファイルで構成されます。
| ファイル | 役割 | 読み込みタイミング |
|---|---|---|
MEMORY.md |
インデックスファイル。個別メモリファイルへのポインタと1行説明を列挙 | 常時読み込み(すべてのセッションで自動的に読まれる) |
個別メモリファイル(*.md) |
実際の記憶の内容。frontmatter + 本文 | オンデマンド読み込み(MEMORY.md の説明を見て必要と判断したときだけ読む) |
この設計の重要な含意は、MEMORY.md のインデックス説明文がコンテキストの使用量を決めるということです。説明文が曖昧だとメモリが余分に読まれ、具体的だと必要なときだけ読まれます(詳細は後述)。
5種類のメモリ種別
個別メモリファイルの frontmatter には type フィールドで種別を指定します。種別は管理のためのラベルであり、Claude Code の動作を変えるわけではありませんが、どの情報をどの層(Global/Project)に置くかの判断基準になります。
| 種別 | 何を記録するか | 典型例 | 主にどの層に置くか |
|---|---|---|---|
user |
ユーザーのスキルレベル・役割・作業スタイルの好み | 「Goに10年の経験があるがReactは初めて」 | Global(ユーザー自身の特性は全プロジェクト共通) |
feedback |
Claude の動作に対する指示・修正(やってほしいこと・やめてほしいこと) | 「Co-Authored-By は付けない」「コメントを過剰に追加しない」 | Global(行動規範は全プロジェクトで同じ) |
project |
期間限定の状態・締め切り・そのプロジェクト固有の文脈 | 「3/5からマージフリーズ」「APIは認証なしで動作する(本番ではNG)」 | Project(有効期限があり他プロジェクトには不要) |
reference |
外部システムへのポインタ(どこを見れば情報があるか) | 「バグはLinearの INGESTプロジェクトで管理」 | Project(プロジェクトごとに異なる) |
fixes |
繰り返し起きるエラーのパターンと解決策 | 「ESLint 9はflat configが必要(.eslintrc.jsは廃止)」 | 判断が必要(後述) |
fixes 種別の配置(Global か Project か)は最も判断が難しく、誤ると後で問題になります。これは「昇格ルール」で詳しく扱います。
2層設計の原則:Global と Project の役割分担
「教え直し」問題を解決する設計は、メモリを2つの層に分けることです。
| Global メモリ | Project メモリ | |
|---|---|---|
| 保存場所 | ~/.claude/global-memory/(Git管理) |
~/.claude/projects/<hash>/memory/(デフォルト) |
| 有効範囲 | すべてのプロジェクト・すべてのデバイス | そのプロジェクトのみ |
| 入れるべき知識 | 2つ以上のプロジェクトで共通して有効な知識 | そのプロジェクト固有の文脈・期間限定の状態 |
| 代表的な種別 | user・feedback・横断的なfixes |
project・reference・プロジェクト固有のfixes |
| 同期 | Git(GitHub等)で複数デバイスに展開 | 同期しない(プロジェクト固有のため不要) |
なぜ1層(すべて Global)ではダメか
「すべてを Global に入れれば常に参照できて便利ではないか」と思うかもしれません。しかし全情報を Global に入れると3つの問題が生じます。
- ノイズの増加:Project 固有の情報(「このAPIはステージング環境でのみ動く」)が全プロジェクトのコンテキストを汚染する
- コンテキストの肥大化:MEMORY.md が大きくなるほど常時読み込みのオーバーヘッドが増え、Claude が全エントリを参照し続ける
- 情報の陳腐化:Project 固有の「マージフリーズ」「一時的な設定変更」が Global に入ると、プロジェクト終了後も残り続けて混乱の原因になる
なぜ3層以上にしないか
Global → Team → Project のような3層設計も考えられますが、実用上は2層が最適です。
- 3層以上になると「どの層に入れるか」の判断コストが高くなる
- Team 層の管理は複数人の同意が必要になり、運用が複雑になる
- Claude Code はファイルを読む際に層の概念を持っていないため、人間側の管理コストだけが増える
- ほとんどの知識は「全プロジェクト共通」か「このプロジェクト固有」かのどちらかに分類できる
チームで共有したい場合は、Global メモリのリポジトリをチームのプライベートリポジトリにして全員がクローンする方法が最もシンプルです。
description の書き方:読まれるメモリ・読まれないメモリ
2層設計で最も見落とされやすいのが MEMORY.md の説明文(description)の品質です。Claude Code はインデックスの説明を見て「このセッションで読む必要があるか」を判断します。説明が曖昧なら余計なメモリを読み込み、具体的なら必要なときだけ読まれます。
悪い description の例
## Feedback - [feedback_misc.md] — Various feedback - [fixes_env.md] — Environment fixes - [reference_stuff.md] — Project references
これらの説明では Claude Code は「このセッションで必要かどうか」を判断できません。結果として常に読まれるか、逆に必要なときに読まれないという二択になります。
良い description の例
## Feedback - [feedback_no_coauthor.md] — Co-Authored-By トレーラーを付けない(明示的に要求された場合のみ付ける) - [feedback_no_comment_bloat.md] — 既存のコメントがない関数にコメントを追加しない。説明ではなく変更された箇所のみコメント - [feedback_concise_response.md] — 応答の末尾に「以上が変更内容です」などの要約を付けない ## Fixes - [fixes_eslint9_flat_config.md] — ESLint 9以降で .eslintrc.js が廃止・flat config(eslint.config.js)への移行方法 - [fixes_nextjs_app_router_params.md] — Next.js 15以降で params が Promise になった変更への対処 - [fixes_pnpm_workspace.md] — pnpm workspace でのパッケージ解決の問題と workaround ## User - [user_profile.md] — スキルレベル・好む説明スタイル・使用ツールの前提知識
良い description の条件を整理します。
| 条件 | 理由 | 例(NG → OK) |
|---|---|---|
| トリガーとなる文脈が明確 | Claude Code がいつ読むべきかを判断できる | 「Misc fixes」→「ESLint 9 で flat config が必要な場合の対処」 |
| 技術的に具体的 | 曖昧な語句では対象範囲が広すぎてノイズになる | 「Environment settings」→「Node.js + pnpm + ESM環境での設定手順」 |
| 副作用が明示されている | 何をやめるか・何を変えるかを description に入れると精度が上がる | 「Co-author settings」→「Co-Authored-By を付けない(要求時のみ付ける)」 |
| バージョン情報を含む(fixesの場合) | 同じ問題でもバージョンによって対処が異なる | 「ESLint fix」→「ESLint 9以降で発生するflat config未設定エラーの修正」 |
description は「未来の Claude Code への検索クエリ」だと考えてください。そのセッションで問題が起きたとき、Claude Code が description を見て「このファイルを読めば解決できる」と判断できる説明文が理想です。
昇格ルール:どの知識をいつ Global に上げるか
2層設計の運用で最も重要かつ難しい判断が「昇格」です。Project メモリの知識を Global に移すタイミングと基準を間違えると、Global が肥大化するか、本来共有すべき知識が埋もれます。
昇格すべき知識の判断基準
Global への昇格は「2つ以上のプロジェクトで同じ問題が再発したとき」を基本的な閾値にします。ただし以下のように種別によって判断が変わります。
| 種別 | 昇格の基準 | 昇格すべきでないケース |
|---|---|---|
feedback |
すべて Global に入れるのが原則。ユーザーの行動規範はプロジェクトによって変わらない | 「このプロジェクトでだけ必要な形式(例:社内特定フォーマット)」はProject |
user |
すべて Global に入れる。スキルレベルや作業スタイルはプロジェクントによって変わらない | —(Project に置く理由がない) |
fixes |
2つ以上のプロジェクトで再発したとき。または使用するツールが同じなら最初から Global | 「このプロジェクトだけ使うフレームワーク固有の問題」はProject(例:社内独自CMSのバグ) |
project |
基本的に昇格しない。期間限定・プロジェクト固有の情報 | —(Global に置く理由がない) |
reference |
全プロジェクトで参照する外部ドキュメントのみ Global | 社内ツール・特定プロジェクトのリンクはProject |
昇格のトリガーを検知する方法
問題は「同じことが別プロジェクトで起きた」という事実に気づかないと昇格のタイミングを逃すことです。以下のパターンで気づけます。
- 同じ fixes の説明を書いた:Project メモリに「これはまたやった」という記憶を加えたとき
- 同じ feedback を繰り返し伝えた:「また Co-Authored-By を付けてきた」と感じたとき
- 別プロジェクトのセットアップ時に同じ指示をした:新規プロジェクトで過去のフィードバックを再入力したとき
これらを感じたら、該当する Project メモリを Global に移動(コピーではなく移動)します。
昇格は一方向:Global → Project には戻さない
Global に昇格したメモリをプロジェクト固有版として Project にコピーすることは避けます。理由はDrift(乖離)です。
Global に「ESLint 9 の flat config 移行」が入っていて、Project にも「このプロジェクトの ESLint 設定」が入っていると、両方を更新しなければならなくなります。一方を更新して他方を忘れると、2つのメモリに矛盾する情報が入り、Claude Code がどちらを信じればいいか分からなくなります。
昇格すべきでない知識の罠
よくある誤りが「汎用的に見える fixes を Global に入れすぎる」ことです。
| 知識の例 | 一見「汎用的」に見えるが… | 正しい判断 |
|---|---|---|
| 「Next.js 16 + ESLint 9 の移行でハマった点」 | Next.js を使わない Python プロジェクトや COBOL プロジェクトには全く無関係 | Next.js を使うプロジェクトのみ Project に置く。複数の Next.js プロジェクトで再発したら Global |
| 「社内の認証APIのエンドポイント」 | 社内特有の情報でチーム外には意味がない | Project の reference 種別に置く |
| 「このスプリントの締め切りは3/31」 | 時限情報でスプリント終了後は不要 | Project に置き、終了後に削除 |
| 「Prettier の設定は2スペース」 | 全プロジェクトで同じルールなら Global。プロジェクトごとに異なるなら Project | Global に入れる前に「本当に全プロジェクト共通か」を確認 |
セットアップ手順:GitHub リポジトリ + CLAUDE.md 設定
GitHub にプライベートリポジトリを作成する
Global メモリを Git で管理するためのリポジトリを作成します。gh CLI(GitHub CLI)を使うと SSH 鍵の設定なしで新しいデバイスでもクローンできます。
# GitHub CLI のインストール(まだの場合) # macOS: brew install gh # Windows: winget install --id GitHub.cli # GitHub CLI でログイン(まだの場合) gh auth login # プライベートリポジトリを作成して ~/.claude/global-memory にクローン gh repo create claude-global-memory --private --clone mv claude-global-memory ~/.claude/global-memory # または既存リポジトリを直接クローン gh repo clone <your-account>/claude-global-memory ~/.claude/global-memory
gh repo clone を使う理由は、gh の認証(GitHub CLI のトークン)をそのまま使えるため、SSH 鍵を別途設定しなくても新しいデバイスで即座にクローンできる点です。新しいデバイスに移ったときは gh auth login と gh repo clone の2コマンドだけで Global メモリが揃います。
初期ファイル構成を作る
cd ~/.claude/global-memory # インデックスファイル touch MEMORY.md # 種別ごとにサブディレクトリは不要(フラットに置く) touch feedback_no_coauthor.md touch feedback_response_style.md touch user_profile.md # Git に追加 git add -A git commit -m "init: global memory structure" git push
MEMORY.md のインデックスを書く
# Global Memory Claude Code がすべてのプロジェクトで参照するグローバルメモリ。 Project 固有の情報はプロジェクト側のメモリに置く。 昇格ルール:同一問題が2プロジェクト以上で再発 → Global に移動(Project からは削除)。 ## User - [user_profile.md] — 開発者のスキルレベル・好む説明スタイル・ツール環境の前提 ## Feedback - [feedback_no_coauthor.md] — Co-Authored-By トレーラーを付けない(明示的に要求された場合のみ) - [feedback_response_style.md] — 応答末尾に要約を付けない・箇条書きは情報が複雑な場合のみ ## Fixes (2プロジェクト以上で再発した fixes のみここに追加する)
個別メモリファイルの書き方
--- name: no-co-authored-by description: Co-Authored-By トレーラーをコミットメッセージに追加しない type: feedback --- コミットメッセージに Co-Authored-By トレーラーを追加しないこと。 ユーザーが明示的に「Co-Authored-By を付けて」と要求した場合のみ追加する。 **Why:** バージョン管理システムの表記ルールに関する好み。 **How to apply:** git commit -m の内容を生成する際に常に適用。
--- name: user-profile description: 開発者のスキルレベル・作業スタイル・ツール前提知識 type: user --- **スキルレベル** - TypeScript/JavaScript: 上級(10年以上) - Python: 中級(業務スクリプト中心) - インフラ/DevOps: 初〜中級 **作業スタイルの好み** - 短く直接的な回答を好む(前置きや言い換えは不要) - 説明よりコードを見せることを好む - 実行したことを事後に長々と説明しない **ツール前提** - パッケージマネージャ: pnpm(npm は使わない) - フォーマッタ: Prettier(tabs=false, singleQuote=true)
~/.claude/CLAUDE.md に読み込み指示を追加する
Claude Code がセッション開始時に Global メモリを参照するよう、グローバルの CLAUDE.md に指示を追加します。
# Global Memory タスク開始時に `~/.claude/global-memory/MEMORY.md` を読み込み、 その内容に基づいて必要な個別メモリファイルをオンデマンドで読む。 昇格ルール:Project メモリの知識が2つ以上のプロジェクトで再発したら `~/.claude/global-memory/` に移動(Project からは削除)する。 逆向き(Global → Project へのコピー)は行わない。
~/.claude/CLAUDE.md は Claude Code のグローバル設定ファイルです。プロジェクトごとの CLAUDE.md とは別物です。このファイルへの記述はすべてのプロジェクトで有効になります。~/.claude/CLAUDE.md が存在しない場合は新規作成します。同期の運用:手動同期と Hooks による自動化
手動同期(最小構成)
最もシンプルな運用は「必要なときだけ手動で同期する」です。
| タイミング | 操作 | 方法 |
|---|---|---|
| 新しいデバイスで初めて作業するとき | Global メモリをクローン | gh repo clone <account>/claude-global-memory ~/.claude/global-memory |
| 別デバイスで Global メモリを更新した後 | 最新の変更を取得 | cd ~/.claude/global-memory && git pull |
| Global メモリに新しい知識を追加した後 | 他デバイスに届ける | git add -A && git commit -m "add: ..." && git push |
Claude に「sync memory」と伝えると、Claude Code が git pull/push を実行します。この程度の手動操作であれば、自動化のコストを掛けなくても十分機能します。
Hooks による自動同期(上級者向け)
Claude Code の Hooks 機能を使うと、セッション開始時に自動で git pull できます。
{
"hooks": {
"SessionStart": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "cd ~/.claude/global-memory && git pull --quiet --rebase 2>/dev/null || true"
}
]
}
]
}
}
末尾の || true はネットワーク接続がないオフライン環境でも Claude Code が起動するようにするためです。git pull に失敗してもセッションはそのまま開始します。
Push の自動化(Stop Hook)については、Global メモリへの追記はセッション中に Claude Code が行うため、Stop Hook で git add -A && git commit && git push を追加することも可能です。ただし意図しない変更が自動コミットされるリスクがあるため、最初は手動 push の運用から始めることを推奨します。
Memory Rot を防ぐ:メモリが腐敗するとどうなるか
“Memory Rot”(メモリの腐敗)は、一度正しかった情報が時間の経過とともに誤りになる現象です。これはメモリシステムを運用するうえで避けられない問題です。
| 腐敗のパターン | 具体例 | 被害 |
|---|---|---|
| バージョンアップによる無効化 | 「Next.js 14では useFormState を使う」→ Next.js 15で useActionState に変更 | Claude Code が古いAPIを使い続ける |
| プロジェクト固有情報の残留 | 「マージフリーズは3/31まで」が期限後も Global に残る | 意味のない制約が全プロジェクトに適用される |
| 矛盾する記憶の蓄積 | 「Prettierを使う」と「ESLintのフォーマット機能を使う」が両方 Global にある | Claude Code がどちらを使えばいいか迷う |
| チームルールの変化 | 「コミットメッセージは英語で」→ チームが日本語運用に変更したが更新忘れ | 古いルールに従ったコミットが生成される |
Memory Rot の予防策
完全に予防することはできませんが、発生を遅らせ、発見を早める仕組みが作れます。
- 個別メモリファイルに作成日を記録する:frontmatter に
created: "2026-03"を追加。6ヶ月以上前のファイルは定期的に見直す - fixes 種別に依存バージョンを明記する:「ESLint 9 で発生」のようにバージョンを description と本文に含める。バージョンアップ時に検索できる
- 月次の棚卸しルーティンを設ける:月に1回、
~/.claude/global-memory/の全ファイルを見直して古いものを削除・更新 - 「このメモリはいつまで有効か」を本文に書く:期限が明確なものは
expires: "2026-03-31"フィールドを使う
---
name: nextjs15-params-promise
description: Next.js 15以降で params が Promise になった変更への対処(searchParams含む)
type: fixes
created: "2026-02"
version-specific: "Next.js 15+"
---
Next.js 15 から `params` と `searchParams` が Promise 型になった。
## 対処
```typescript
// Before (Next.js 14)
export default function Page({ params }: { params: { id: string } }) {}
// After (Next.js 15+)
export default async function Page({ params }: { params: Promise<{ id: string }> }) {
const { id } = await params;
}
```
## 注記
- `page.tsx` だけでなく `layout.tsx` の `params` も同様
- Next.js 14 との互換モードは存在しない
- Next.js 16 以降でこの挙動が変わる場合は本メモリを更新すること
Memory Rot を発見したときの対処
Claude Code が古いメモリに従って間違った出力をしたとき(たとえば廃止された API を使ったとき)、そのまま「これは間違いです」と修正指示を出すだけではなく、必ずメモリファイル自体も更新します。
- 「このメモリは古くなっています。更新してください」と Claude Code に伝える
- Claude Code が該当ファイルを特定・更新する
git add -A && git commit -m "fix: update xxx memory (deprecated api)" && git pushで反映
修正指示だけ出してメモリを更新しないと、次のセッションで同じ間違いが再発します。
auto-memory との役割分担を整理する
Claude Code には組み込みの auto-memory 機能(Projects の Memory 機能)があります。本記事の2層構造設計と auto-memory は補完関係にあり、どちらかを選ぶものではありません。
| auto-memory(組み込み) | 本記事の2層構造 | |
|---|---|---|
| 何が書き込むか | Claude Code が自動的に書き込む | 人間が意図的に書き込む |
| どんな情報 | 会話中に発見したユーザーの好み・プロジェクト状態の短い事実 | ルール・フィードバック・修正知見を構造化したもの |
| 粒度 | 短い箇条書き(1〜3行) | frontmatter + 本文(詳細な説明を含む) |
| 制御 | 自動(Claude が判断) | 手動(人間が設計) |
| 複数デバイス | △(手動コピーが必要) | ✓(Git で同期) |
| 複数プロジェクト共有 | ✗(プロジェクトごとに独立) | ✓(Global 層で共有) |
実践的な使い方は「auto-memory に短い事実の自動蓄積を任せ、重要なルールや繰り返し発生する問題の解決策は2層構造で管理する」という役割分担です。
auto-memory が「このプロジェクトは TypeScript を使う」と自動記録し、2層構造の Global が「TypeScript の Strict モードで ts18046 が出たときの対処」という詳細な知識を管理します。この組み合わせが現時点での最も強力なメモリ管理体制です。
よくある失敗パターンと対処法
実際に2層構造を運用し始めると、以下のような問題に遭遇することがあります。
| 失敗パターン | 症状 | 対処法 |
|---|---|---|
| Global が肥大化する | MEMORY.md が50行を超え、毎回多くのメモリが読み込まれる | Project 固有の情報が混入していないか確認。昇格基準(2プロジェクトで再発)を守る |
| description が曖昧なまま放置 | 「必要なはずの記憶」が参照されない | 説明文が「いつ/なぜ読むか」を明示しているか見直す |
| Global と Project に同じ情報が重複 | どちらが最新か不明になる・Claude Code の出力が不安定 | どちらかを削除。昇格後は Project から必ず削除 |
| memory の更新を忘れる | 間違いが繰り返される | Claude Code に誤りを指摘したとき、必ずメモリの更新も依頼する |
| git push を忘れる | 別デバイスに新しい知識が届かない | Claude に「sync memory」と伝える習慣をつける。または Stop Hook で自動化 |
昇格の具体的なシナリオ:Before / After で見る
抽象的な昇格ルールより、実際のシナリオで理解する方が運用に役立ちます。
シナリオ1:feedback の昇格
最初の React プロジェクトで Claude Code がコミットメッセージに Co-Authored-By を付けてきた。「付けないでください」と伝え、Project メモリに記録された。
| 内容 | |
|---|---|
| Before(Project メモリ) | ~/.claude/projects/xxxx/memory/feedback_coauthor.md「Co-Authored-By を付けない(React プロジェクト)」 |
| 再発 | 2週間後、別の FastAPI プロジェクトでも同じ問題が発生 |
| After(Global メモリへ昇格) | ~/.claude/global-memory/feedback_no_coauthor.md「Co-Authored-By を付けない(すべてのプロジェクト)」 React プロジェクトの Project メモリからは削除 |
この昇格で「React プロジェクト限定のルール」が「全プロジェクト共通のルール」に格上げされました。以降はすべてのプロジェクトで Co-Authored-By が自動的に省略されます。
シナリオ2:fixes の昇格判断(昇格すべき vs すべきでない)
2つの fixes が Project に入っていたとします。どちらを昇格すべきか考えます。
| fixes の内容 | 昇格すべきか | 理由 |
|---|---|---|
| 「ESLint 9 で .eslintrc.js が動かない → flat config に移行」 | ✓ 昇格すべき | 別の Next.js プロジェクトでも ESLint 9 を使う可能性が高く、同じ問題が再発する |
| 「社内 CMS の画像パスが /storage/xxxx/ 形式でないと表示されない」 | ✗ 昇格しない | 社内 CMS 固有の仕様であり、他のプロジェクトには全く関係ない |
判断のポイントは「このツール・ライブラリを他のプロジェクトでも使うか?」です。汎用ツール(ESLint・Prettier・TypeScript等)の問題は Global 候補になり、プロジェクト固有のシステムの問題は Project のままにします。
シナリオ3:project 種別は昇格しない
Project メモリに「スプリント3のマージフリーズは3/31まで」という project 種別のエントリがありました。4月になっても削除されず残っていました。
この種別は絶対に Global に昇格しません。そもそも期限が過ぎたら Project から削除するのが正しい対応です。project 種別のファイルは定期的に見直し、有効期限が切れたものを積極的に削除します。
Global メモリの実践的なサンプル集
実際にどんな内容を Global メモリに入れるかのサンプルです。自分の環境に合わせてカスタマイズしてください。
feedback 種別のサンプル
--- name: response-style description: 応答スタイルの指針(前置き・要約・箇条書きに関するルール) type: feedback created: "2026-01" --- **やめること** - 回答の冒頭で「承知しました」「もちろんです」などの肯定フレーズを使わない - 実行した内容を末尾に長々と再説明しない(diff を見れば分かる) - 単純な質問に箇条書きで回答しない(複雑な内容の場合のみ使う) - 見出し・絵文字を過剰に使わない **やること** - 答えから始める(理由・背景は後で) - コードで示せる場合はコードを先に見せる - ファイル・関数への参照は `file:line` 形式で
--- name: no-docstring-bloat description: 変更していない関数にコメント・docstring を追加しない type: feedback created: "2026-02" --- 変更していないコードにコメントや docstring を追加しないこと。 **理由:** 「改善」として追加されたコメントが意図しない diff を作り、 コードレビューの際にノイズになった実績がある。 **How to apply:** - ファイルを編集する際、変更箇所以外のコメントを追加・修正しない - 「このコードを分かりやすくするためにコメントを追加しました」はやらない - ユーザーが明示的にコメント追加を依頼した場合のみ対応
fixes 種別のサンプル(複数プロジェクトで再発した例)
---
name: eslint9-flat-config
description: ESLint 9 以降で .eslintrc.js が廃止・flat config への移行(eslint.config.js)
type: fixes
created: "2026-01"
version-specific: "ESLint 9+"
---
## 症状
`eslint` 実行時に `.eslintrc.js` が無視される、または
`ESLint couldn't find the config file` エラーが出る。
## 原因
ESLint 9 から `.eslintrc.*` 形式が廃止され、
flat config(`eslint.config.js`)が必須になった。
## 対処
```javascript
// eslint.config.js(プロジェクトルートに作成)
import js from "@eslint/js";
import globals from "globals";
export default [
js.configs.recommended,
{
languageOptions: {
globals: {
...globals.browser,
...globals.node,
},
},
rules: {
// プロジェクト固有のルールはここに追加
},
},
];
```
## TypeScript プロジェクトの場合
```javascript
import tseslint from "typescript-eslint";
export default tseslint.config(
...tseslint.configs.recommended,
);
```
## 注記
- `eslint-plugin-*` 系のプラグインも flat config 対応版に更新が必要な場合がある
- ESLint 8 との後方互換モード(`ESLINT_USE_FLAT_CONFIG=false`)は ESLint 10 で廃止予定
user 種別のサンプル
--- name: user-profile description: 開発者プロフィール・スキルレベル・ツール設定の前提知識 type: user created: "2026-01" --- ## 経験・スキル - JavaScript/TypeScript: 上級(10年以上・フロントエンド〜バックエンド) - Python: 中級(スクリプト・自動化・データ処理) - Go: 基礎レベル(読める・書けるが深い知識なし) - SQL/Oracle: 上級(PL/SQL・チューニング経験あり) ## 作業スタイル - 高度な内容は前置きなしで話せる(基本的な説明は不要) - 短く直接的な回答を好む - 「なぜ」より「どうする」を先に教えてほしい - コードで示せるなら文章より先にコードを見せる ## ツール環境 - OS: Windows 11(WSL2 併用)・macOS(MacBook Pro) - エディタ: VS Code + Claude Code - パッケージマネージャ: pnpm(npm は使わない) - フォーマッタ: Prettier(tabs=false, singleQuote=true, semi=false) - バージョン管理: Git(コミットメッセージは日本語可)
実践的な運用フロー:日常の使い方
設計が完成したら、日常の Claude Code 利用でどう動くかを確認します。
新規プロジェクトを始めるとき
- Claude Code を開く → SessionStart で Global メモリを git pull(Hooks 設定済みの場合は自動)
- プロジェクト固有の CLAUDE.md を作成して技術スタック・制約を記載
- セッション中に出てきた Project 固有の知識は Project メモリに Claude Code が自動的に追加
別デバイスに切り替えるとき
gh auth login(初回のみ)gh repo clone <account>/claude-global-memory ~/.claude/global-memory- Claude Code を開く → Global メモリが即座に有効
同じ問題が別プロジェクトで再発したとき
- 「このメモリを Global に昇格してください」と Claude Code に伝える
- Claude Code が該当ファイルを
~/.claude/global-memory/に移動し MEMORY.md を更新 - Project メモリから該当エントリを削除
cd ~/.claude/global-memory && git add -A && git commit -m "promote: ..." && git push
よくある質問
~/.claude/global-memory にクローンします。ただし全員が自由に書き込めるため、品質管理のためにプルリクエストによるレビューを導入するか、特定の管理者だけが push できるルールを設けると安定します。まとめ:設計することで Claude Code は”賢くなり続ける”
本記事のポイントを整理します。
| 設計の要素 | 内容 |
|---|---|
| 2層の目的 | Global = すべてのプロジェクトで共通の知識、Project = プロジェクト固有の文脈 |
| Global に入れるもの | feedback(行動規範)・user(スキル・好み)・横断的なfixes |
| Project に入れるもの | project(期間限定状態)・reference(外部リンク)・固有のfixes |
| 昇格の基準 | 2プロジェクト以上で同じ問題が再発したとき。昇格は一方向(Project → Global のみ) |
| description の書き方 | いつ/なぜ読むかが明確に分かる具体的な説明文 |
| Memory Rot 対策 | バージョン情報の記載・月次棚卸し・修正時にメモリも更新 |
| 同期 | GitHub プライベートリポジトリ + gh CLI + Hooks(任意) |
Claude Code は使えば使うほど賢くなるポテンシャルを持っています。しかし設計なしにフィードバックを与え続けると、すぐに分断・重複・腐敗が起きます。メモリを設計することが、Claude Code を本当の意味で育てるということです。auto-memory と本設計を組み合わせ、Hooks で自動化を加えれば、セッションをまたいでもデバイスをまたいでも、一貫した知識を持った AI として機能し続けます。