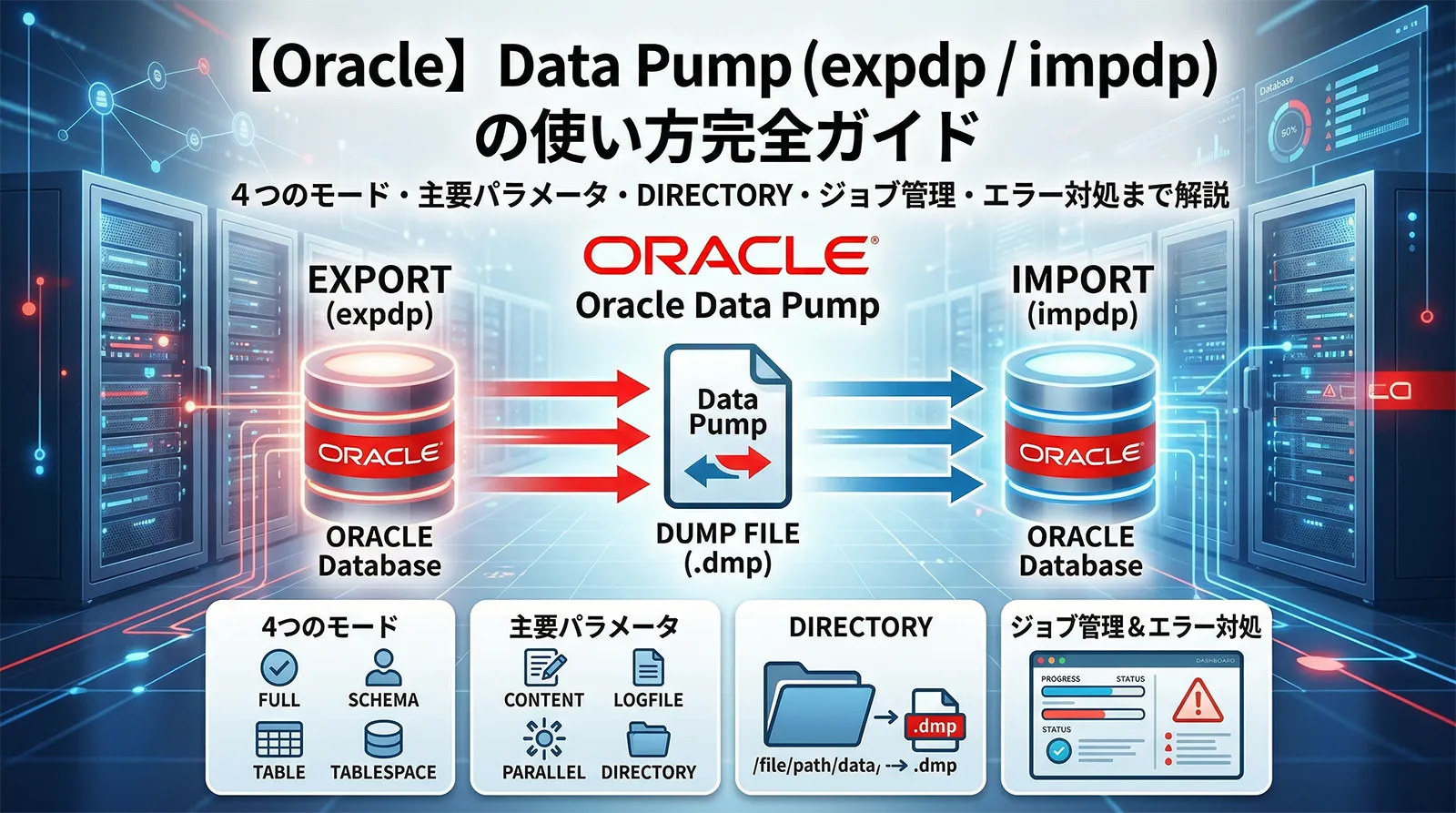
Oracle の Data Pump(expdp / impdp)は、テーブル・スキーマ・データベース全体のエクスポート/インポートを高速に行うツールです。旧来の exp / imp に代わり、Oracle 10g 以降の標準ツールとして位置づけられています。
本記事では、Data Pump の基本概念と前提準備、4 つのエクスポート/インポートモード、主要パラメータの一覧、parfile の書き方、ジョブの管理操作、そしてよくあるエラーと対処法まで体系的に解説します。
この記事でわかること
・Data Pump の概要と旧 exp/imp との違い
・DIRECTORY オブジェクトの作成と権限付与
・expdp の 4 モード(テーブル / スキーマ / フル / 表領域)
・impdp の基本構文と table_exists_action
・expdp / impdp の主要パラメータ一覧表
・parfile の書き方
・ジョブの進捗確認・一時停止・再開・強制停止
・よくあるエラーと対処法
・Data Pump の概要と旧 exp/imp との違い
・DIRECTORY オブジェクトの作成と権限付与
・expdp の 4 モード(テーブル / スキーマ / フル / 表領域)
・impdp の基本構文と table_exists_action
・expdp / impdp の主要パラメータ一覧表
・parfile の書き方
・ジョブの進捗確認・一時停止・再開・強制停止
・よくあるエラーと対処法
Data Pump とは
| 項目 | Data Pump(expdp / impdp) | 旧ツール(exp / imp) |
|---|---|---|
| 利用可能バージョン | Oracle 10g 以降 | 全バージョン(非推奨) |
| 処理速度 | 高速(サーバー側で実行) | 低速(クライアント側で実行) |
| パラレル処理 | 対応(parallel パラメータ) | 非対応 |
| ダンプファイルの場所 | サーバー上の DIRECTORYのみ | クライアントでもサーバーでも可 |
| ジョブ管理 | 対応(一時停止 / 再開 / attach) | 非対応 |
| 圧縮 | 対応(compression パラメータ) | 非対応 |
| フィルタリング | EXCLUDE / INCLUDE / QUERY | テーブル指定のみ |
前提準備:DIRECTORY の作成と権限付与
Data Pump はダンプファイルをサーバー上のディレクトリに書き出します。事前に DIRECTORY オブジェクトを作成し、ユーザーに権限を付与する必要があります。
SQL(DIRECTORY の作成と権限付与)
-- (1) OS 上にディレクトリを作成(oracle ユーザーで実行) -- $ mkdir -p /oracle/dpdir -- $ chown oracle:oinstall /oracle/dpdir -- (2) DIRECTORY オブジェクトを作成(SYS / DBA で実行) CREATE OR REPLACE DIRECTORY dp_dir AS '/oracle/dpdir'; -- (3) ユーザーに READ / WRITE 権限を付与 GRANT READ, WRITE ON DIRECTORY dp_dir TO hr; -- 既存の DIRECTORY を確認 SELECT directory_name, directory_path FROM dba_directories ORDER BY 1; -- デフォルト DIRECTORY(DATA_PUMP_DIR)の確認 SELECT directory_path FROM dba_directories WHERE directory_name = 'DATA_PUMP_DIR';
DIRECTORY のパスはサーバー上の実パス
DIRECTORY はクライアント側ではなくDB サーバー上のパスを指定します。OS ユーザー(oracle)に読み書き権限があることを確認してください。Windows の場合は
DIRECTORY はクライアント側ではなくDB サーバー上のパスを指定します。OS ユーザー(oracle)に読み書き権限があることを確認してください。Windows の場合は
C:\oracle\dpdir のように指定します。expdp(エクスポート)の 4 モード
モード(1): テーブルモード(tables=)
Shell(テーブルエクスポート)
# 特定テーブルのみエクスポート
expdp hr/password \
directory=DP_DIR \
dumpfile=emp_export.dmp \
logfile=emp_export.log \
tables=HR.EMPLOYEES,HR.DEPARTMENTS
モード(2): スキーマモード(schemas=)
Shell(スキーマエクスポート)
# スキーマ全体をエクスポート
expdp system/password \
directory=DP_DIR \
dumpfile=hr_schema.dmp \
logfile=hr_schema.log \
schemas=HR
モード(3): フルモード(full=y)
Shell(データベース全体エクスポート)
# データベース全体をエクスポート(DBA 権限が必要)
expdp system/password \
directory=DP_DIR \
dumpfile=full_export_%U.dmp \
logfile=full_export.log \
full=y \
parallel=4
# %U: パラレル時にファイルを自動分割(01, 02, ...)
モード(4): 表領域モード(tablespaces=)
Shell(表領域エクスポート)
# 特定の表領域をエクスポート
expdp system/password \
directory=DP_DIR \
dumpfile=users_ts.dmp \
logfile=users_ts.log \
tablespaces=USERS
| モード | パラメータ | 対象 | 必要な権限 |
|---|---|---|---|
| テーブル | tables=SCHEMA.TABLE | 指定テーブルのみ | テーブルの所有者 or EXP_FULL_DATABASE |
| スキーマ | schemas=SCHEMA | スキーマ内の全オブジェクト | 自スキーマ or EXP_FULL_DATABASE |
| フル | full=y | データベース全体 | EXP_FULL_DATABASE(DBA 権限) |
| 表領域 | tablespaces=TS_NAME | 指定表領域の全オブジェクト | EXP_FULL_DATABASE |
impdp(インポート)の基本
Shell(impdp 基本パターン)
# テーブル単位のインポート
impdp hr/password \
directory=DP_DIR \
dumpfile=emp_export.dmp \
logfile=emp_import.log \
tables=HR.EMPLOYEES \
table_exists_action=REPLACE
# スキーマ全体のインポート
impdp system/password \
directory=DP_DIR \
dumpfile=hr_schema.dmp \
logfile=hr_import.log \
schemas=HR
# 別スキーマにインポート(REMAP_SCHEMA)
impdp system/password \
directory=DP_DIR \
dumpfile=hr_schema.dmp \
logfile=remap_import.log \
remap_schema=HR:TEST_HR
| table_exists_action | 動作 | 適するケース |
|---|---|---|
| SKIP(デフォルト) | テーブルが存在すればスキップ | 既存データを保護 |
| REPLACE | DROP して再作成 | 完全な置き換え |
| APPEND | 既存テーブルにデータを追加 | 差分データの投入 |
| TRUNCATE | TRUNCATE してからデータを投入 | テーブル構造を維持してデータ入れ替え |
table_exists_action の詳細は「ORA-31684 完全解説」、データだけのインポートは「impdp でデータだけをインポートする方法」を参照してください。
主要パラメータ一覧
expdp / impdp 共通パラメータ
| パラメータ | 説明 | 例 |
|---|---|---|
| directory | DIRECTORY オブジェクト名 | directory=DP_DIR |
| dumpfile | ダンプファイル名(%U でパラレル分割) | dumpfile=backup_%U.dmp |
| logfile | ログファイル名 | logfile=export.log |
| parallel | パラレル度(並列プロセス数) | parallel=4 |
| content | DATA_ONLY / METADATA_ONLY / ALL | content=DATA_ONLY |
| exclude | 除外するオブジェクト | exclude=INDEX,CONSTRAINT |
| include | 含めるオブジェクト | include=TABLE |
| parfile | パラメータファイルのパス | parfile=export.par |
| job_name | ジョブ名(管理用) | job_name=MY_EXPORT |
expdp 固有パラメータ
| パラメータ | 説明 | 例 |
|---|---|---|
| tables | テーブル指定 | tables=HR.EMPLOYEES,HR.DEPARTMENTS |
| schemas | スキーマ指定 | schemas=HR,SCOTT |
| full | フルエクスポート | full=y |
| tablespaces | 表領域指定 | tablespaces=USERS |
| query | WHERE 条件でフィルタ | query=HR.EMPLOYEES:\”WHERE salary>5000\” |
| compression | 圧縮 | compression=ALL |
| flashback_time | 一貫性のある時点指定 | flashback_time=\”TO_TIMESTAMP(…)\” |
| version | 下位バージョン互換 | version=12.2 |
impdp 固有パラメータ
| パラメータ | 説明 | 例 |
|---|---|---|
| table_exists_action | 既存テーブルの処理 | table_exists_action=REPLACE |
| remap_schema | スキーマの変更 | remap_schema=HR:TEST_HR |
| remap_tablespace | 表領域の変更 | remap_tablespace=USERS:TEST_TS |
| remap_table | テーブル名の変更 | remap_table=HR.EMP:HR.EMP_BK |
| sqlfile | インポートせずDDLを出力 | sqlfile=ddl_output.sql |
| transform | DDL変換 | transform=SEGMENT_ATTRIBUTES:N |
parfile の書き方
parfile(export_daily.par)
# Data Pump エクスポート用 parfile directory=DP_DIR dumpfile=hr_daily_%U.dmp logfile=hr_daily.log schemas=HR parallel=4 compression=ALL exclude=STATISTICS
Shell(parfile を使った実行)
expdp hr/password parfile=/oracle/dpdir/export_daily.par
parfile を使うメリット
・コマンドラインが短くなる(長いパラメータを整理)
・スケジュール実行(cron / タスクスケジューラ)に組み込みやすい
・バージョン管理(Git 等)でパラメータの変更履歴を追跡できる
・QUERY パラメータのクォート問題を回避しやすい
・コマンドラインが短くなる(長いパラメータを整理)
・スケジュール実行(cron / タスクスケジューラ)に組み込みやすい
・バージョン管理(Git 等)でパラメータの変更履歴を追跡できる
・QUERY パラメータのクォート問題を回避しやすい
ジョブの管理(進捗確認・一時停止・再開・強制停止)
Shell(ジョブ管理操作)
# 実行中のジョブに接続(attach) expdp hr/password attach=MY_EXPORT # 接続後の対話モードで使えるコマンド: # STATUS -- 進捗状況を表示 # STATUS=60 -- 60 秒ごとに進捗を自動表示 # STOP_JOB=IMMEDIATE -- ジョブを即時停止(再開可能) # START_JOB -- 停止したジョブを再開 # KILL_JOB -- ジョブを強制終了(再開不可) # PARALLEL=8 -- パラレル度を動的に変更
SQL(ジョブの状態を SQL で確認)
-- 実行中 / 停止中の Data Pump ジョブを確認 SELECT owner_name, job_name, operation, job_mode, state FROM dba_datapump_jobs WHERE state <> 'NOT RUNNING' ORDER BY owner_name; -- 終了したジョブのマスターテーブルを削除(不要なら) -- DROP TABLE hr.SYS_EXPORT_TABLE_01 PURGE;
KILL_JOB と STOP_JOB の違い
・
・
・
STOP_JOB: ジョブを一時停止します。後で START_JOB で再開できます・
KILL_JOB: ジョブを強制終了します。再開はできません。ダンプファイルも不完全な状態で残りますよくあるエラーと対処法
| エラー | 原因 | 対処法 |
|---|---|---|
| ORA-31684 オブジェクトが既存 |
impdp でテーブルが既に存在する | table_exists_action=REPLACE または REMAP_TABLE で別名インポート |
| ORA-39002 操作が無効 |
DIRECTORY への READ/WRITE 権限がない | GRANT READ, WRITE ON DIRECTORY dp_dir TO user |
| ORA-39166 オブジェクトが見つからない |
.dmp に指定テーブルが含まれていない | impdp … sqlfile=check.sql で内容を確認 |
| ORA-31626 ジョブが存在しない |
マスターテーブルが残存している | DROP TABLE schema.SYS_EXPORT_xxx PURGE |
| ORA-39001 引数が無効 |
DIRECTORY パスが存在しない or 権限不足 | OS ディレクトリの存在と oracle ユーザーの権限を確認 |
| ORA-31693 + ORA-02291 外部キー制約違反 |
インポート順序で参照先テーブルが未作成 | EXCLUDE=CONSTRAINT で制約を除外してインポート後に追加 |
Data Pump 関連記事リンク集
| テーマ | 記事 |
|---|---|
| テーブル単位のバックアップ | 指定テーブルのみバックアップを取る方法 |
| テーブル単位のリストア | 指定テーブルのみリストアする方法 |
| バックアップの高速化 | バックアップを高速化する方法 |
| WHERE 条件付きエクスポート | expdp で WHERE 句(query)を使う方法 |
| 複数テーブルのエクスポート | Data Pump で複数テーブルをまとめてエクスポート |
| ORA-31684 対処 | ORA-31684 完全解説 |
| データだけインポート | impdp でデータだけをインポートする方法 |
| パラレル処理 | Data Pump のパラレル処理で高速化 |
| スキーマ単位 | スキーマごとにエクスポート・インポート |
| 表領域単位 | 表領域単位に expdp/impdp する方法 |
| 圧縮 | エクスポート時に圧縮する方法 |
| バージョン互換 | バージョンが違う DB での注意点 |
| 特定テーブル除外 | リストア時に特定テーブルを除外する方法 |
| インポートが終わらない | impdp が終わらない原因と対処法 |
よくある質問
Qexp / imp はもう使えませんか?
AOracle 12c 以降でも exp / imp は残っていますが非推奨です。Data Pump の方が高速で機能も豊富なため、新規開発では必ず expdp / impdp を使ってください。exp / imp は将来のバージョンでサポートが終了する可能性があります。
Qダンプファイルをクライアント側に出力できますか?
AData Pump のダンプファイルはサーバー上の DIRECTORY のみに出力されます。クライアントに転送するには、エクスポート後に scp / sftp でファイルをコピーしてください。旧 exp はクライアント側に出力可能でしたが、Data Pump ではこの制約があります。
Qパスワードをコマンドラインに書きたくないのですが
A方法は 3 つあります。
(1) OS 認証:
(2) パスワードファイル: Oracle Wallet を使用
(3) parfile にパスワードを記述し、parfile のパーミッションを制限
(1) OS 認証:
expdp / as sysdba(/ で接続)(2) パスワードファイル: Oracle Wallet を使用
(3) parfile にパスワードを記述し、parfile のパーミッションを制限
Qparfile と query パラメータでクォートがうまくいきません
Aquery パラメータのクォートは OS によって異なります。
parfile に書く場合が最もトラブルが少ないです。
詳細は「expdp で WHERE 句を使う方法」を参照してください。
parfile に書く場合が最もトラブルが少ないです。
query=HR.EMPLOYEES:"WHERE salary > 5000"詳細は「expdp で WHERE 句を使う方法」を参照してください。
Qエクスポート中にデータが変更されると不整合が起きますか?
Aデフォルトでは各テーブルごとに一貫性が保たれますが、テーブル間の一貫性は保証されません。テーブル間の一貫性も必要な場合は
flashback_time または flashback_scn パラメータで特定時点のスナップショットをエクスポートしてください。QData Pump のジョブが残っていて次のエクスポートができません
A
DBA_DATAPUMP_JOBS で残存ジョブを確認し、マスターテーブル(SYS_EXPORT_xxx)を DROP してください。SELECT owner_name, job_name, state FROM dba_datapump_jobs;DROP TABLE hr.SYS_EXPORT_TABLE_01 PURGE;まとめ
Data Pump の要点をまとめます。
| やりたいこと | コマンド / パラメータ |
|---|---|
| 特定テーブルのエクスポート | expdp … tables=SCHEMA.TABLE |
| スキーマ全体のエクスポート | expdp … schemas=SCHEMA |
| データベース全体のエクスポート | expdp … full=y |
| パラレルで高速化 | parallel=N + dumpfile=file_%U.dmp |
| 特定テーブルのインポート | impdp … tables=SCHEMA.TABLE |
| 既存テーブルを置き換えてインポート | impdp … table_exists_action=REPLACE |
| 別スキーマにインポート | impdp … remap_schema=OLD:NEW |
| データだけインポート | impdp … content=DATA_ONLY |
| 実行中のジョブに接続 | expdp … attach=JOB_NAME |
| .dmp の内容を確認(インポートせず) | impdp … sqlfile=check.sql |