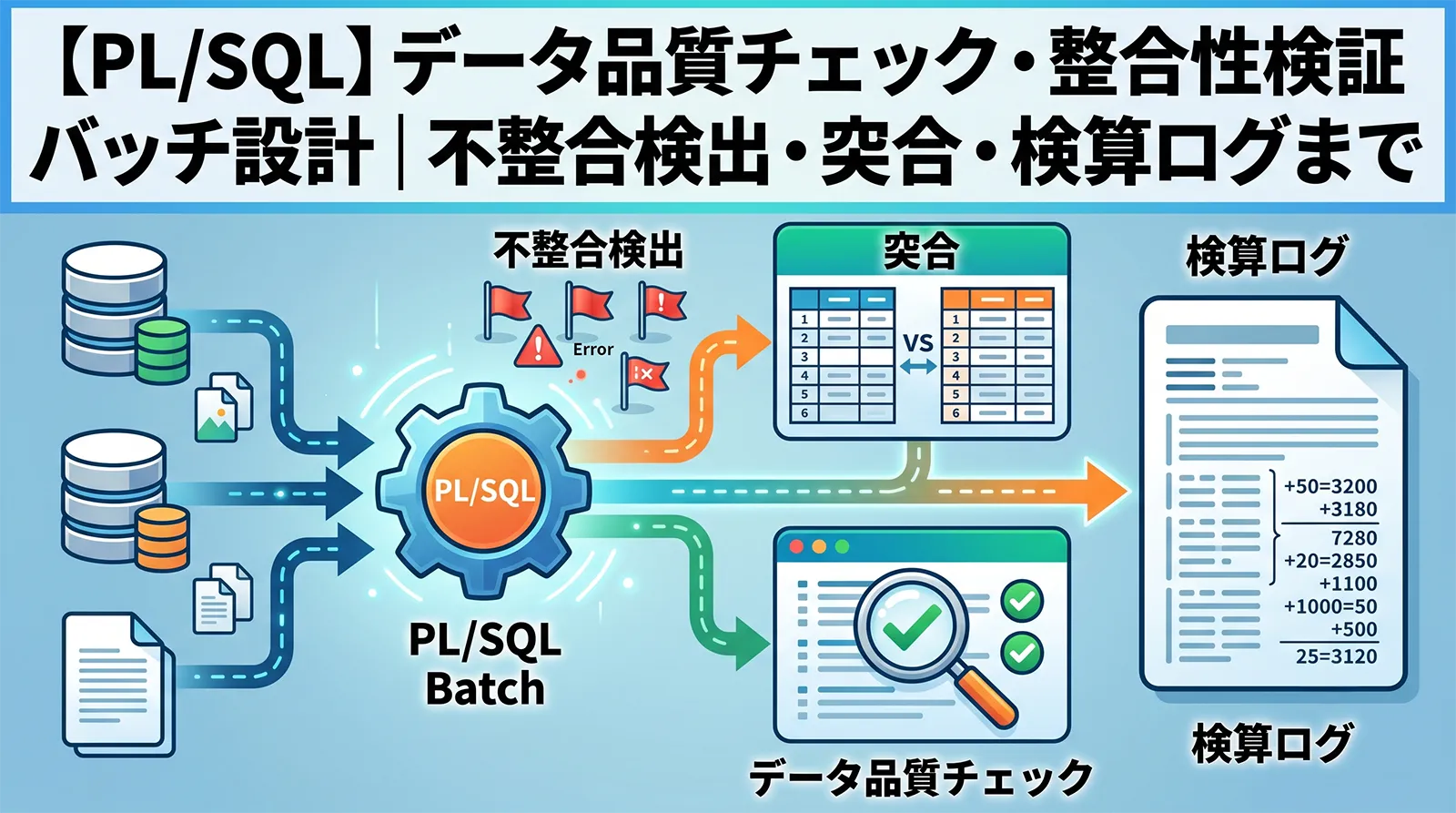
バッチが正常終了していても、データが正しいとは限りません。NULLであってはいけない列がNULLになっている、マスタに存在しないコードが明細に入っている、売上と入金が一致しない、サマリーと明細の金額がずれている。こうした不整合は、画面や帳票で問題が出てから気づくと調査が大変です。
この記事では、PL/SQLでデータ品質チェック・整合性検証バッチを設計する方法を整理します。単発の検算SQLではなく、検証ルール、検出結果、しきい値、ジョブ失敗判定、再実行までを運用できる形にします。ステージング取込の検証は ステージングテーブル設計、サマリー検算は サマリーテーブル・集計バッチ設計 と組み合わせると効果的です。
- データ品質チェックが必要になる場面
- NULL、重複、参照不整合、金額差異、件数差異の検出
- 検証ルールテーブルの設計
- 不整合検出結果テーブルの設計
- マスタと明細の突合
- 売上と入金の検算
- しきい値によるジョブ失敗判定
- 検証ログと再実行
データ品質チェックが必要になる場面
データ品質チェックは、取込や集計の最後にだけ行うものではありません。外部連携後、マスタ同期後、補正作業後、サマリー作成後、月次締め前など、データを次の工程へ渡す境界で実行すると効果があります。データの正しさを人の目視確認に頼ると、件数が増えたときに破綻します。
本番データ補正後の検証は 本番データ補正スクリプトの作り方、マスタ同期後の検証は マスタ同期・履歴管理の設計 とつながります。
チェック種別を分類する
データ品質チェックは、ルールを分類しておくと管理しやすくなります。毎回SQLを手書きするのではなく、チェック種別、重要度、しきい値、対象期間を決めます。
分類しておくと、致命的なエラーはジョブ失敗、軽微な警告は通知だけ、という運用ができます。
検証ルールテーブルを設計する
検証ルールをテーブル化しておくと、どのチェックをいつ実行するか、失敗扱いにするか、しきい値はいくつかを管理できます。SQL本文まで完全にテーブル化すると運用が難しくなることもあるため、まずはルールID、種別、重要度、しきい値、説明を管理する形が扱いやすいです。
CREATE TABLE data_quality_rule (
rule_id VARCHAR2(100) PRIMARY KEY,
rule_name VARCHAR2(200) NOT NULL,
target_name VARCHAR2(100) NOT NULL,
check_type VARCHAR2(30) NOT NULL,
severity VARCHAR2(20) NOT NULL,
fail_threshold NUMBER DEFAULT 1 NOT NULL,
enabled CHAR(1) DEFAULT 'Y' NOT NULL,
description VARCHAR2(1000),
updated_at TIMESTAMP DEFAULT SYSTIMESTAMP NOT NULL,
CONSTRAINT ck_dq_rule_type
CHECK (check_type IN ('REQUIRED','DUPLICATE','REFERENCE','AMOUNT','COUNT','BUSINESS')),
CONSTRAINT ck_dq_rule_severity
CHECK (severity IN ('ERROR','WARN')),
CONSTRAINT ck_dq_rule_enabled
CHECK (enabled IN ('Y','N'))
);
fail_thresholdは、何件以上検出したら失敗扱いにするかです。必須項目漏れは1件でも失敗、金額差異は0円以外なら失敗、警告系は100件までは通知だけ、というように使えます。
検出結果テーブルを設計する
不整合を検出したら、結果をテーブルに残します。ログに文字列で出すだけでは、後から検索、再処理、担当者への連携がしにくくなります。検出結果には、バッチID、ルールID、対象キー、差異値、メッセージを持たせます。
CREATE TABLE data_quality_result ( result_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY, batch_id NUMBER NOT NULL, rule_id VARCHAR2(100) NOT NULL, target_key VARCHAR2(300), detected_value VARCHAR2(1000), expected_value VARCHAR2(1000), difference_value NUMBER, message VARCHAR2(2000), detected_at TIMESTAMP DEFAULT SYSTIMESTAMP NOT NULL ); CREATE INDEX ix_dq_result_batch_rule ON data_quality_result(batch_id, rule_id);
対象キーは、注文ID、商品コード、取引先コード、日付などを連結して入れます。後続で再処理したい場合は、対象テーブル名や主キー列を分けて持つ設計も有効です。
必須項目漏れを検出する
最も基本的なチェックは、必須項目のNULL検出です。ステージングやマスタ、明細でNULLを許さない列に値が入っているか確認します。
INSERT INTO data_quality_result (
batch_id,
rule_id,
target_key,
detected_value,
message
)
SELECT
:batch_id,
'ORDER_REQUIRED_COLUMNS',
'order_id=' || order_id,
'customer_id=' || NVL(TO_CHAR(customer_id), 'NULL')
|| ', order_date=' || NVL(TO_CHAR(order_date, 'YYYY-MM-DD'), 'NULL'),
'注文の必須項目が不足しています。'
FROM orders
WHERE order_date >= :from_date
AND order_date < :to_date
AND (
customer_id IS NULL
OR order_date IS NULL
OR order_status IS NULL
);
必須チェックは単純ですが、検出結果にどの列が不足しているかを残すと調査が速くなります。対象期間を固定して実行する点は、差分抽出や集計バッチと同じです。
重複キーを検出する
一意であるべきキーが重複していると、後続のMERGEや集計で想定外の結果になります。ステージングに同じコードが複数行入っていないか、注文番号が重複していないかをチェックします。
INSERT INTO data_quality_result ( batch_id, rule_id, target_key, detected_value, message ) SELECT :batch_id, 'STG_ITEM_DUPLICATE', item_code, 'count=' || COUNT(*), '同一バッチ内で商品コードが重複しています。' FROM stg_item_master WHERE batch_id = :source_batch_id GROUP BY item_code HAVING COUNT(*) > 1;
重複チェックは、マスタ同期やステージング取込の前段で特に重要です。同じキーが複数ある状態でSCD Type 2やMERGEを実行すると、履歴や現行行が壊れる可能性があります。
マスタと明細を突合する
参照整合性チェックでは、明細に入っているコードがマスタに存在するか、取引日時点で有効かを確認します。外部キー制約だけでは、有効期間までチェックできないことがあります。
INSERT INTO data_quality_result (
batch_id,
rule_id,
target_key,
detected_value,
message
)
SELECT
:batch_id,
'ORDER_ITEM_MASTER_REFERENCE',
'order_id=' || d.order_id || ', item_code=' || d.item_code,
d.item_code,
'注文日時点で有効な商品マスタが存在しません。'
FROM orders o
JOIN order_details d
ON d.order_id = o.order_id
WHERE o.order_date >= :from_date
AND o.order_date < :to_date
AND NOT EXISTS (
SELECT 1
FROM item_master_hist m
WHERE m.item_code = d.item_code
AND o.order_date >= m.valid_from
AND o.order_date < m.valid_to
);
このような有効期間つき参照チェックは、履歴マスタを使うシステムで重要です。マスタ履歴の設計は マスタ同期・履歴管理の設計 と合わせて確認してください。
売上と入金を検算する
金額系の検算では、売上、請求、入金、返金の差異を集計して検出します。明細単位で完全一致する場合もあれば、日別・請求単位で合計一致を確認する場合もあります。
WITH sales AS (
SELECT
invoice_no,
SUM(amount) AS sales_amount
FROM sales_detail
WHERE sales_date >= :from_date
AND sales_date < :to_date
GROUP BY invoice_no
),
payment AS (
SELECT
invoice_no,
SUM(payment_amount) AS payment_amount
FROM payment_detail
WHERE payment_date >= :from_date
AND payment_date < :to_date
GROUP BY invoice_no
)
INSERT INTO data_quality_result (
batch_id,
rule_id,
target_key,
detected_value,
expected_value,
difference_value,
message
)
SELECT
:batch_id,
'SALES_PAYMENT_RECONCILE',
NVL(s.invoice_no, p.invoice_no),
TO_CHAR(NVL(p.payment_amount, 0)),
TO_CHAR(NVL(s.sales_amount, 0)),
NVL(p.payment_amount, 0) - NVL(s.sales_amount, 0),
'売上金額と入金金額に差異があります。'
FROM sales s
FULL OUTER JOIN payment p
ON p.invoice_no = s.invoice_no
WHERE ABS(NVL(p.payment_amount, 0) - NVL(s.sales_amount, 0)) > 0;
金額検算では、丸めや税計算の扱いを決めておきます。1円未満の丸め差を許容する場合は、ABS(diff) > 1のようにしきい値を持たせます。許容差を曖昧にすると、毎回同じ警告が出続けて誰も見なくなります。
サマリーテーブルと明細を検算する
サマリーテーブルを使っている場合は、明細から再集計した値とサマリーの値を突合します。サマリーが速くても、元データとズレていれば業務数字として信用できません。
WITH detail_sum AS (
SELECT
TRUNC(o.order_date) AS summary_date,
o.store_id,
d.item_id,
SUM(d.amount) AS detail_amount,
COUNT(*) AS detail_rows
FROM orders o
JOIN order_details d
ON d.order_id = o.order_id
WHERE o.order_date >= :from_date
AND o.order_date < :to_date
GROUP BY TRUNC(o.order_date), o.store_id, d.item_id
)
INSERT INTO data_quality_result (
batch_id,
rule_id,
target_key,
detected_value,
expected_value,
difference_value,
message
)
SELECT
:batch_id,
'SALES_SUMMARY_RECONCILE',
TO_CHAR(NVL(d.summary_date, s.summary_date), 'YYYY-MM-DD')
|| ':store=' || NVL(TO_CHAR(d.store_id), TO_CHAR(s.store_id))
|| ':item=' || NVL(TO_CHAR(d.item_id), TO_CHAR(s.item_id)),
TO_CHAR(NVL(s.sales_amount, 0)),
TO_CHAR(NVL(d.detail_amount, 0)),
NVL(s.sales_amount, 0) - NVL(d.detail_amount, 0),
'明細合計とサマリー金額に差異があります。'
FROM detail_sum d
FULL OUTER JOIN sales_daily_summary s
ON s.summary_date = d.summary_date
AND s.store_id = d.store_id
AND s.item_id = d.item_id
WHERE NVL(s.sales_amount, 0) <> NVL(d.detail_amount, 0);
サマリー検算は、集計バッチの最後だけでなく、締め前や補正後にも実行できるようにしておくと便利です。集計バッチ側の設計は サマリーテーブル・集計バッチ設計 で詳しく扱っています。
しきい値でジョブ失敗を判定する
チェック結果を残すだけでは、運用上は弱いです。致命的な不整合が出た場合は、ジョブを失敗扱いにして後続処理を止める必要があります。一方で、警告系は通知だけにしたい場合もあります。
SELECT r.rule_id, r.severity, r.fail_threshold, COUNT(q.result_id) AS detected_count FROM data_quality_rule r LEFT JOIN data_quality_result q ON q.rule_id = r.rule_id AND q.batch_id = :batch_id WHERE r.enabled = 'Y' GROUP BY r.rule_id, r.severity, r.fail_threshold HAVING COUNT(q.result_id) >= r.fail_threshold;
このSQLは、ERRORとWARNを含む検出状況の一覧です。ジョブ失敗判定ではERRORだけを対象にし、WARNは通知や確認タスクに回します。
SELECT COUNT(*) AS warn_rule_count
FROM (
SELECT r.rule_id
FROM data_quality_rule r
JOIN data_quality_result q
ON q.rule_id = r.rule_id
AND q.batch_id = :batch_id
WHERE r.enabled = 'Y'
AND r.severity = 'WARN'
GROUP BY r.rule_id, r.fail_threshold
HAVING COUNT(*) >= r.fail_threshold
);
WARN件数はジョブを止めるためではなく、通知や確認依頼に使います。毎回同じWARNが大量に出る場合は、しきい値やルール自体を見直します。
DECLARE
v_error_rules NUMBER;
BEGIN
SELECT COUNT(*)
INTO v_error_rules
FROM (
SELECT r.rule_id
FROM data_quality_rule r
JOIN data_quality_result q
ON q.rule_id = r.rule_id
AND q.batch_id = :batch_id
WHERE r.enabled = 'Y'
AND r.severity = 'ERROR'
GROUP BY r.rule_id, r.fail_threshold
HAVING COUNT(*) >= r.fail_threshold
);
IF v_error_rules > 0 THEN
RAISE_APPLICATION_ERROR(
-20971,
'データ品質チェックでERRORルールがしきい値を超えました。rules=' || v_error_rules
);
END IF;
END;
/
業務エラーコードとして管理する場合は PL/SQLの業務エラーコード設計 と組み合わせると、画面やバッチログで扱いやすくなります。
検証バッチの実行ログを残す
品質チェック自体も、いつ、どの範囲を、何件検出したかを残します。検証結果テーブルは明細、実行ログはサマリーとして使います。
CREATE TABLE data_quality_batch_log ( batch_id NUMBER PRIMARY KEY, check_name VARCHAR2(100) NOT NULL, from_date DATE, to_date DATE, status VARCHAR2(20) NOT NULL, error_count NUMBER DEFAULT 0 NOT NULL, warn_count NUMBER DEFAULT 0 NOT NULL, started_at TIMESTAMP NOT NULL, finished_at TIMESTAMP, error_message VARCHAR2(2000) );
batch_idをアプリケーション側で採番しない場合は、ログ用のシーケンスも用意します。再実行や監査保持で新しい検証単位を作るときに使います。
CREATE SEQUENCE data_quality_batch_seq START WITH 1 INCREMENT BY 1 NOCACHE;
UPDATE data_quality_batch_log SET status = CASE WHEN :error_rule_count > 0 THEN 'FAILED' ELSE 'SUCCESS' END, error_count = :error_rule_count, warn_count = :warn_count, finished_at = SYSTIMESTAMP, error_message = :error_message WHERE batch_id = :batch_id; COMMIT;
error_rule_countは、ERROR重要度のルールがしきい値以上検出された件数です。WARNだけならstatusはSUCCESSにし、warn_countを通知に使います。
ジョブ実行履歴を共通化している場合は、専用テーブルではなく共通の履歴テーブルに寄せても構いません。ジョブ履歴の設計は ジョブ実行履歴テーブル設計 と同じ考え方です。
再実行できる設計にする
品質チェックは再実行できる必要があります。同じバッチIDで再実行するのか、新しいバッチIDで同じ期間を再検証するのかを決めます。同じバッチIDでやり直す場合は、監査要件がない一時結果として扱い、前回の検出結果を削除してから実行します。監査証跡を残す必要がある場合は、新しいバッチIDで再検証します。
DELETE FROM data_quality_result WHERE batch_id = :batch_id; UPDATE data_quality_batch_log SET status = 'RUNNING', error_count = 0, warn_count = 0, started_at = SYSTIMESTAMP, finished_at = NULL, error_message = NULL WHERE batch_id = :batch_id;
これは置き換え再実行モードです。検証結果を派生データとして扱い、同じ条件で作り直します。監査目的で過去の検証結果を残す場合は、次のように新しいバッチIDで再実行します。
INSERT INTO data_quality_batch_log ( batch_id, check_name, from_date, to_date, status, started_at ) VALUES ( data_quality_batch_seq.NEXTVAL, 'DAILY_DATA_QUALITY_CHECK', :from_date, :to_date, 'RUNNING', SYSTIMESTAMP );
やってはいけない品質チェック
最後に、避けるべき設計を整理します。データ品質チェックは、形だけ作るとすぐに見られないログになります。
設計チェックリスト
データ品質チェック・整合性検証バッチを作る前に、次の点を確認します。
- チェック種別を分類している
- ルールごとに重要度としきい値を決めている
- 検出結果をテーブルに残している
- 対象期間や対象バッチIDを固定している
- NULL、重複、参照不整合、金額差異を検出できる
- ERRORルールは後続処理を止める設計になっている
- WARNルールは通知や確認タスクにつながる
- 再実行時に前回結果をどう扱うか決まっている
- 検証バッチ自体の実行ログがある
- 検出後の担当者や復旧手順が決まっている
まとめ
PL/SQLでデータ品質チェックを作るときは、単発の検算SQLを増やすだけでは不十分です。ルール、検出結果、しきい値、ジョブ失敗判定、再実行、通知までを含めて設計すると、運用で使える整合性検証バッチになります。
特に重要なのは、検出結果をテーブルに残すこと、ERRORとWARNを分けること、しきい値で後続処理を止めることです。品質チェックは、問題を見つけるためだけでなく、問題のあるデータを次工程へ流さないための防波堤として設計しましょう。