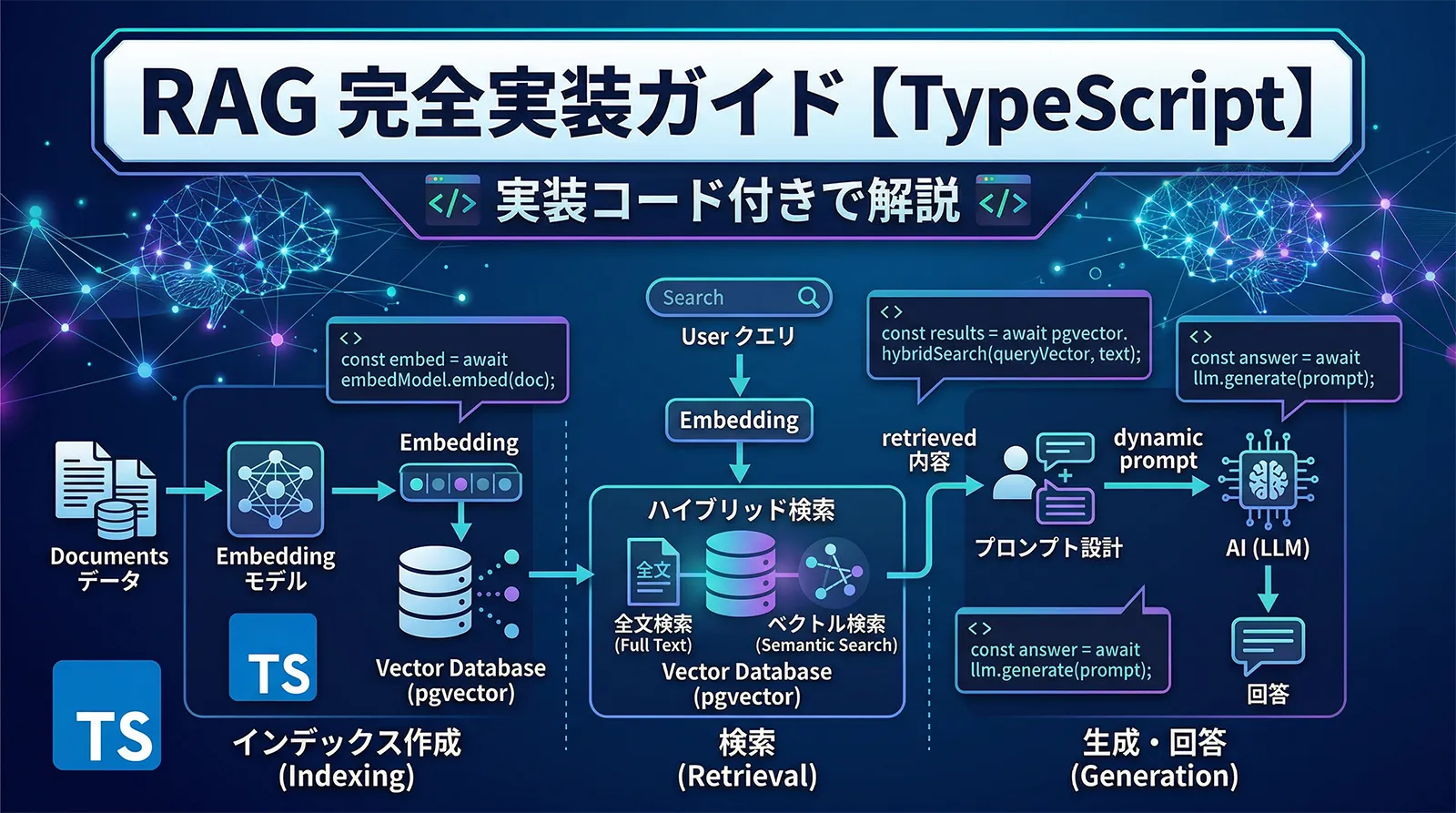
ChatGPTなどのLLMは学習データの知識しか持ちません。「自社ドキュメントを参照して回答させたい」「最新情報を反映させたい」——そのニーズに応えるのがRAG(Retrieval-Augmented Generation)です。外部ドキュメントをベクトル検索で取得し、コンテキストとしてLLMに渡すことで、モデルを再学習せずに知識を拡張できます。
この記事では、RAGをTypeScriptで一から実装する方法を体系的に解説します。Embeddingの生成・テキスト分割・pgvectorを使ったベクトルDBの構築・ハイブリッド検索・RAGプロンプト設計・Next.jsへの統合・品質評価まで、実装コードつきで網羅します。OpenAI・Claude APIの両方に対応した内容です。
「社内マニュアルQAボット」「ドキュメント検索API」「コードベース質問AI」など、実務でよく求められるユースケースをカバーしています。プロンプトエンジニアリングやVercel AI SDKとの組み合わせ方も紹介します。
- RAGの仕組みとインデックスパイプライン・クエリパイプラインの全体像
- Embedding(テキストのベクトル化)の生成方法(OpenAI・Voyage AI)
- チャンキング(テキスト分割)戦略と適切なチャンクサイズの選び方
- pgvector(PostgreSQL)でのベクトルDBの構築とCRUD実装
- ベクトル検索とBM25を組み合わせたハイブリッド検索の実装
- RAGプロンプトの設計原則と幻覚(ハルシネーション)の抑制方法
- Next.js App RouterでのRAGボット実装
- RAGの品質評価指標と改善アプローチ
RAGとは何か・なぜ必要か
LLMはトレーニングデータに含まれない情報(社内ドキュメント・最新ニュース・プロダクト仕様書など)については回答できないか、誤った内容を生成(ハルシネーション)します。RAGはこの問題を、質問に関連するドキュメントをリアルタイムで検索してコンテキストに注入することで解決します。
| アプローチ | 仕組み | 適したケース | 限界 |
|---|---|---|---|
| LLM直接利用 | 学習済み知識のみ | 汎用的な質問 | 最新情報・社内情報を扱えない |
| RAG | 外部DB検索 + LLM生成 | 特定ドキュメントへの質問 | 検索品質に回答品質が依存 |
| ファインチューニング | 学習データで追加学習 | 特定スタイル・タスクの習得 | 最新データへの対応が困難・コスト高 |
| コンテキストに全文注入 | 全ドキュメントを毎回渡す | 数十ページ以内の小規模文書 | コスト大・コンテキスト長制限あり |
RAGの2つのパイプライン
RAGシステムは大きくインデックスパイプラインとクエリパイプラインの2つで構成されます。
- ドキュメントの読み込み(PDF・Markdown・Web・DB等)
- テキストの分割(チャンキング)
- Embeddingの生成(テキスト→ベクトル変換)
- ベクトルDBへの保存
- ユーザーの質問をEmbeddingに変換
- ベクトルDBで類似チャンクを検索
- 上位チャンクをコンテキストとしてプロンプトに注入
- LLMが回答を生成
環境セットアップ
# 必要なパッケージをインストール npm install openai @ai-sdk/openai ai zod # PostgreSQL + pgvector(ベクトルDB) npm install pg drizzle-orm drizzle-kit npm install -D @types/pg # テキスト処理 npm install tiktoken # トークンカウント npm install pdf-parse # PDF読み込み npm install -D @types/pdf-parse
docker run -d \ --name pgvector \ -e POSTGRES_USER=postgres \ -e POSTGRES_PASSWORD=postgres \ -e POSTGRES_DB=ragdb \ -p 5432:5432 \ pgvector/pgvector:pg16
OPENAI_API_KEY=sk-xxxxxxxx ANTHROPIC_API_KEY=sk-ant-xxxxxxxx DATABASE_URL=postgresql://postgres:postgres@localhost:5432/ragdb
データベーススキーマの定義
pgvectorはPostgreSQLの拡張機能で、ベクトル型のカラムを持つテーブルを作成できます。通常のPostgreSQLと同じSQLで操作でき、既存のDBに追加するだけで導入できるのが魅力です。
-- pgvector拡張を有効化
CREATE EXTENSION IF NOT EXISTS vector;
-- ドキュメントチャンクのテーブル
CREATE TABLE IF NOT EXISTS document_chunks (
id BIGSERIAL PRIMARY KEY,
content TEXT NOT NULL, -- チャンクのテキスト
embedding VECTOR(1536), -- OpenAI text-embedding-3-small のベクトル次元
metadata JSONB DEFAULT '{}', -- ソースファイル名・ページ番号等
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- コサイン類似度検索用インデックス(IVFFlat)
-- リスト数はデータ量に応じて調整(目安: sqrt(行数))
CREATE INDEX ON document_chunks
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
-- 全文検索用インデックス(ハイブリッド検索で使用)
-- 日本語ドキュメントの場合は 'english' を 'simple' に変更するか pg_bigm/pgroonga を導入する
CREATE INDEX ON document_chunks
USING gin(to_tsvector('simple', content));
import { pgTable, bigserial, text, jsonb, timestamp, customType } from "drizzle-orm/pg-core";
// pgvectorのVECTOR型をDrizzleのカスタム型として定義
const vector = customType<{ data: number[]; driverData: string }>({
dataType(config) {
return `vector(${(config as { dimensions?: number }).dimensions ?? 1536})`;
},
fromDriver(value: string): number[] {
// "[0.1,0.2,...]" 形式の文字列を配列に変換
return JSON.parse(value.replace(/^\[/, "[").replace(/\]$/, "]"));
},
toDriver(value: number[]): string {
return `[${value.join(",")}]`;
},
});
export const documentChunks = pgTable("document_chunks", {
id: bigserial("id", { mode: "number" }).primaryKey(),
content: text("content").notNull(),
embedding: vector("embedding", { dimensions: 1536 }),
metadata: jsonb("metadata").$type<{
source: string;
page?: number;
chunkIndex: number;
title?: string;
}>().default({}),
createdAt: timestamp("created_at").defaultNow(),
});
export type DocumentChunk = typeof documentChunks.$inferSelect;
export type NewDocumentChunk = typeof documentChunks.$inferInsert;
テキスト分割(チャンキング)戦略
RAGの品質はチャンクの設計に大きく左右されます。チャンクが大きすぎると無関係な情報が混入し、小さすぎると文脈が失われます。一般的には512〜1024トークン、オーバーラップ50〜100トークンが出発点です。
import { encode } from "tiktoken";
interface ChunkOptions {
chunkSize: number; // トークン数(デフォルト: 512)
chunkOverlap: number; // オーバーラップトークン数(デフォルト: 50)
}
interface Chunk {
content: string;
chunkIndex: number;
tokenCount: number;
}
/**
* テキストをトークン数に基づいて分割する
* - 文の途中では切らずに段落・文単位で分割
* - オーバーラップで文脈の連続性を保つ
*/
export function splitText(
text: string,
options: Partial<ChunkOptions> = {}
): Chunk[] {
const { chunkSize = 512, chunkOverlap = 50 } = options;
const enc = encode(text);
const totalTokens = enc.length;
if (totalTokens <= chunkSize) {
return [{ content: text.trim(), chunkIndex: 0, tokenCount: totalTokens }];
}
// 段落単位で分割してからチャンクに詰める
const paragraphs = text
.split(/\n{2,}/)
.map((p) => p.trim())
.filter((p) => p.length > 0);
const chunks: Chunk[] = [];
let currentChunk = "";
let currentTokens = 0;
let chunkIndex = 0;
for (const paragraph of paragraphs) {
const paraTokens = encode(paragraph).length;
// チャンクサイズを超えたら新しいチャンクへ
if (currentTokens + paraTokens > chunkSize && currentChunk) {
chunks.push({
content: currentChunk.trim(),
chunkIndex: chunkIndex++,
tokenCount: currentTokens,
});
// オーバーラップ分を次のチャンクの先頭に含める
const overlapText = getLastNTokens(currentChunk, chunkOverlap);
currentChunk = overlapText + "\n\n" + paragraph;
currentTokens = encode(currentChunk).length;
} else {
currentChunk += (currentChunk ? "\n\n" : "") + paragraph;
currentTokens += paraTokens;
}
}
if (currentChunk.trim()) {
chunks.push({
content: currentChunk.trim(),
chunkIndex: chunkIndex,
tokenCount: currentTokens,
});
}
return chunks;
}
function getLastNTokens(text: string, n: number): string {
const words = text.split(/\s+/);
// 簡易的な近似(正確にはtiktokenで計算)
return words.slice(-n * 2).join(" ");
}
// マークダウン見出し単位で分割するヒューリスティック
export function splitMarkdown(markdown: string): Chunk[] {
const sections = markdown.split(/(?=^#{1,3} )/m);
return sections
.filter((s) => s.trim())
.flatMap((section, i) => {
const tokens = encode(section).length;
if (tokens <= 512) {
return [{ content: section.trim(), chunkIndex: i, tokenCount: tokens }];
}
// セクションが大きい場合は再分割
return splitText(section, { chunkSize: 512, chunkOverlap: 50 }).map(
(c, j) => ({ ...c, chunkIndex: i * 100 + j })
);
});
}
技術ドキュメントは見出し単位で分割、FAQは一問一答単位で分割、書籍PDFは段落単位で分割するなど、ドキュメントの構造に合わせた戦略が品質向上につながります。チャンクに元のソース情報(ファイル名・ページ番号)を必ずメタデータとして付与してください。
Embeddingの生成
EmbeddingはテキストをLLMが意味を学習した高次元ベクトルに変換したものです。意味的に近いテキストは空間上で近い場所に配置されるため、コサイン類似度によって関連チャンクを検索できます。
| モデル | プロバイダー | 次元数 | 価格(1M tokens) | 特徴 |
|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | $0.02 | コスパ最良。日本語もOK |
| text-embedding-3-large | OpenAI | 3072 | $0.13 | 高精度。大規模システム向け |
| voyage-3-large | Voyage AI | 1024 | $0.06 | Claude用。コード・技術文書に強い |
| embed-multilingual-v3 | Cohere | 1024 | $0.10 | 多言語対応。日本語に強い |
import OpenAI from "openai";
const openai = new OpenAI();
/**
* テキストのEmbeddingを生成する
* バッチ処理対応(複数テキストを1回のAPIコールで処理)
*/
export async function generateEmbeddings(
texts: string[]
): Promise<number[][]> {
// OpenAI Embeddings APIは1回で最大2048テキストを処理可能
const batchSize = 100;
const allEmbeddings: number[][] = [];
for (let i = 0; i < texts.length; i += batchSize) {
const batch = texts.slice(i, i + batchSize);
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input: batch,
encoding_format: "float",
});
const batchEmbeddings = response.data
.sort((a, b) => a.index - b.index) // 順序を保証
.map((e) => e.embedding);
allEmbeddings.push(...batchEmbeddings);
// レート制限を避けるため少し待機
if (i + batchSize < texts.length) {
await new Promise((resolve) => setTimeout(resolve, 100));
}
}
return allEmbeddings;
}
export async function generateEmbedding(text: string): Promise<number[]> {
const [embedding] = await generateEmbeddings([text]);
return embedding;
}
// クエリ用(短いテキストに最適化)
export async function generateQueryEmbedding(query: string): Promise<number[]> {
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input: query,
encoding_format: "float",
});
return response.data[0].embedding;
}
インデックスパイプラインの実装
ドキュメントを読み込み、分割し、Embeddingを生成してDBに保存するインデックスパイプラインをまとめて実装します。
import { drizzle } from "drizzle-orm/node-postgres";
import { Pool } from "pg";
import { documentChunks, type NewDocumentChunk } from "../db/schema";
import { splitText, splitMarkdown } from "./text-splitter";
import { generateEmbeddings } from "./embeddings";
import * as fs from "fs";
import * as path from "path";
const pool = new Pool({ connectionString: process.env.DATABASE_URL });
const db = drizzle(pool);
interface IndexOptions {
source: string; // ソースファイル名(メタデータ用)
title?: string;
chunkSize?: number;
chunkOverlap?: number;
}
/**
* テキストをインデックスに追加する
*/
export async function indexText(
text: string,
options: IndexOptions
): Promise<number> {
const { source, title, chunkSize = 512, chunkOverlap = 50 } = options;
// テキストを分割
const chunks = splitText(text, { chunkSize, chunkOverlap });
console.log(`${source}: ${chunks.length}チャンクに分割`);
// バッチでEmbeddingを生成
const contents = chunks.map((c) => c.content);
const embeddings = await generateEmbeddings(contents);
console.log(`Embedding生成完了: ${embeddings.length}件`);
// DBに一括挿入
const rows: NewDocumentChunk[] = chunks.map((chunk, i) => ({
content: chunk.content,
embedding: embeddings[i],
metadata: {
source,
title,
chunkIndex: chunk.chunkIndex,
},
}));
await db.insert(documentChunks).values(rows);
console.log(`インデックス追加完了: ${rows.length}件`);
return rows.length;
}
/**
* Markdownファイルをインデックスに追加する
*/
export async function indexMarkdownFile(filePath: string): Promise<number> {
const content = fs.readFileSync(filePath, "utf-8");
const source = path.basename(filePath);
const title = content.match(/^#\s+(.+)/m)?.[1] ?? source;
return indexText(content, { source, title });
}
/**
* ディレクトリ内のMarkdownファイルをすべてインデックスする
*/
export async function indexDirectory(dirPath: string): Promise<void> {
const files = fs.readdirSync(dirPath)
.filter((f) => f.endsWith(".md") || f.endsWith(".txt"));
let total = 0;
for (const file of files) {
const count = await indexMarkdownFile(path.join(dirPath, file));
total += count;
console.log(`${file}: ${count}チャンク追加 (合計: ${total})`);
}
console.log(`\nインデックス完了: ${files.length}ファイル, ${total}チャンク`);
}
ベクトル検索とハイブリッド検索の実装
ベクトル類似検索(コサイン類似度)
import { drizzle } from "drizzle-orm/node-postgres";
import { Pool } from "pg";
import { sql } from "drizzle-orm";
import { documentChunks, type DocumentChunk } from "../db/schema";
import { generateQueryEmbedding } from "./embeddings";
const pool = new Pool({ connectionString: process.env.DATABASE_URL });
const db = drizzle(pool);
export interface SearchResult {
chunk: DocumentChunk;
score: number; // 0〜1(1が最も類似)
}
/**
* ベクトル類似検索(コサイン類似度)
*/
export async function vectorSearch(
query: string,
topK: number = 5,
threshold: number = 0.7
): Promise<SearchResult[]> {
const queryEmbedding = await generateQueryEmbedding(query);
const embeddingStr = `[${queryEmbedding.join(",")}]`;
// pgvectorの <=> 演算子はコサイン距離(0=完全一致、2=完全不一致)
// 類似度 = 1 - コサイン距離
const results = await db.execute(sql`
SELECT
id,
content,
metadata,
created_at,
1 - (embedding <=> ${embeddingStr}::vector) AS score
FROM document_chunks
WHERE 1 - (embedding <=> ${embeddingStr}::vector) >= ${threshold}
ORDER BY embedding <=> ${embeddingStr}::vector
LIMIT ${topK}
`);
return (results.rows as Array<DocumentChunk & { score: number }>).map(
(row) => ({ chunk: row, score: row.score })
);
}
/**
* ハイブリッド検索(ベクトル検索 + BM25全文検索の組み合わせ)
* Reciprocal Rank Fusion (RRF) でスコアを統合
*/
export async function hybridSearch(
query: string,
topK: number = 5
): Promise<SearchResult[]> {
const queryEmbedding = await generateQueryEmbedding(query);
const embeddingStr = `[${queryEmbedding.join(",")}]`;
// RRF定数(通常60を使用)
const rrfK = 60;
const results = await db.execute(sql`
WITH
vector_ranked AS (
SELECT
id,
ROW_NUMBER() OVER (
ORDER BY embedding <=> ${embeddingStr}::vector
) AS rank
FROM document_chunks
ORDER BY embedding <=> ${embeddingStr}::vector
LIMIT 20
),
bm25_ranked AS (
-- 注意: 日本語の場合は 'english' を 'simple' に変更するか pg_bigm/pgroonga を使用する
SELECT
id,
ROW_NUMBER() OVER (
ORDER BY ts_rank(
to_tsvector('simple', content),
plainto_tsquery('simple', ${query})
) DESC
) AS rank
FROM document_chunks
WHERE to_tsvector('simple', content) @@ plainto_tsquery('simple', ${query})
LIMIT 20
),
rrf_scores AS (
SELECT
COALESCE(v.id, b.id) AS id,
COALESCE(1.0 / (${rrfK} + v.rank), 0) +
COALESCE(1.0 / (${rrfK} + b.rank), 0) AS rrf_score
FROM vector_ranked v
FULL OUTER JOIN bm25_ranked b ON v.id = b.id
)
SELECT
dc.id,
dc.content,
dc.metadata,
dc.created_at,
r.rrf_score AS score
FROM rrf_scores r
JOIN document_chunks dc ON r.id = dc.id
ORDER BY r.rrf_score DESC
LIMIT ${topK}
`);
return (results.rows as Array<DocumentChunk & { score: number }>).map(
(row) => ({ chunk: row, score: row.score })
);
}
ベクトル検索は意味的な類似を捉えますが、正確なキーワード(型番・固有名詞・コマンド名等)の検索が苦手です。ハイブリッド検索はベクトル検索とBM25(全文検索)をRRFで統合し、両方の強みを活かします。エンジニア向け技術ドキュメントや仕様書QAには特に効果的です。
RAGパイプライン:検索から回答生成まで
import Anthropic from "@anthropic-ai/sdk";
import { hybridSearch, type SearchResult } from "./retriever";
const client = new Anthropic();
interface RagOptions {
topK?: number;
model?: string;
maxTokens?: number;
}
export interface RagResponse {
answer: string;
sources: Array<{
content: string;
source: string;
score: number;
}>;
hasRelevantDocs: boolean;
}
/**
* RAGプロンプトの構築
* - 検索結果をコンテキストとしてプロンプトに注入
* - 「文書にない場合は答えない」制約で幻覚を抑制
*/
function buildRagPrompt(query: string, results: SearchResult[]): string {
if (results.length === 0) {
return query;
}
const context = results
.map((r, i) => {
const source = (r.chunk.metadata as { source?: string }).source ?? "不明";
return `[文書${i + 1}] (出典: ${source})\n${r.chunk.content}`;
})
.join("\n\n---\n\n");
return `以下の参考文書をもとに、質問に回答してください。
【重要なルール】
- 参考文書に記載されている情報のみを使って回答する
- 文書にない情報は推測・補完しない
- 不確かな場合は「文書には記載がありません」と明記する
- 回答の根拠となる文書番号を [文書X] 形式で必ず示す
===参考文書===
${context}
=============
質問: ${query}`;
}
/**
* RAGを使って質問に回答する
*/
export async function ragQuery(
query: string,
options: RagOptions = {}
): Promise<RagResponse> {
const {
topK = 5,
model = "claude-opus-4-6",
maxTokens = 1024,
} = options;
// 1. ハイブリッド検索で関連チャンクを取得
const searchResults = await hybridSearch(query, topK);
const hasRelevantDocs = searchResults.length > 0;
// 2. プロンプトを構築
const prompt = buildRagPrompt(query, searchResults);
// 3. LLMに回答を生成させる
const response = await client.messages.create({
model,
max_tokens: maxTokens,
system: `あなたは正確な情報提供を最優先にするAIアシスタントです。
与えられた文書の範囲内で回答し、文書に記載のない情報は提供しないでください。
日本語で回答してください。`,
messages: [{ role: "user", content: prompt }],
});
const answer = (response.content[0] as { text: string }).text;
return {
answer,
sources: searchResults.map((r) => ({
content: r.chunk.content.slice(0, 200) + "...",
source: (r.chunk.metadata as { source?: string }).source ?? "不明",
score: r.score,
})),
hasRelevantDocs,
};
}
Next.js App RouterへのRAGボット実装
Route Handler:ストリーミングRAG API
import { streamText } from "ai";
import { anthropic } from "@ai-sdk/anthropic";
import { hybridSearch } from "@/lib/retriever";
export const runtime = "nodejs"; // pgはEdge非対応のためNode.js
export async function POST(req: Request) {
const { query, history } = await req.json() as {
query: string;
history?: { role: "user" | "assistant"; content: string }[];
};
if (!query?.trim()) {
return new Response("queryが必要です", { status: 400 });
}
// 関連ドキュメントを検索
const results = await hybridSearch(query, 4);
const context = results
.map((r, i) => {
const src = (r.chunk.metadata as { source?: string }).source ?? "不明";
return `[文書${i + 1}] ${src}\n${r.chunk.content}`;
})
.join("\n\n---\n\n");
const systemPrompt = results.length > 0
? `あなたはドキュメントQAアシスタントです。以下の文書のみを根拠に回答してください。
文書にない情報は「文書には記載がありません」と答えてください。
===参考文書===
${context}
=============`
: "あなたはAIアシスタントです。関連する文書が見つかりませんでした。一般的な知識で回答してください。";
const result = streamText({
model: anthropic("claude-opus-4-6"),
system: systemPrompt,
messages: [
...(history ?? []),
{ role: "user", content: query },
],
maxTokens: 1024,
});
return result.toDataStreamResponse();
}
フロントエンド:ソース表示付きチャットUI
"use client";
import { useChat } from "@ai-sdk/react"; // npm install @ai-sdk/react
import { useState } from "react";
interface Source {
content: string;
source: string;
score: number;
}
export default function RagChat() {
const { messages, input, handleInputChange, handleSubmit, isLoading } =
useChat({ api: "/api/rag" });
return (
<div className="rag-chat">
<div className="messages">
{messages.map((m) => (
<div key={m.id} className={`message ${m.role}`}>
<div className="message-role">
{m.role === "user" ? "あなた" : "AI"}
</div>
<div className="message-content">{m.content}</div>
</div>
))}
{isLoading && (
<div className="message assistant">
<div className="message-role">AI</div>
<div className="message-content loading">回答を生成中...</div>
</div>
)}
</div>
<form onSubmit={handleSubmit} className="input-form">
<input
value={input}
onChange={handleInputChange}
placeholder="ドキュメントについて質問してください..."
disabled={isLoading}
/>
<button type="submit" disabled={isLoading || !input.trim()}>
送信
</button>
</form>
</div>
);
}
RAGの品質評価と改善アプローチ
RAGシステムは実装後も継続的なチューニングが必要です。評価指標を定義して定量的に改善を進めましょう。
| 評価指標 | 意味 | 測定方法 | 改善策 |
|---|---|---|---|
| Context Precision | 検索されたチャンクの関連度 | 人手評価 or LLMで採点 | スコア閾値を上げる・チャンクサイズ調整 |
| Context Recall | 必要な情報がどれだけ検索されたか | ゴールドセット比較 | topKを増やす・ハイブリッド検索導入 |
| Answer Faithfulness | 回答が文書に基づいているか(幻覚度) | LLMで検証 | プロンプトの制約を強化 |
| Answer Relevance | 回答が質問に答えているか | LLMで採点 | システムプロンプトのチューニング |
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
interface EvalResult {
faithfulness: number; // 0〜1: 回答が文書に忠実か
relevance: number; // 0〜1: 回答が質問に関連しているか
reasoning: string;
}
/**
* LLMを使ってRAG回答の品質を自動評価する
* いわゆる "LLM-as-a-judge" パターン
*/
export async function evaluateRagAnswer(
query: string,
answer: string,
contexts: string[]
): Promise<EvalResult> {
const contextText = contexts
.map((c, i) => `[文書${i + 1}] ${c}`)
.join("\n\n");
const response = await client.messages.create({
model: "claude-opus-4-6",
max_tokens: 512,
messages: [
{
role: "user",
content: `以下のRAG回答を評価してください。JSONのみで返してください。
質問: ${query}
参考文書:
${contextText}
回答: ${answer}
評価基準:
1. faithfulness(0〜1): 回答が参考文書の内容に忠実かどうか(文書にない情報を追加していないか)
2. relevance(0〜1): 回答が質問に適切に答えているかどうか
JSON形式:
{"faithfulness": 0.9, "relevance": 0.85, "reasoning": "評価の理由"}`,
},
],
});
const text = (response.content[0] as { text: string }).text;
const match = text.match(/\{[\s\S]*\}/);
if (!match) throw new Error("評価結果のパースに失敗");
return JSON.parse(match[0]) as EvalResult;
}
ベクトルDBの選択ガイド
pgvector以外にもさまざまなベクトルDBがあります。プロジェクトの規模・既存インフラ・運用コストを考慮して選択しましょう。
| DB | 形態 | 特徴 | 適したケース |
|---|---|---|---|
| pgvector | PostgreSQL拡張 | 既存PGに追加。SQLで操作。管理コスト低 | 既存DBがPostgreSQL・中小規模 |
| Pinecone | マネージドクラウド | スケーラブル。設定不要ですぐ使える | 大規模・サーバーレス・素早く試したい |
| Qdrant | OSS / マネージド | 高性能フィルタリング。Rust製で高速 | フィルタリング検索が重要な場合 |
| Weaviate | OSS / マネージド | マルチモーダル対応。GraphQL API | 画像・動画を含むマルチモーダルRAG |
| Chroma | OSS(ローカル/クラウド) | Pythonとの相性が良い。組み込み可能 | プロトタイプ・Python環境との併用 |
数百万件を超えるデータではIVFFlatインデックスのパラメータ調整(
lists値)が重要になります。また、インデックス作成後はANALYZEを実行してプランナーに統計を更新させてください。10億件以上のスケールにはPineconeやQdrantなどの専用ベクトルDBが適しています。まとめ
RAGはLLMに外部知識を与える最も実用的な手法です。本記事で実装したパイプラインのポイントを整理します。
| フェーズ | 実装内容 | 品質向上のポイント |
|---|---|---|
| テキスト分割 | トークン数ベースのチャンキング | ドキュメント構造に合わせた分割戦略 |
| Embedding生成 | text-embedding-3-small でバッチ処理 | クエリとドキュメントに同じモデルを使う |
| インデックス | pgvector + IVFFlatインデックス | メタデータを充実させてフィルタリング活用 |
| 検索 | ハイブリッド検索(RRF) | キーワード検索と意味検索の両方を活かす |
| 回答生成 | RAGプロンプト + Claude/OpenAI | 幻覚抑制のための制約プロンプトを必ず入れる |
| 評価 | LLM-as-a-judge | Faithfulness + Relevanceを定期測定 |
RAGの品質は「検索品質 × 生成品質」の掛け算です。回答が悪い場合、まず検索されたチャンクを確認して原因を切り分けましょう。プロンプト設計についてはプロンプトエンジニアリング完全ガイド、ストリーミング対応のUI実装はVercel AI SDK完全ガイドを参照してください。
よくある質問
QRAGとファインチューニングはどう使い分けますか?
ARAGは「知識の注入」に、ファインチューニングは「振る舞いやスタイルの習得」に向いています。例えば「社内ドキュメントに基づいて回答させたい」はRAG、「特定の文体で回答させたい・特定タスクに特化させたい」はファインチューニングです。多くの実務ケースではRAGで十分対応でき、コストも低く抑えられます。
Qチャンクサイズはどう決めればよいですか?
A目安は512〜1024トークンです。短い文書(FAQ・仕様書の箇条書き)は256〜512トークン、長い説明文書(マニュアル・技術書)は512〜1024トークンが適しています。実際には複数のサイズでA/Bテストを行い、Context Precisionを測定して最適値を見つけるのが確実です。
Q日本語ドキュメントにもOpenAIのEmbeddingは使えますか?
Aはい、text-embedding-3-smallは多言語対応しており、日本語でも十分な精度が出ます。ただし、全文検索(BM25)の部分は言語に応じた設定が必要です。PostgreSQLで日本語全文検索を行う場合はpg_bigm拡張やpgroonga拡張の導入を検討してください。
Qpgvectorは本番環境で使えますか?
Aはい、Supabase・Neon・RDS(PostgreSQL)など主要マネージドDBサービスがpgvectorをサポートしています。数十万件程度のデータであれば、pgvectorで十分なパフォーマンスが出ます。ただし数百万件を超える場合はインデックスパラメータの調整や、PineconeやQdrantなど専用ベクトルDBへの移行を検討してください。
QRAGで幻覚(ハルシネーション)を完全に防ぐことはできますか?
A完全な防止は難しいですが、大幅に抑制できます。効果的な対策は①プロンプトに「文書にない情報は答えない」を明記する、②回答に文書番号の引用を必須にする、③Faithfulness評価で定期的に品質を測定する、の3つです。高精度が求められる場合は、生成後にLLMで「この回答は文書に基づいているか」を自己検証させる(Self-Refine)パターンも有効です。
Qベクトル検索の類似度スコアはどの閾値で使えばよいですか?
Aコサイン類似度では0.7〜0.8が実用的な閾値です。0.7未満のチャンクは関連度が低く、含めると回答品質が下がる可能性があります。ただしドメインやEmbeddingモデルによって適切な閾値は変わります。評価セットを使って精度・再現率のトレードオフを確認しながら調整してください。

