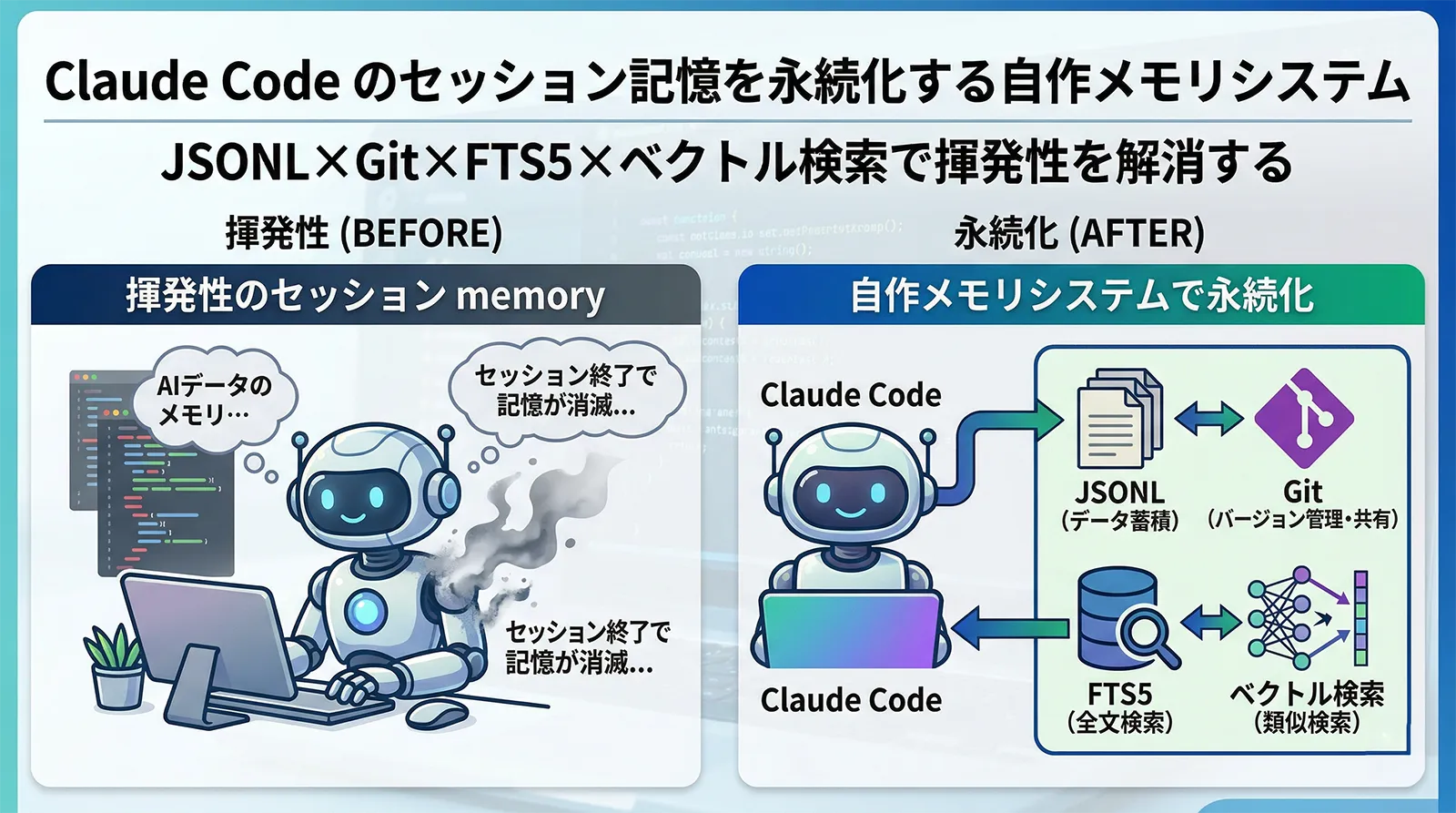
Claude Code のセッションは揮発性です。新しいセッションを開けば前回の文脈は消え、別のデバイスを開けばその前提もない。CLAUDE.md や auto-memory で「ルール」は引き継げますが、「過去の試行錯誤の経緯」「3週間前に却下した案の理由」「バグ調査中に気づいた仕様上の矛盾」といった知識の背景は消えていきます。
この問題への実用的な回答は「会話を構造化データとして保存し、必要なときだけ検索して引き出す」という設計です。本記事では、JSONL をデータの正本として Git で管理し、SQLite(FTS5 + sqlite-vec)をローカル検索エンジンとして使う自作メモリシステムの設計思想と実装を解説します。Claude Code の基本や組み込みメモリ機能とは目的が異なり、本システムは「会話の文脈そのもの」を永続化する点に特徴があります。
前提知識:Python の基本的な読み書き・Git の基本操作・SQLite の概念
揮発性の本質的な問題とその影響
Claude Code が揮発性であることで実際に困るのはどういう場面でしょうか。よくあるケースを整理します。
| 場面 | 失われるもの | 再現コスト |
|---|---|---|
| デバッグの試行錯誤 | 「これはすでに試した・なぜ失敗したか」の記録 | 同じ間違いを繰り返すリスク |
| 設計判断の経緯 | 「なぜAではなくBを選んだか」という背景 | 後から見た人(自分も含む)に理由が伝わらない |
| 却下した案 | 「これをやってはいけない理由」という暗黙知 | 同じ問題に何度もぶつかる |
| 複数デバイスの作業 | 別デバイスで行った分析・判断の全文脈 | 補助ドキュメントを手書きしないと引き継げない |
| 調査結果の積み上げ | 「〇〇ライブラリのバージョン互換性の調査結果」 | 次回また調べるか、うろ覚えで進む |
CLAUDE.md で「このプロジェクトはTypeScriptを使う」は伝えられますが、「TypeScript の Strict モードを有効にしたら出てきた ts2345 を3日かけて潰した経緯」は書けません。後者こそが、経験として蓄積すべき情報です。
記憶の永続化:設計の選択肢と比較
実装の前に、考えられる選択肢を整理します。どの方法にも適切な使い所があります。
| 方法 | 何を記録するか | 検索性 | 複数デバイス | 実装コスト |
|---|---|---|---|---|
| auto-memory(組み込み) | ユーザーの好み・短い事実・プロジェクト状態 | △(全件注入) | △(手動コピー) | ゼロ |
| CLAUDE.md への追記 | ルール・制約・禁止事項 | ✗(全件読み込み) | ✓(Git) | ゼロ |
| –resume フラグ | 直前のセッションのみ | ✗(文脈注入のみ) | ✗ | ゼロ |
| 本記事のシステム | 会話の全文・設計判断の経緯・試行錯誤の詳細 | ✓(ハイブリッド検索) | ✓(Git×JSONL) | 中 |
組み込み機能でカバーできない「長い文脈・複数デバイス・意味検索」という3点が、自作する理由です。
アーキテクチャの全体像
システム全体は4つのレイヤーで構成されます。
| レイヤー | 役割 | 技術 | 同期 |
|---|---|---|---|
| ①データ正本 | 記憶の唯一の真実。すべてはここから再構築できる | JSONL ファイル | Git |
| ②ローカルキャッシュ | 高速検索のためのインデックス。壊れても①から復元可能 | SQLite(FTS5 + sqlite-vec) | 同期しない |
| ③長期アーカイブ | 数ヶ月〜年単位の古い記憶。ローカルには置かない | SQLite(archive.db) | クラウドストレージ |
| ④検索インターフェース | Claude Code から記憶を引き出す | Skill + CLI | — |
このうち最重要の設計判断が「SQLite を複数デバイスで同期しない」という選択です。SQLite はバイナリファイルであり、複数箇所からの同時書き込みはファイル破損の原因になります。Git や Dropbox で SQLite を同期しようとすると、必ずコンフリクトまたは破損が発生します。
代わりに JSONL(テキスト形式)をデータの正本として Git で管理し、SQLite はセッション開始時に JSONL から毎回再構築します。
デバイスごとにファイルを分けてコンフリクトを構造的に回避する
Git で JSONL を管理しても、複数のデバイスが同じファイルに書き込めばマージコンフリクトが発生します。この問題はデバイスごとにファイルを分けることで構造的に解消できます。
export/ 2026-03_desktop-win.jsonl # Windowsデスクトップが追記するファイル 2026-03_laptop-mac.jsonl # Macノートが追記するファイル 2026-03_server-linux.jsonl # 開発サーバーが追記するファイル
各デバイスは自分のファイルだけに追記(append)します。読み込みは全ファイルを対象にします。このルールを守ると:
- 同一ファイルへの同時書き込みが構造的に起きない
- Git のマージは append 同士のため fast-forward で解決
- テキスト形式のため、万一コンフリクトしても手動解決が容易
machineフィールドで記憶の出所を追跡できる
デバイスの識別は設定ファイルの1行で切り替えます。新しいデバイスを追加するときも、設定を変えてリポジトリをクローンするだけで既存の全記憶にアクセスできます。
[general] machine_name = "desktop-win" # このデバイス固有の識別子(スペースなし推奨) project = "main" # プロジェクト名(複数プロジェクトを分離) export_dir = "export" # JSONLを保存するディレクトリ(リポジトリ内) db_path = ".cache/memory.db" # SQLiteキャッシュ(.gitignore対象)
JSONL のスキーマ:何を、どの粒度で保存するか
JSONL の1行が1つの「記憶の最小単位」です。セッション全体を1レコードにするのではなく、Q&A ペア単位(=1往復)に分割して保存します。これにより検索の精度が上がり、後から「あの部分だけ」を引き出せます。
{
"id": "550e8400-e29b-41d4-a716-446655440000",
"session_id": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"project": "main",
"machine": "desktop-win",
"timestamp": "2026-03-25T14:32:11.000Z",
"question": "FastAPI の依存性注入でDBセッションを渡すとき、テスト時だけ差し替えるには?",
"answer": "dependency_overrides を使います。app.dependency_overrides[get_db] = get_test_db のように...",
"embedding": [0.0145, -0.0281, 0.0093, "... (1024次元) ..."]
}
全フィールドの説明です。
| フィールド | 型 | 役割と設計意図 |
|---|---|---|
id |
UUID | チャンク単位の一意識別子。冪等性の確保に使用(同じ id を2回 INSERT しても1件になる) |
session_id |
UUID | セッション単位でのグルーピング。「このセッションで話したこと全体」を取り出す際に使用 |
project |
string | プロジェクト名。検索スコープを絞り込むフィルタとして機能 |
machine |
string | どのデバイスで作成した記憶か。デバッグとフィルタリングに有用 |
timestamp |
ISO 8601(UTC) | 時間減衰スコアの計算に使用。古い記憶が検索上位を占領しないよう制御 |
question |
string | ユーザー入力。FTS5 の全文検索対象。長い入力はそのまま保存 |
answer |
string | AI の応答。FTS5 の全文検索対象。コードブロックも含めて保存 |
embedding |
float[1024] | Ruri v3-310m による埋め込みベクトル。JSONL に保存することでDB再構築時のモデルロードを不要にする |
embedding を JSONL に含める点は議論が分かれます。1024次元の配列はテキスト表現で1件あたり8〜12KB 増えます。しかしこれによりセッション開始時のモデルロードが不要になります。Ruri v3-310m のロードには数秒かかるため、毎回セッション開始時に発生するとストレスになります。ベクトルを事前計算・保存しておくことで、DB の再構築は「JSONL の読み込み→INSERT」だけで完結します。
SQLite のスキーマ:FTS5 と sqlite-vec を共存させる
ローカルキャッシュとして使う SQLite には、キーワード検索用の FTS5 テーブルとベクトル検索用の vec0 テーブルを作成します。両テーブルは id で紐付けます。
-- キーワード検索用(trigramトークナイザで日本語対応)
CREATE VIRTUAL TABLE IF NOT EXISTS memory_fts USING fts5(
id UNINDEXED,
session_id UNINDEXED,
project UNINDEXED,
machine UNINDEXED,
timestamp UNINDEXED,
question, -- 検索対象
answer, -- 検索対象
tokenize = "trigram"
);
-- ベクトル検索用(sqlite-vec の仮想テーブル)
CREATE VIRTUAL TABLE IF NOT EXISTS memory_vec USING vec0(
id TEXT PRIMARY KEY,
embedding FLOAT[1024]
);
FTS5 に trigram トークナイザを使う理由は日本語の形態素解析器が不要だからです。trigram は単語を分割せず3文字単位でインデックスを作るため、MeCab や Sudachi を別途インストールしなくても機能します。特に技術記事や会話ログのような「固有名詞・英数字混じりのテキスト」に対して、trigram は正確に機能します。
import sqlite3
import sqlite_vec
import json
def open_db(db_path: str) -> sqlite3.Connection:
conn = sqlite3.connect(db_path)
conn.enable_load_extension(True)
sqlite_vec.load(conn) # sqlite-vec を拡張機能としてロード
conn.enable_load_extension(False)
conn.row_factory = sqlite3.Row
return conn
def insert_chunk(conn: sqlite3.Connection, rec: dict, embedding: list[float]):
"""FTS5 と vec0 に同時挿入。id 衝突時は上書き(冪等)。"""
conn.execute(
"""INSERT OR REPLACE INTO memory_fts
(id, session_id, project, machine, timestamp, question, answer)
VALUES (?, ?, ?, ?, ?, ?, ?)""",
(rec["id"], rec.get("session_id",""), rec.get("project",""),
rec.get("machine",""), rec["timestamp"],
rec["question"], rec["answer"])
)
conn.execute(
"INSERT OR REPLACE INTO memory_vec(id, embedding) VALUES (?, ?)",
(rec["id"], json.dumps(embedding))
)
conn.commit()
チャンク化:セッションログをどう Q&A に分割するか
Claude Code のセッションログは ~/.claude/projects/ 配下に JSONL 形式で保存されています。Stop Hook が発火した時点で、このログを読み込んでチャンクに分割します。
分割の単位は「ユーザーメッセージ→AIレスポンス」の1往復です。ただし以下のケースでは複数往復をまとめた方が良いことがあります。
| ケース | 対処 | 理由 |
|---|---|---|
| 質問が短すぎる(10文字未満) | 次の往復と結合 | 「はい」「わかりました」などの相槌は単独チャンクとして無意味 |
| 応答が長すぎる(5000文字超) | そのまま保存 | 長い回答でも検索対象として有用。分割は不要 |
| コードレビュー・デバッグの連続往復 | 同一 session_id でグルーピング | 「このセッションの流れ全体」を取り出す際に有用 |
import json
import uuid
from pathlib import Path
from datetime import datetime, timezone
def load_session_log(project_dir: str) -> list[dict]:
"""~/.claude/projects/{project}/ 以下の最新セッションログを読み込む。"""
base = Path(project_dir)
# セッションログは更新日時が新しいものを使用
logs = sorted(base.glob("*.jsonl"), key=lambda p: p.stat().st_mtime, reverse=True)
if not logs:
return []
chunks = []
with open(logs[0], encoding="utf-8") as f:
for line in f:
try:
chunks.append(json.loads(line))
except json.JSONDecodeError:
continue
return chunks
def extract_qa_pairs(log_entries: list[dict]) -> list[dict]:
"""
セッションログから Q&A ペアを抽出する。
- role="user" の直後に role="assistant" が来るペアを1チャンクとする。
- 質問が10文字未満のペアはスキップ。
"""
session_id = str(uuid.uuid4())
pairs = []
i = 0
while i < len(log_entries) - 1:
entry = log_entries[i]
next_entry = log_entries[i + 1]
# ユーザー→AI の順のペアを探す
if (entry.get("type") == "user" and
next_entry.get("type") == "assistant"):
question = _extract_text(entry)
answer = _extract_text(next_entry)
ts = entry.get("timestamp") or datetime.now(timezone.utc).isoformat()
if len(question) >= 10 and len(answer) >= 10:
pairs.append({
"id": str(uuid.uuid4()),
"session_id": session_id,
"timestamp": ts,
"question": question[:2000], # 上限2000文字
"answer": answer[:4000], # 上限4000文字
})
i += 2
else:
i += 1
return pairs
def _extract_text(entry: dict) -> str:
"""メッセージエントリからテキストを取り出す。"""
content = entry.get("message", {}).get("content", "")
if isinstance(content, str):
return content.strip()
if isinstance(content, list):
# content がブロックリストの場合(tool_use 等が含まれる)
texts = [b.get("text","") for b in content if b.get("type") == "text"]
return " ".join(texts).strip()
return ""
ハイブリッド検索の実装:RRF と時間減衰
記憶を引き出す検索エンジンは、FTS5(キーワード)とベクトル検索(意味)を組み合わせたハイブリッド方式です。それぞれが補い合うことで、「正確な固有名詞検索」と「あいまいな意味検索」の両方に対応します。
| 検索方式 | 得意なケース | 苦手なケース |
|---|---|---|
| FTS5(キーワード) | エラーコード・コマンド名・ライブラリ名など正確な文字列 | 「あの設計の話」「似たような問題」など意味的な参照 |
| ベクトル検索(意味) | 「以前試したアプローチ」「似たような実装」など意味的な近さ | 「sqlite-vec 0.1.6」など固有の文字列 |
RRF によるスコア統合
FTS5 と ベクトル検索の結果をそのまま足し合わせることはできません。FTS5 の rank はマイナス値(-1.0 前後)、ベクトル検索の距離は 0〜2 のコサイン距離で、スケールが全く異なるためです。
RRF(Reciprocal Rank Fusion)はランク番号だけを使うため、スコアのスケール差を気にせずに統合できます。計算式は 1 / (k + rank)(k=60 が一般的)で、1位が最もスコアが高くなります。
import json
import math
from datetime import datetime, timezone
def hybrid_search(
conn,
query: str,
query_embedding: list[float],
top_k: int = 5,
rrf_k: int = 60,
half_life_days: float = 30.0,
project: str | None = None,
) -> list[dict]:
"""
FTS5 + ベクトル検索を RRF で統合し、時間減衰を乗算して返す。
project を指定するとそのプロジェクトの記憶のみを対象にする。
"""
project_filter = f"AND project = '{project}'" if project else ""
# --- FTS5 キーワード検索 ---
fts_rows = conn.execute(
f"""SELECT id, project, machine, timestamp, question, answer
FROM memory_fts
WHERE memory_fts MATCH ? {project_filter}
ORDER BY rank
LIMIT ?""",
(query, top_k * 4)
).fetchall()
# --- ベクトル検索 ---
vec_rows = conn.execute(
f"""SELECT f.id, f.project, f.machine, f.timestamp, f.question, f.answer,
vec_distance_cosine(v.embedding, ?) AS distance
FROM memory_vec v
JOIN memory_fts f ON v.id = f.id
WHERE 1=1 {project_filter.replace("project", "f.project")}
ORDER BY distance ASC
LIMIT ?""",
(json.dumps(query_embedding), top_k * 4)
).fetchall()
# --- RRF スコアを計算 ---
scores: dict[str, dict] = {}
for rank, row in enumerate(fts_rows):
r = dict(row)
scores[r["id"]] = {"data": r, "rrf": 1.0 / (rrf_k + rank)}
for rank, row in enumerate(vec_rows):
r = dict(row)
if r["id"] not in scores:
scores[r["id"]] = {"data": r, "rrf": 0.0}
scores[r["id"]]["rrf"] += 1.0 / (rrf_k + rank)
# --- 時間減衰を乗算(直近の記憶を優先)---
for entry in scores.values():
decay = _time_decay(entry["data"]["timestamp"], half_life_days)
entry["final_score"] = entry["rrf"] * decay
ranked = sorted(scores.values(), key=lambda x: x["final_score"], reverse=True)
return [e["data"] for e in ranked[:top_k]]
def _time_decay(timestamp_str: str, half_life_days: float) -> float:
"""
半減期を使った時間減衰。
経過日数が half_life_days になるとスコアが 0.5 になる。
30日後 → 0.50、60日後 → 0.25、90日後 → 0.125
"""
try:
ts = datetime.fromisoformat(timestamp_str.replace("Z", "+00:00"))
now = datetime.now(timezone.utc)
elapsed = (now - ts).total_seconds() / 86400.0
return math.pow(0.5, elapsed / half_life_days)
except Exception:
return 1.0
半減期を30日に設定すると1ヶ月前の記憶のスコアが半分になります。「あの時の話」という参照が多い場合は半減期を60日に延ばし、常に最新の文脈を重視したい場合は14日に縮めるなど、プロジェクトの性質に合わせて調整できます。
Hook 設定:セッション開始・終了を自動化する
Claude Code の Hooks 機能を使って、セッション管理を自動化します。SessionStart と Stop の2点に処理を差し込みます。settings.json に追記するだけで動作します。
{
"env": {
"MEMORY_DIR": "C:/Users/yourname/memory-engine"
},
"hooks": {
"SessionStart": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "cd \"${MEMORY_DIR}\" && git pull --quiet --rebase && uv run python -m src session-start --inject"
}
]
}
],
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "cd \"${MEMORY_DIR}\" && uv run python -m src session-end && git add export/ && git commit -m \"memory: session \"$(date +%Y%m%d-%H%M%S)\" \" --quiet && git push --quiet"
}
]
}
]
}
}
MEMORY_DIR にはフォワードスラッシュを使うか、WSL パス(/mnt/c/...)を使ってください。バックスラッシュはシェル変数展開で問題を起こすことがあります。SessionStart の処理内容
@cli.command("session-start")
@click.option("--project", default="main")
@click.option("--inject", is_flag=True,
help="直近の記憶サマリーをstdoutに出力しセッション開始時に注入する")
def session_start(project: str, inject: bool):
"""
1. git pull は Hook コマンド内で実行済み
2. 当月の全JSONLをSQLiteに再構築(モデルロードなし・embedはJSONLから読む)
3. --inject のときだけ直近5件をstdoutへ(セッション冒頭に表示される)
"""
cfg = load_config()
# embedがJSONLに保存されているため load_model=False で高速再構築
db.rebuild_from_jsonl(cfg, project=project, load_model=False)
if inject:
recent = db.get_recent(cfg, project=project, limit=5)
if recent:
print("\n=== 直近の会話記憶(自動注入) ===")
for r in recent:
date = r["timestamp"][:10]
mach = r.get("machine", "?")
print(f"\n[{date} / {mach}]")
print(f"Q: {r['question'][:100]}...")
print(f"A: {r['answer'][:150]}...")
print("=== ここまで ===\n")
Stop の処理内容
@cli.command("session-end")
@click.option("--project", default="main")
def session_end(project: str):
"""
1. セッションログを読み込んでQ&Aチャンクに分割
2. Ruri v3-310mでベクトルを計算(ここだけモデルをロード)
3. SQLiteとJSONLに保存(冪等:同じidは上書き)
4. git commit/push はHookコマンド内で実行
"""
cfg = load_config()
project_dir = cfg.get("claude_projects_dir", "~/.claude/projects")
log_entries = chunker.load_session_log(os.path.expanduser(project_dir))
pairs = chunker.extract_qa_pairs(log_entries)
if not pairs:
print("[memory] 保存するチャンクがありません。")
return
# モデルロードはここだけ(セッション開始時は不要)
model = embedder.load()
conn = db.open_db(cfg)
jsonl = export.get_jsonl_path(cfg, project) # 例: export/2026-03_desktop-win.jsonl
saved = 0
for pair in pairs:
pair["project"] = project
pair["machine"] = cfg["machine_name"]
text = f"{pair['question']} {pair['answer']}"
emb = embedder.embed_texts([text], model)[0]
pair["embedding"] = emb
db.insert_chunk(conn, pair, emb)
export.append_jsonl(jsonl, pair)
saved += 1
conn.close()
print(f"[memory] {saved}件の記憶を保存しました → {jsonl}")
Skill 設定:必要なときだけ記憶を引き出す
毎回すべての記憶をコンテキストに注入するのは非効率です。Claude Code の Skill 機能を使って、「思い出して」と言われたときだけ検索を実行する設計にします。
---
name: memory-recall
description: |
過去の会話記憶をハイブリッド検索で引き出す。
「思い出して」「前に話した」「あの時の結論は」「覚えている?」
などのトリガーが出たとき使う。
検索はローカルSQLiteで実行するためLLMのAPIコストはゼロ。
allowed-tools:
- Bash
---
# 記憶の検索
## 手順
1. ユーザーが参照したい内容をクエリとして抽出する
2. 以下のコマンドを実行する:
```
cd "${MEMORY_DIR}" && uv run python -m src search "クエリ"
```
3. 返ってきた記憶の中から関連するものを選んでユーザーに提示する
4. 記憶の日付・デバイスも一緒に伝える(「〇月〇日にWindowsで話した内容です」)
## 検索オプション
- `--top-k 10`:より多くの候補を取得(デフォルト5)
- `--project work`:特定プロジェクトのみ対象
- `--half-life 60`:時間減衰を緩め(デフォルト30日)
## 注意
- 記憶が見つからない場合は「該当する記憶がありません」と正直に伝える
- 古い記憶(半年以上前)は情報が古い可能性があると注記する
@cli.command("search")
@click.argument("query")
@click.option("--project", default=None, help="プロジェクトでフィルタ")
@click.option("--top-k", default=5)
@click.option("--half-life", default=30.0)
def search_cmd(query: str, project: str | None, top_k: int, half_life: float):
"""ハイブリッド検索を実行して関連記憶を返す(APIコストゼロ)。"""
cfg = load_config()
model = embedder.load()
qemb = embedder.embed_query(query, model)
conn = db.open_db(cfg)
results = search.hybrid_search(conn, query, qemb,
top_k=top_k,
half_life_days=half_life,
project=project)
conn.close()
if not results:
print("該当する記憶が見つかりませんでした。")
return
for i, r in enumerate(results, 1):
date = r["timestamp"][:10]
mach = r.get("machine", "?")
proj = r.get("project", "?")
print(f"\n[{i}] {date} / {mach} / project:{proj}")
print(f"Q: {r['question']}")
print(f"A: {r['answer'][:300]}..." if len(r['answer']) > 300 else f"A: {r['answer']}")
月次アーカイブ:データ量を制御する
JSONL にベクトルを含めるため、データが蓄積するとファイルが肥大化します。目安として1日10〜20チャンクを保存した場合、1ヶ月分で約5〜12MB です。Git 管理下のファイルサイズとして1〜2ヶ月分は問題ありませんが、年単位での蓄積には月次アーカイブを設けます。
| 期間 | チャンク数(目安) | JSONL サイズ(ベクトル込み) | 対処 |
|---|---|---|---|
| 1ヶ月 | 300〜600件 | 4〜8 MB | そのまま Git 管理 |
| 3ヶ月 | 900〜1800件 | 12〜25 MB | そのまま Git 管理(問題なし) |
| 1年 | 3600〜7200件 | 50〜100 MB | 月次アーカイブを推奨 |
月次アーカイブは「先月以前の JSONL を archive.db(SQLite)にマージしてクラウドストレージに退避し、ローカルには当月分だけ残す」という運用です。
# 月初めに手動実行、またはタスクスケジューラ/launchd で自動化
cd "${MEMORY_DIR}" && uv run python -m src monthly-merge
アーカイブ後も古い記憶を検索できるよう、SQLite の ATTACH DATABASE で当月 DB とアーカイブ DB を結合して横断検索します。検索側のコードに1行追加するだけで対応できます。
-- クラウドストレージ上のアーカイブDBをアタッチ ATTACH DATABASE "/path/to/cloud/archive.db" AS arc; -- 当月 + アーカイブを UNION して検索 SELECT * FROM memory_fts WHERE memory_fts MATCH ? UNION ALL SELECT * FROM arc.memory_fts WHERE arc.memory_fts MATCH ? ORDER BY timestamp DESC;
冪等性と障害対応:壊れても復元できる設計
このシステムの最大の特長はすべて JSONL から再構築できることです。SQLite が壊れても、JSONL さえ残っていれば完全に復元できます。
| 障害 | 影響 | 復元方法 |
|---|---|---|
| SQLite が壊れた | セッション開始時に検索不可 | uv run python -m src rebuild で JSONL から再構築(1〜2分) |
| git push に失敗 | 他デバイスへの反映が遅延 | JSONL はローカルに保存済み。次回 SessionStart の git pull/push で同期 |
| 誤った記憶を保存した | 検索に不要な情報が含まれる | JSONL から該当行を削除して rebuild |
| デバイスを買い替えた | 新デバイスに記憶がない | リポジトリをクローンして rebuild。全記憶が復元される |
@cli.command("rebuild")
@click.option("--project", default=None)
@click.option("--with-model", is_flag=True,
help="embeddingがないJSONLレコードも再計算する(時間がかかる)")
def rebuild(project: str | None, with_model: bool):
"""
全JSONLからSQLiteを完全再構築する。
DBが破損した場合や新しいデバイスへの移行時に使用する。
"""
cfg = load_config()
model = embedder.load() if with_model else None
conn = db.open_db(cfg, recreate=True) # テーブルを作り直す
jsonl_dir = Path(cfg["export_dir"])
total = 0
for jsonl_path in sorted(jsonl_dir.glob("*.jsonl")):
if project and f"_{project}_" not in jsonl_path.name:
continue
for rec in export.iter_jsonl(jsonl_path):
emb = rec.get("embedding")
if not emb:
if not model:
continue # --with-model なしはスキップ
text = f"{rec['question']} {rec['answer']}"
emb = embedder.embed_texts([text], model)[0]
db.insert_chunk(conn, rec, emb)
total += 1
conn.close()
print(f"[memory] 再構築完了:{total}件")
プロジェクト構成とセットアップ
memory-engine/
pyproject.toml # プロジェクト設定・依存パッケージ
config.toml # デバイス固有設定(machine_name等)
.gitignore # .cache/・*.db を除外
.gitattributes # *.jsonl を LF に統一
export/ # JSONL ファイル(Git管理される正本)
2026-03_desktop-win.jsonl
2026-03_laptop-mac.jsonl
.cache/ # SQLiteキャッシュ(Git管理外)
memory.db
src/
__init__.py
__main__.py # CLI(session-start/end, search, rebuild)
db.py # SQLite操作(open_db, insert_chunk, rebuild_from_jsonl)
search.py # ハイブリッド検索(hybrid_search, _time_decay)
export.py # JSONL操作(get_jsonl_path, append_jsonl, iter_jsonl)
embedder.py # Ruri v3-310m(load, embed_texts, embed_query)
chunker.py # チャンク化(load_session_log, extract_qa_pairs)
[project]
name = "memory-engine"
version = "0.1.0"
requires-python = ">=3.11"
dependencies = [
"sentence-transformers>=3.0", # Ruri v3-310m のロード・推論
"sqlite-vec>=0.1.6", # ベクトル検索(SQLite拡張)
"click>=8.0", # CLI フレームワーク
]
[project.scripts]
memory = "src.__main__:cli"
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
# 1. uv のインストール(まだの場合) curl -LsSf https://astral.sh/uv/install.sh | sh # Windows: powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex" # 2. リポジトリをクローン(または新規作成) git clone git@github.com:your-account/memory-engine.git cd memory-engine # 3. 依存パッケージをインストール uv sync # 4. 設定ファイルを編集(machine_name を現在のデバイス名に変更) # config.toml の machine_name を設定 # 5. 動作確認 uv run python -m src --help # 6. 初回DB構築(すでにJSONLがある場合) uv run python -m src rebuild
.cache/ *.db __pycache__/ .venv/
*.jsonl text eol=lf *.toml text eol=lf *.md text eol=lf *.py text eol=lf
よくある質問
cl-nagoya/ruri-v3-30m(30Mパラメータ)を試してみてください。project フィールドで区分けします。検索時に --project work のようにフィルタをかけることで、特定プロジェクトの記憶だけを対象にできます。プロジェクトを完全に分離したい場合(セキュリティ上の理由など)は、リポジトリ自体を分けて config.toml を使い分けるか、settings.json の MEMORY_DIR をプロジェクトごとに切り替えます。~/.claude/projects/ 配下に、プロジェクトパスをエンコードしたディレクトリ名で保存されています。各ディレクトリ内に JSONL 形式のセッションログが保存されており、Stop Hook が発火した時点で最新のものが読み込み可能です。ログには type: user / type: assistant のエントリが含まれ、tool_use や tool_result も混在します。チャンク化時は type: text のブロックだけを抽出します。まとめ
このシステムの設計原則をまとめます。
| 設計の決定 | 選択 | 理由 |
|---|---|---|
| データの正本 | JSONL(テキスト) | Git での差分管理・コンフリクト解決・可視性 |
| ローカルキャッシュ | SQLite(FTS5 + sqlite-vec) | キーワード検索とベクトル検索の両立 |
| 複数デバイスの同期 | デバイス別 JSONL + Git | コンフリクトを構造的に排除 |
| ベクトルの保存場所 | JSONL に埋め込む | セッション開始時のモデルロードを不要にする |
| スコア統合 | RRF + 時間減衰 | スケール差のない統合・古い記憶の抑制 |
| モデルのロード | セッション終了時のみ | 開始時のオーバーヘッドをゼロに抑える |
| 障害対応 | JSONL から常に再構築可能 | どんな障害でも rebuild コマンドで復元 |
「AI との会話は消えてしまうもの」という前提を変えることで、Claude Code が本当の意味での「長期パートナー」になります。設計の経緯・却下した案の理由・バグ調査の試行錯誤——これらをデバイスをまたいで参照できるようになったとき、AI との協働の質が変わります。Hooks・Skills・auto-memory と組み合わせて、自分に最適なメモリシステムを構築してください。
