JavaScriptの文字列は内部的にUTF-16でエンコードされており、絵文字や一部の漢字はサロゲートペア(2つのコードユニット)で表現されます。従来の charCodeAt() ではこれらの文字を正しく扱えませんが、codePointAt() を使えば正確なUnicodeコードポイントを取得できます。
この記事では、codePointAt() の基本から charCodeAt() との違い、サロゲートペアの仕組み、絵文字・結合文字の実務的な処理パターンまで体系的に解説します。
codePointAt() の基本構文
codePointAt() は文字列の指定位置にある文字のUnicodeコードポイントを返すメソッドです(ES2015で追加)。
// 構文 string.codePointAt(index) // 基本的な使用例 const str = 'ABC'; console.log(str.codePointAt(0)); // 65("A" のコードポイント) console.log(str.codePointAt(1)); // 66("B" のコードポイント) console.log(str.codePointAt(2)); // 67("C" のコードポイント) // サロゲートペア文字 const emoji = '?'; console.log(emoji.codePointAt(0)); // 127881(U+1F389 正しいコードポイント) // 範囲外 console.log(str.codePointAt(99)); // undefined
? ポイント
codePointAt() はサロゲートペアを正しく解釈し、完全なUnicodeコードポイント(0〜1,114,111)を返します。通常のBMP文字では charCodeAt() と同じ値を返します。
サロゲートペアとは? UTF-16の仕組み
Unicodeには100万以上の文字が定義されていますが、JavaScriptの文字列はUTF-16(16ビット=65,536通り)でエンコードされています。65,536に収まらない文字は、2つのコードユニットを組み合わせたサロゲートペアで表現されます。
// BMP文字の例(1コードユニット) const a = 'あ'; // U+3042 console.log(a.length); // 1 // サロゲートペア文字の例(2コードユニット) const tsuchi = '?'; // U+20BB7 console.log(tsuchi.length); // 2(見た目は1文字だが内部的には2つ) // 絵文字もサロゲートペア const fire = '?'; console.log(fire.length); // 2 // 内部的なUTF-16の表現を確認 console.log(tsuchi.charCodeAt(0).toString(16)); // "d842"(上位サロゲート) console.log(tsuchi.charCodeAt(1).toString(16)); // "dfb7"(下位サロゲート)
サロゲートペアのコードポイント計算
サロゲートペアからコードポイントへの変換は以下の式で計算されます。codePointAt() はこの計算を自動的に行います。
// サロゲートペア → コードポイントの計算式 // codePoint = (上位 - 0xD800) × 0x400 + (下位 - 0xDC00) + 0x10000 const high = 0xD842; // 「?」の上位サロゲート const low = 0xDFB7; // 「?」の下位サロゲート const codePoint = (high - 0xD800) * 0x400 + (low - 0xDC00) + 0x10000; console.log(codePoint); // 134071 console.log(codePoint.toString(16)); // "20bb7" // codePointAt() を使えば自動計算される console.log('?'.codePointAt(0)); // 134071 console.log('?'.codePointAt(0).toString(16)); // "20bb7"
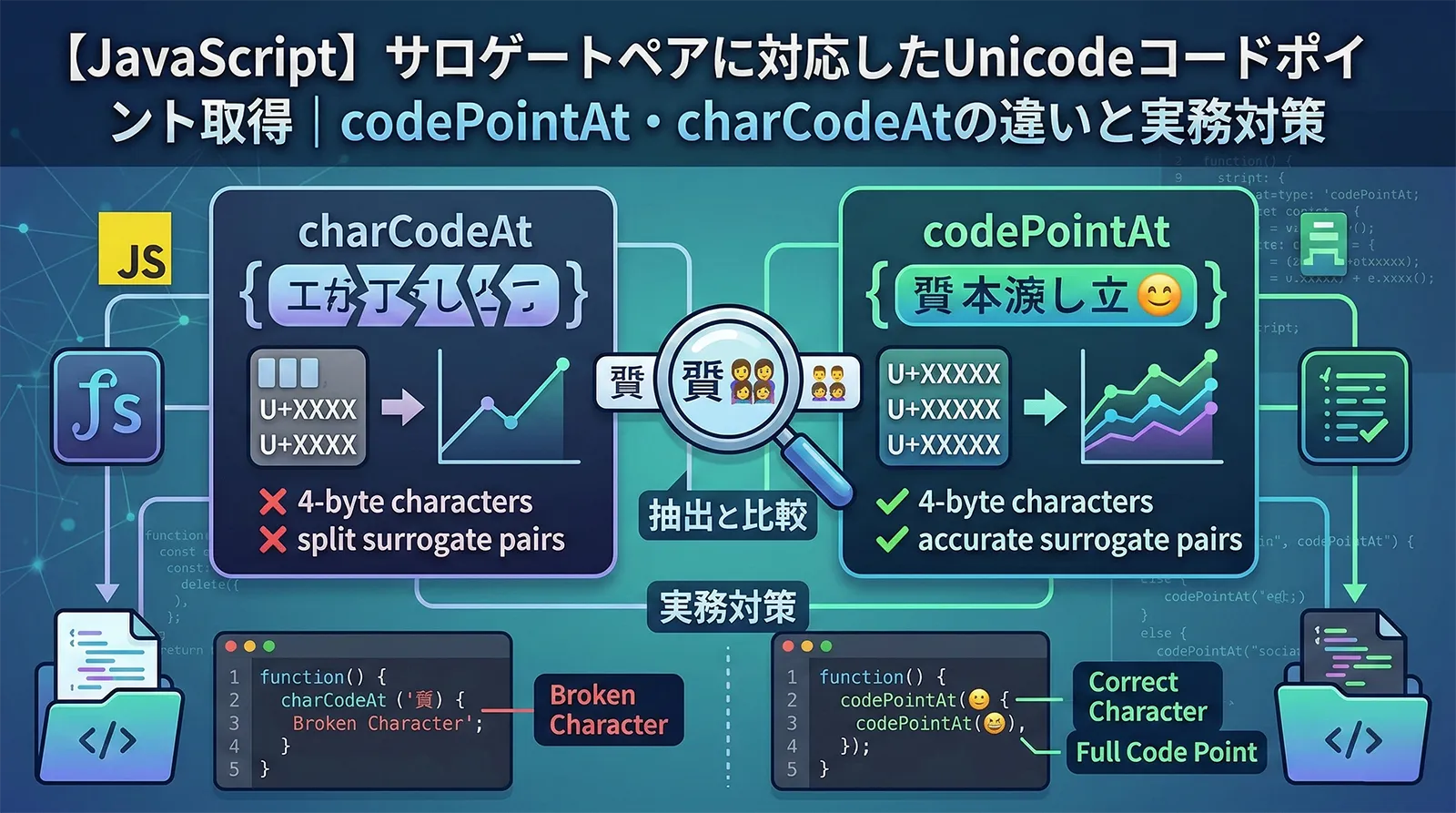
charCodeAt() と codePointAt() の違い
charCodeAt() と codePointAt() はどちらも文字コードを返しますが、サロゲートペア文字での挙動が大きく異なります。
具体的な数値の違い
BMP内の文字では両者は同じ値を返しますが、サロゲートペア文字では結果が大きく異なります。
コードで比較してみる
const str = '?野家'; // charCodeAt() は上位サロゲートのみを返す console.log(str.charCodeAt(0)); // 55362(0xD842 上位サロゲート) console.log(str.charCodeAt(1)); // 57271(0xDFB7 下位サロゲート) console.log(str.charCodeAt(2)); // 37326("野" 通常の文字) // codePointAt() は正しいコードポイントを返す console.log(str.codePointAt(0)); // 134071(0x20BB7 正しいコードポイント) console.log(str.codePointAt(1)); // 57271(下位サロゲートの値) console.log(str.codePointAt(2)); // 37326("野" 通常の文字)
⚠️ 注意: codePointAt() のインデックスの罠
codePointAt(1) はサロゲートペアの「下位サロゲートの位置」を指すため、下位サロゲートの値が返ります。文字単位で正しくイテレートするには for...of を使いましょう。
// ❌ for文 + codePointAt: インデックスが正しく進まない const str = '?野'; for (let i = 0; i < str.length; i++) { console.log(i, str.codePointAt(i)); } // 0 134071 ← 正しい「?」のコードポイント // 1 57271 ← 下位サロゲートの値(意味のない値) // 2 37326 ← 「野」のコードポイント // ✅ for文で使う場合はサロゲートペアを手動でスキップ for (let i = 0; i < str.length; ) { const cp = str.codePointAt(i); console.log(i, cp, String.fromCodePoint(cp)); i += cp > 0xFFFF ? 2 : 1; // サロゲートペアなら2つ進む } // 0 134071 "?" // 2 37326 "野"
String.fromCodePoint() で文字に変換
codePointAt() の逆操作として、コードポイントから文字を生成する String.fromCodePoint() があります。従来の String.fromCharCode() と比較してみましょう。
// BMP文字: どちらも同じ結果 console.log(String.fromCharCode(65)); // "A" console.log(String.fromCodePoint(65)); // "A" // サロゲートペア文字: fromCharCode は正しく変換できない console.log(String.fromCharCode(134071)); // "ꮷ"(間違った文字) console.log(String.fromCodePoint(134071)); // "?"(正しい文字) // fromCharCode でサロゲートペアを正しく変換するにはペアを渡す必要がある console.log(String.fromCharCode(0xD842, 0xDFB7)); // "?"(ペアで渡せば正しい) // fromCodePoint は複数のコードポイントをまとめて変換可能 console.log(String.fromCodePoint(134071, 37326, 23478)); // "?野家"
コードポイントの16進数表記
// コードポイント → 16進数表記(U+XXXX 形式) function toUnicodeNotation(char) { const cp = char.codePointAt(0); return 'U+' + cp.toString(16).toUpperCase().padStart(4, '0'); } console.log(toUnicodeNotation('A')); // "U+0041" console.log(toUnicodeNotation('あ')); // "U+3042" console.log(toUnicodeNotation('?')); // "U+20BB7" console.log(toUnicodeNotation('?')); // "U+1F389" // Unicodeエスケープシーケンス(u{XXXX}) console.log('u{20BB7}'); // "?"(ES2015のUnicodeエスケープ) console.log('u{1F389}'); // "?" console.log('u{3042}'); // "あ"
サロゲートペア文字を正しく扱う方法
文字列を1文字ずつ処理する場合、通常の for ループや charAt() ではサロゲートペアが壊れます。以下の方法を使いましょう。
方法1: for…of ループ
for...of はUnicodeのコードポイント単位でイテレートするため、サロゲートペアを正しく処理できます。
const str = '?野家?'; // ❌ for ループ: サロゲートペアが壊れる for (let i = 0; i < str.length; i++) { console.log(str[i]); } // "ud842" "udfb7" "野" "家" "ud83c" "udf5c"(6回、文字化け) // ✅ for...of: コードポイント単位で正しくイテレート for (const char of str) { console.log(char, char.codePointAt(0)); } // "?" 134071 // "野" 37326 // "家" 23478 // "?" 127836
方法2: スプレッド構文 / Array.from()
const str = 'Hello?World'; // スプレッド構文でコードポイント単位の配列に変換 const chars = [...str]; console.log(chars); // ["H","e","l","l","o","?","W","o","r","l","d"] console.log(chars.length); // 11(正しい文字数) console.log(str.length); // 12(UTF-16コードユニット数) // Array.from() でも同様 const chars2 = Array.from(str); console.log(chars2.length); // 11 // 各文字のコードポイントを取得 const codePoints = [...str].map(c => c.codePointAt(0)); console.log(codePoints); // [72, 101, 108, 108, 111, 127757, 87, 111, 114, 108, 100]
方法3: 正規表現の u フラグ
正規表現に u(Unicode)フラグを付けると、サロゲートペアを1文字として扱えます。
const str = 'ABC?DEF'; // u フラグなし: . はサロゲートペアの半分にマッチ console.log(str.match(/./g).length); // 8(絵文字が2文字扱い) // u フラグあり: . はコードポイント単位にマッチ console.log(str.match(/./gu).length); // 7(正しい文字数) // Unicodeプロパティエスケープ(p{...})も使える const emojis = 'Hello?World?!'.match(/p{Emoji_Presentation}/gu); console.log(emojis); // ["?", "?"] // 漢字(CJK統合漢字拡張Bなど)にマッチ const kanji = '?野家'.match(/p{Script=Han}/gu); console.log(kanji); // ["?", "野", "家"] // ひらがな・カタカナにもマッチ可能 const text = 'Hello こんにちは カタカナ 漢字'; console.log(text.match(/p{Script=Hiragana}+/gu)); // ["こんにちは"] console.log(text.match(/p{Script=Katakana}+/gu)); // ["カタカナ"]
Intl.Segmenter で書記素クラスタ単位の処理
スプレッド構文や for...of はサロゲートペアには対応しますが、ZWJシーケンス(Zero Width Joiner)で結合された複合絵文字や結合文字は正しく扱えません。「見た目通りの1文字」で処理するには Intl.Segmenter を使います。
// 複合絵文字(ZWJシーケンス)の例 const family = '????'; console.log(family.length); // 11(UTF-16コードユニット数) console.log([...family].length); // 7(コードポイント数: ? + ZWJ + ? + ZWJ + ? + ZWJ + ?) // Intl.Segmenter で書記素クラスタ単位に分割 const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' }); const segments = [...segmenter.segment(family)]; console.log(segments.length); // 1(正しく1文字) console.log(segments[0].segment); // "????"
// さまざまな複合文字の例 const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' }); // 国旗絵文字(Regional Indicator) const flag = '??'; console.log([...flag].length); // 2(2つのRegional Indicator) console.log([...segmenter.segment(flag)].length); // 1(正しく1文字) // 肌色修飾子付き絵文字 const wave = '??'; console.log([...wave].length); // 2(絵文字 + 修飾子) console.log([...segmenter.segment(wave)].length); // 1(正しく1文字) // 結合文字(アクセント記号) const cafe = 'café'; // "e" + 結合アクセント(U+0301) console.log([...cafe].length); // 5(e と ́ が別々にカウント) console.log([...segmenter.segment(cafe)].length); // 4(正しく4文字)
文字の粒度まとめ
? 使い分けの指針
- ASCII文字のみ →
.lengthで十分 - 絵文字・特殊漢字を含む →
[...str].lengthまたはfor...of - 複合絵文字・結合文字を含む →
Intl.Segmenterを使用
Unicode正規化(NFC / NFD)
同じ見た目の文字でも、Unicodeでは複数の表現方法がある場合があります。たとえば「が」は「合成済み文字(1コードポイント)」と「か + 結合濁点(2コードポイント)」の2通りで表現できます。String.prototype.normalize() で正規化しましょう。
// NFC: 合成済み形式(推奨) const nfc = 'u304C'; // "が"(合成済み、1コードポイント) // NFD: 分解形式 const nfd = 'u304Bu3099'; // "が"(か + 結合濁点、2コードポイント) // 見た目は同じだが、内部表現が違う console.log(nfc === nfd); // false ! console.log(nfc.length); // 1 console.log(nfd.length); // 2 // normalize() で正規化すれば一致する console.log(nfc.normalize('NFC') === nfd.normalize('NFC')); // true // 実務: 文字列比較の前に正規化する function safeCompare(a, b) { return a.normalize('NFC') === b.normalize('NFC'); } console.log(safeCompare(nfc, nfd)); // true
? 正規化形式の使い分け
- NFC(推奨): 合成済み形式に正規化。Webで最も一般的
- NFD: 分解形式に正規化。文字の構成要素を分析する場合に有用
- NFKC / NFKD: 互換正規化。全角英数→半角英数のような変換も含む
実務で使えるユーティリティ関数
サロゲートペア対応の文字数カウント
// コードポイント単位の文字数を取得 function countCodePoints(str) { return [...str].length; } // 書記素クラスタ単位の文字数を取得(最も正確) function countGraphemes(str) { const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' }); return [...segmenter.segment(str)].length; } const text = 'Hello??????'; console.log(text.length); // 20(UTF-16) console.log(countCodePoints(text)); // 14(コードポイント) console.log(countGraphemes(text)); // 7(見た目の文字数)
サロゲートペア判定関数
// 文字がサロゲートペアかどうかを判定 function isSurrogatePair(char) { return char.length === 2 && char.codePointAt(0) > 0xFFFF; } // 文字列にサロゲートペアが含まれるかを判定 function containsSurrogatePair(str) { return str.length !== [...str].length; } console.log(isSurrogatePair('?')); // true console.log(isSurrogatePair('あ')); // false console.log(containsSurrogatePair('Hello?')); // true console.log(containsSurrogatePair('Hello')); // false
孤立サロゲートの検出・除去
外部データやAPIレスポンスに、ペアが揃っていない孤立サロゲート(lone surrogate)が含まれることがあります。これを検出・除去する関数です。
// 孤立サロゲートが含まれるか判定 function hasLoneSurrogate(str) { for (let i = 0; i < str.length; i++) { const code = str.charCodeAt(i); if (code >= 0xD800 && code <= 0xDBFF) { // 上位サロゲート: 次が下位サロゲートでなければ孤立 const next = str.charCodeAt(i + 1); if (!(next >= 0xDC00 && next <= 0xDFFF)) return true; i++; // ペアをスキップ } else if (code >= 0xDC00 && code <= 0xDFFF) { return true; // 下位サロゲートが単独で出現 } } return false; } // 孤立サロゲートを除去してクリーンな文字列を返す function removeLoneSurrogates(str) { return str.replace(/[uD800-uDBFF](?![uDC00-uDFFF])|(?<![uD800-uDBFF])[uDC00-uDFFF]/g, ''); }
文字列の安全なスライス
// サロゲートペア対応の安全なスライス function safeSlice(str, start, end) { const chars = [...str]; return chars.slice(start, end).join(''); } const str = '?野家?定食'; // ❌ 通常の slice: サロゲートペアが壊れる console.log(str.slice(0, 3)); // "ud842udfb7野"(文字化け) // ✅ safeSlice: 正しくスライス console.log(safeSlice(str, 0, 3)); // "?野家" console.log(safeSlice(str, 3)); // "?定食"
文字列の安全な切り詰め(truncate)
// サロゲートペア対応の文字列切り詰め function truncate(str, maxLength, suffix = '...') { const chars = [...str]; if (chars.length <= maxLength) return str; return chars.slice(0, maxLength).join('') + suffix; } console.log(truncate('こんにちは?世界!', 5)); // "こんにちは..." console.log(truncate('Hello?World?!', 7)); // "Hello?W..."
全コードポイントの取得とUnicode情報表示
// 文字列の各文字のUnicode情報を表示 function analyzeString(str) { const result = []; for (const char of str) { const cp = char.codePointAt(0); result.push({ char, codePoint: cp, hex: 'U+' + cp.toString(16).toUpperCase().padStart(4, '0'), isSurrogate: cp > 0xFFFF, utf16Units: char.length, }); } return result; } console.table(analyzeString('?野家?')); // ┌─────────┬──────┬───────────┬─────────┬─────────────┬────────────┐ // │ (index) │ char │ codePoint │ hex │ isSurrogate │ utf16Units │ // ├─────────┼──────┼───────────┼─────────┼─────────────┼────────────┤ // │ 0 │ '?'│ 134071 │'U+20BB7'│ true │ 2 │ // │ 1 │ '野'│ 37326 │'U+91CE'│ false │ 1 │ // │ 2 │ '家'│ 23478 │'U+5BB6'│ false │ 1 │ // │ 3 │ '?'│ 127836 │'U+1F35C'│ true │ 2 │ // └─────────┴──────┴───────────┴─────────┴─────────────┴────────────┘
よくあるエラーと注意点
よくある質問(FAQ)
"?".length === 2。[...str].lengthまたはArray.from(str).lengthでサロゲートペアを1文字として正確にカウントできます。例:[..."Hello?"].length === 6。str.lengthは7になります(?が2カウント)。for(const char of str){ ... }。インデックスアクセス(str[i])やcharAt()はサロゲートペアを2つに分割して扱うため、絵文字を含む文字列では意図しない動作になります。まとめ
サロゲートペア文字を正しく扱うには、codePointAt() と String.fromCodePoint() のペアが基本です。文字列の走査には for...of、正規表現には u フラグ、複合絵文字には Intl.Segmenter を使いましょう。charCodeAt() / String.fromCharCode() はBMP内の文字にのみ安全に使えます。
関連記事
- 【JavaScript】文字のUnicodeコードポイントを取得する方法
- 【JavaScript】Unicodeコードポイントから文字列を生成する方法
- 【JavaScript】for-ofループでサロゲートペア文字列を抽出する方法
- 【JavaScript】文字列から任意の1文字を取得する方法
- 【JavaScript】文字コードを取得・変換する方法
- 【JavaScript】文字列からASCIIコードに変換する3つの方法
- 【JavaScript】ASCIIコードを文字列に変換する方法
- 【JavaScript】charAtメソッドの使い方
- 【JavaScript】文字列を配列に変換する split の完全ガイド