JavaScriptで文字列から特定の位置にある1文字を取得するには、charAt()・ブラケット記法 str[i]・at()(ES2022)の3つの方法があります。
この記事では、3つの方法の違い・使い分けを比較表付きで解説し、charCodeAt / codePointAt との関係、サロゲートペアの注意点、実務でよく使うパターンまで体系的にまとめます。
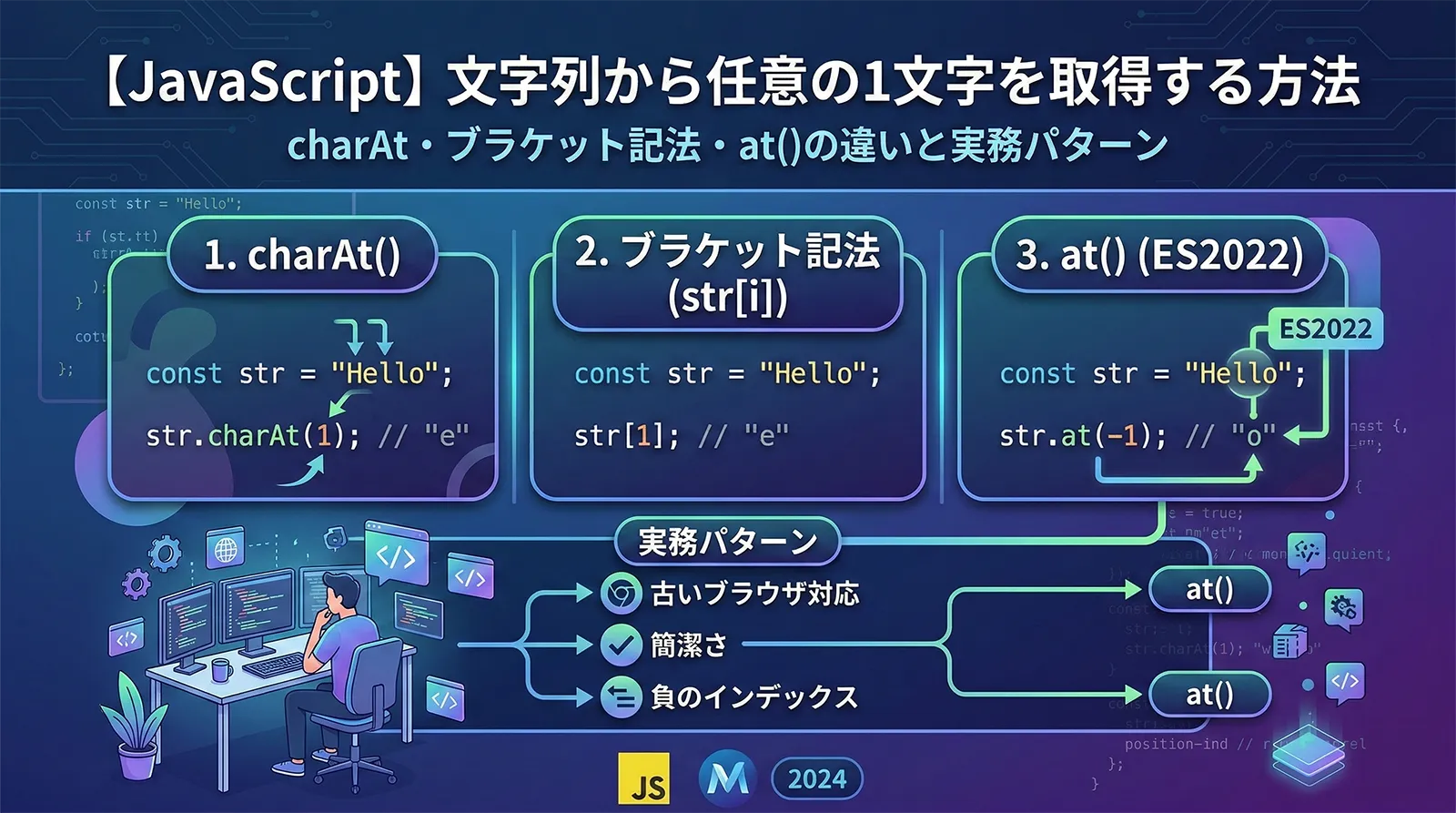
文字列から1文字を取得する3つの方法
JavaScriptでは、文字列の指定位置にある1文字を取得する方法が3つあります。それぞれの基本構文を確認しましょう。
1. charAt() メソッド
charAt() は文字列の指定位置の文字を返す、最も伝統的なメソッドです。
// 構文 string.charAt(index) // 使用例 const str = 'JavaScript'; console.log(str.charAt(0)); // "J" console.log(str.charAt(4)); // "S" console.log(str.charAt(99)); // ""(範囲外は空文字) console.log(str.charAt()); // "J"(引数省略時は0番目)
2. ブラケット記法 str[i]
配列のようにインデックスでアクセスする記法です。ES5以降のモダンな書き方として広く使われています。
// 構文 string[index] // 使用例 const str = 'JavaScript'; console.log(str[0]); // "J" console.log(str[4]); // "S" console.log(str[99]); // undefined(範囲外はundefined)
3. at() メソッド(ES2022)
at() はES2022で追加された最新のメソッドです。最大の特徴は負のインデックスに対応していることです。
// 構文 string.at(index) // 使用例 const str = 'JavaScript'; console.log(str.at(0)); // "J" console.log(str.at(-1)); // "t"(末尾の文字) console.log(str.at(-3)); // "i"(末尾から3番目) console.log(str.at(99)); // undefined(範囲外はundefined)
at() を使えば、従来の str.charAt(str.length - 1) を str.at(-1) と簡潔に書けます。
at() のポリフィル(レガシー環境向け)
IE11など at() が使えない環境では、以下のポリフィルを追加することで対応できます。
// String.prototype.at ポリフィル if (!String.prototype.at) { String.prototype.at = function(index) { const n = Math.trunc(index) || 0; const i = n >= 0 ? n : n + this.length; if (i < 0 || i >= this.length) return undefined; return this.charAt(i); }; }
3つの方法の違いを比較
3つの方法には、範囲外アクセス時の戻り値・負のインデックス対応・引数省略時の挙動などの違いがあります。
範囲外アクセスの挙動の違い
範囲外アクセス時の戻り値の違いは、条件分岐に影響します。実際のコードで確認してみましょう。
const str = 'ABC'; // charAt() は空文字を返す console.log(str.charAt(99)); // "" console.log(str.charAt(99) === ''); // true // ブラケット記法は undefined を返す console.log(str[99]); // undefined console.log(str[99] === undefined); // true // at() も undefined を返す console.log(str.at(99)); // undefined // 条件分岐での違い if (str.charAt(99)) { // 空文字は falsy → 実行されない } if (str[99] !== undefined) { // undefined チェックで安全に判定できる }
? 使い分けの指針
- 通常のアクセス → ブラケット記法
str[i]が最もシンプル - 末尾からのアクセス →
at(-1)が簡潔で可読性が高い - 範囲外で空文字がほしい場合 →
charAt()が便利
TypeScriptでの型の違い
TypeScriptを使っている場合、3つの方法で戻り値の型が異なる点に注意が必要です。
const str = 'Hello'; // charAt() → 常に string 型 const a: string = str.charAt(0); // OK // ブラケット記法 → string | undefined 型 const b: string = str[0]; // noUncheckedIndexedAccess が有効だとエラー const b2: string | undefined = str[0]; // 安全な書き方 // at() → string | undefined 型 const c: string | undefined = str.at(0); // 正しい型
? TypeScript Tips
TypeScriptで noUncheckedIndexedAccess を有効にしている場合、ブラケット記法と at() は string | undefined を返します。charAt() は常に string を返すため、型ガード不要で使えるメリットがあります。
charCodeAt / codePointAt との関係
「文字そのものを取得する」メソッドと「文字コードを取得する」メソッドは目的が異なります。それぞれの違いを理解しておくと、文字列操作の幅が広がります。
const str = 'ABC'; // 文字そのものを取得 console.log(str.charAt(0)); // "A"(文字) // UTF-16コードを取得 console.log(str.charCodeAt(0)); // 65("A"のUTF-16コード) // Unicodeコードポイントを取得 console.log(str.codePointAt(0)); // 65(基本ラテン文字は同じ値) // 文字コード → 文字に変換 console.log(String.fromCharCode(65)); // "A" console.log(String.fromCodePoint(65)); // "A"
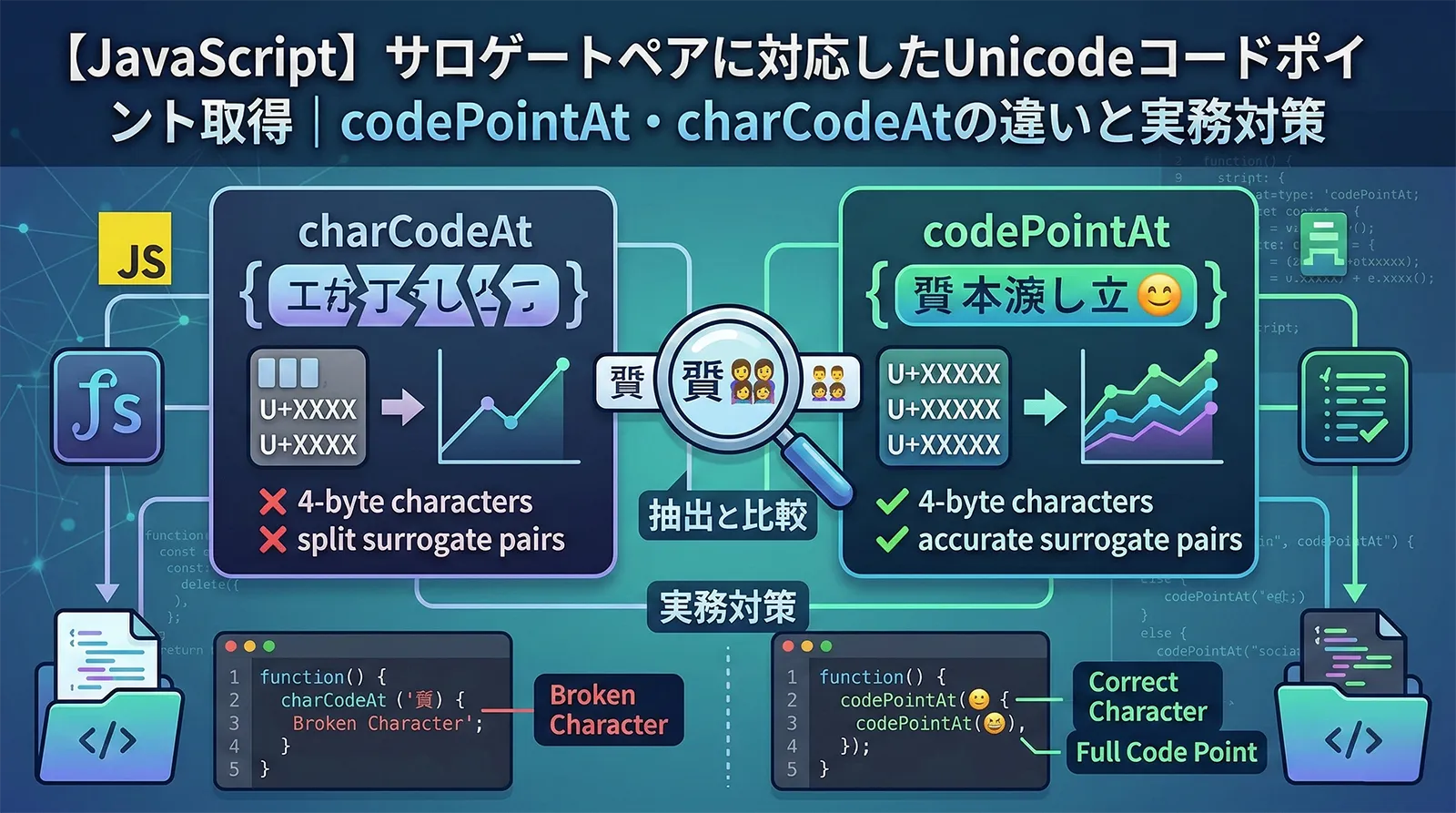
charCodeAt vs codePointAt の具体的な値の違い
基本的な文字(BMP内)では両者は同じ値を返しますが、サロゲートペア文字では大きく異なります。
サロゲートペア文字に注意
JavaScriptの文字列は内部的にUTF-16でエンコードされています。「?」(つちよし)や絵文字のような文字はサロゲートペア(2つのコードユニット)で表現されるため、charAt() やブラケット記法では正しく取得できない場合があります。
サロゲートペアで起きる問題
const str = '?野家'; // 「?」はサロゲートペア文字 // length も正しくカウントできない console.log(str.length); // 4(見た目は3文字なのに4) // charAt() は孤立サロゲートを返してしまう console.log(str.charAt(0)); // "ud842"(文字化け) console.log(str.charAt(1)); // "udfb7"(文字化け) // ブラケット記法も同様の問題 console.log(str[0]); // "ud842"(文字化け) // at() も同様 console.log(str.at(0)); // "ud842"(文字化け)
⚠️ 重要
charAt()・str[i]・at() はいずれもUTF-16のコードユニット単位で動作します。サロゲートペア文字(絵文字、一部の漢字など)を正しく扱うには、以下の方法を使いましょう。
解決策1: スプレッド構文で配列に変換
const str = '?野家'; // スプレッド構文はコードポイント単位で分割される const chars = [... str]; console.log(chars); // ["?", "野", "家"] console.log(chars.length); // 3(正しい文字数) console.log(chars[0]); // "?"(正しく取得できる)
解決策2: for…of ループ
const str = '?野家'; // for...of はコードポイント単位でイテレートする for (const char of str) { console.log(char); } // "?" // "野" // "家"
解決策3: codePointAt() で正しいコードポイントを取得
const str = '?野家'; // charCodeAt は上位サロゲートのみを返す console.log(str.charCodeAt(0)); // 55362(上位サロゲート 0xD842) // codePointAt はサロゲートペアを正しく解釈する console.log(str.codePointAt(0)); // 134071(正しいコードポイント U+20BB7) // コードポイントから文字を復元 console.log(String.fromCodePoint(134071)); // "?"
解決策4: Array.from() で分割
const str = 'Hello?World'; // Array.from() もコードポイント単位で分割できる const chars = Array.from(str); console.log(chars.length); // 11(正しい文字数) console.log(chars[5]); // "?"(正しく取得) // 比較: split('') ではサロゲートペアが壊れる const broken = str.split(''); console.log(broken.length); // 12(絵文字が2つに分割される) // 正規表現の u フラグ付き split なら正しく分割できる const correct = str.split(/(?:)/u); console.log(correct.length); // 11(絵文字も1要素として分割)
サロゲートペア対応のまとめ
Intl.Segmenter で書記素クラスタ単位の処理
スプレッド構文や for...of はサロゲートペアには対応しますが、結合文字(アクセント記号)や複合絵文字(???? など)は正しく扱えません。これらを「見た目通りの1文字」として扱うには Intl.Segmenter を使います。
const emoji = '????'; // 家族絵文字(ZWJシーケンス) // スプレッド構文では分解されてしまう console.log([...emoji]); // ["?", "", "?", "", "?", "", "?"](7要素に分解) // Intl.Segmenter なら1文字として認識 const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' }); const segments = [...segmenter.segment(emoji)]; console.log(segments.length); // 1(正しく1文字) console.log(segments[0].segment); // "????"
// 結合文字の例 const cafe = 'café'; // "e" + 結合アクセント(U+0301) console.log([...cafe]); // ["c","a","f","e","́"](5要素に分解) const segmenter = new Intl.Segmenter('ja', { granularity: 'grapheme' }); const graphemes = [...segmenter.segment(cafe)].map(s => s.segment); console.log(graphemes); // ["c","a","f","é"](4文字として正しく認識)
? 文字の粒度と使い分け
- ASCII文字のみ →
charAt()/str[i]で十分 - 絵文字・漢字を含む → スプレッド構文
[...str]またはfor...of - 結合文字・複合絵文字を含む →
Intl.Segmenterを使用
文字列を1文字ずつ走査する方法の比較
文字列を1文字ずつ処理する方法は複数あります。目的に応じて最適な方法を選びましょう。
方法1: for文 + charAt() / ブラケット記法
const str = 'Hello'; // for文 + charAt() for (let i = 0; i < str.length; i++) { console.log(str.charAt(i)); } // for文 + ブラケット記法(こちらのほうが簡潔) for (let i = 0; i < str.length; i++) { console.log(str[i]); }
方法2: for…of(サロゲートペア対応)
const str = 'Hello?'; // for...of はコードポイント単位でイテレート for (const char of str) { console.log(char); } // "H" "e" "l" "l" "o" "?"(絵文字も正しく1文字として処理)
方法3: スプレッド構文 + forEach
const str = 'Hello?'; // インデックスも必要な場合 [...str].forEach((char, index) => { console.log(`${index}: ${char}`); }); // "0: H" "1: e" "2: l" "3: l" "4: o" "5: ?"
文字列走査方法の比較表
実務で使えるユースケース集
先頭文字・末尾文字の取得
const str = 'JavaScript'; // 先頭文字 const first = str[0]; // "J" const first2 = str.charAt(0); // "J" // 末尾文字 const last = str.at(-1); // "t"(最も簡潔) const last2 = str[str.length - 1]; // "t"(従来の方法) const last3 = str.charAt(str.length - 1); // "t"(charAt版)
先頭文字を大文字にする(capitalize)
function capitalize(str) { if (!str) return ''; return str[0].toUpperCase() + str.slice(1); } console.log(capitalize('hello')); // "Hello" console.log(capitalize('javaScript')); // "JavaScript"
入力バリデーション(先頭文字の判定)
// 先頭が英字かどうかを判定 function startsWithLetter(str) { const first = str[0]; return first && /[a-zA-Z]/.test(first); } console.log(startsWithLetter('Hello')); // true console.log(startsWithLetter('123abc')); // false console.log(startsWithLetter('')); // false // 末尾の文字で処理を分岐 function getFileType(path) { const lastChar = path.at(-1); if (lastChar === '/') return 'directory'; return 'file'; } console.log(getFileType('/home/user/')); // "directory" console.log(getFileType('/home/user/file.txt')); // "file"
イニシャルの抽出
// 名前からイニシャルを取得 function getInitials(name) { return name .split(' ') .map(word => word[0]) .join('') .toUpperCase(); } console.log(getInitials('John Smith')); // "JS" console.log(getInitials('Taro Yamada')); // "TY" console.log(getInitials('Mary Jane Watson')); // "MJW"
文字列のマスキング処理
// クレジットカード番号のマスキング function maskCard(number) { const last4 = number.slice(-4); return '**** **** **** ' + last4; } console.log(maskCard('4111111111111111')); // "**** **** **** 1111" // メールアドレスのマスキング function maskEmail(email) { const [local, domain] = email.split('@'); const first = local[0]; const last = local.at(-1); const masked = '*'.repeat(local.length - 2); return `${first}${masked}${last}@${domain}`; } console.log(maskEmail('taro@example.com')); // "t**o@example.com" console.log(maskEmail('hello@gmail.com')); // "h***o@gmail.com"
ランダム文字列の生成
// ランダムな英数字文字列を生成 function randomString(length) { const chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789'; let result = ''; for (let i = 0; i < length; i++) { const randomIndex = Math.floor(Math.random() * chars.length); result += chars[randomIndex]; } return result; } console.log(randomString(8)); // 例: "kT3xB9mZ" console.log(randomString(16)); // 例: "aB4cD8eF2gH1iJ7k"
回文(パリンドローム)判定
// 回文かどうかを判定 function isPalindrome(str) { const normalized = str.toLowerCase(); const len = normalized.length; for (let i = 0; i < Math.floor(len / 2); i++) { if (normalized[i] !== normalized.at(-i - 1)) { return false; } } return true; } console.log(isPalindrome('racecar')); // true console.log(isPalindrome('Level')); // true(大文字小文字を無視) console.log(isPalindrome('Hello')); // false
文字の出現回数をカウント
// 各文字の出現回数をカウント function charCount(str) { const count = {}; for (const char of str) { count[char] = (count[char] || 0) + 1; } return count; } console.log(charCount('banana')); // { b: 1, a: 3, n: 2 } // 最も多い文字を取得 function mostFrequentChar(str) { const count = charCount(str); return Object.entries(count) .sort((a, b) => b[1] - a[1])[0]; } console.log(mostFrequentChar('banana')); // ["a", 3]
よくあるエラーと注意点
関連メソッドの一覧
文字列から文字を取得する方法と関連するメソッドを整理します。目的に応じて最適なメソッドを選びましょう。
よくある質問(FAQ)
charAt(index)は指定インデックスの文字を返します(ES3〜)。at(index)はES2022の新しいメソッドで、負のインデックスが使えます(例:str.at(-1)で最後の文字)。マイナスインデックスを使いたい場合はatが便利です。str.charAt(n)②str[n](ブラケット記法)③str.at(n)(負インデックス対応・ES2022)。どれも0始まりのインデックスで、範囲外の場合はcharAtは空文字””を、ブラケット記法とatはundefinedを返します。[...str]のスプレッド構文かArray.from(str)を使うと文字単位で分割できます。また正規表現にuフラグを付けることでサロゲートペアを1文字として処理できます。まとめ
charAt() は従来からある基本メソッドですが、現在のJavaScriptではブラケット記法 str[i] が最も一般的で、末尾からのアクセスには at() が最適です。サロゲートペアを含む文字列を扱う場合は、[...str] や for...of でコードポイント単位に処理しましょう。