OracleデータベースでSQLを書いていると、「文字列の一部だけを取り出したい」という場面は頻繁にあります。
例えば、電話番号から市外局番だけを抽出したり、ファイルパスからファイル名を取り出したり、郵便番号のハイフン前後を分割したりする処理です。
こうした文字列の部分切り出しに使うのが SUBSTR() 関数です。
この記事では、SUBSTR()の基本構文から、負の開始位置で末尾から切り出す方法、バイト単位で切り出すSUBSTRB()、INSTR()と組み合わせた動的な切り出し、REGEXP_SUBSTR()との比較、実務で使える応用パターンまで、網羅的に解説します。
SUBSTR()関数の基本構文
SUBSTR() は、文字列の指定した位置から指定した文字数分を切り出す関数です。
構文
SUBSTR(文字列, 開始位置 [, 文字数])
| 引数 |
説明 |
必須 |
文字列 |
切り出し元の文字列(カラム名やリテラル) |
必須 |
開始位置 |
切り出しを開始する文字位置(1始まり) |
必須 |
文字数 |
切り出す文字数(省略時は末尾まで) |
任意 |
ポイント:Oracleの文字位置は 1始まり です。プログラミング言語のように0始まりではないので注意してください。ただし、0を指定しても1と同じ動作をします。
SUBSTR()の基本的な使い方
開始位置と文字数を指定して切り出す
最も基本的な使い方です。文字列の途中から指定した文字数分を取り出します。
SQL
-- 3文字目から3文字分を切り出す
SELECT SUBSTR('Hello World', 3, 3) AS result FROM dual;
「H(1) e(2) l(3) l(4) o(5) …」のように数え、3文字目の l から3文字分 llo が取得されます。
先頭から指定文字数を切り出す
開始位置を 1 にすれば、先頭から切り出せます。
SQL
-- 先頭から5文字を取得
SELECT SUBSTR('Oracle Database', 1, 5) AS result FROM dual;
文字数を省略した場合(末尾まで取得)
第3引数(文字数)を省略すると、開始位置から末尾まですべて取得されます。
SQL
-- 8文字目から末尾まで取得
SELECT SUBSTR('Oracle Database', 8) AS result FROM dual;
実行結果
RESULT
--------
Database
この書き方は、「n文字目以降をすべて取得」したい場合に便利です。
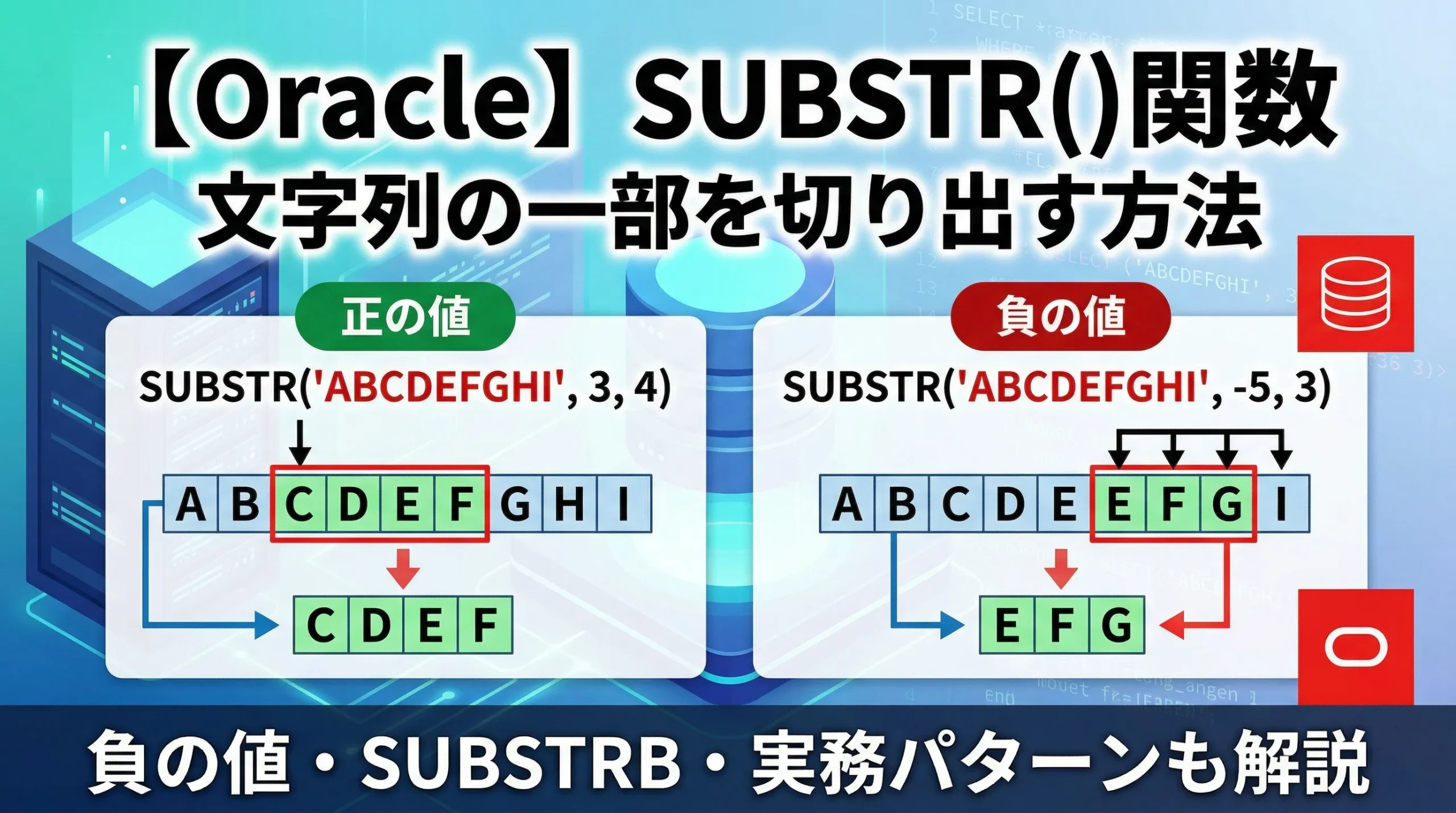
負の開始位置で末尾から切り出す
開始位置に負の値を指定すると、文字列の末尾から数えた位置から切り出しが始まります。
SQL
-- 末尾から5文字目を起点に3文字分を切り出す
SELECT SUBSTR('Hello World', -5, 3) AS result FROM dual;
-- 末尾から3文字を取得(文字数省略)
SELECT SUBSTR('Hello World', -3) AS result FROM dual;
実行結果
-- 1つ目のクエリ
RESULT
------
Wor
-- 2つ目のクエリ
RESULT
------
rld
-5 を指定した場合、末尾から5文字目(W)を起点として切り出します。文字数を省略すると末尾まで取得されるため、-3 で「末尾3文字」を取得できます。
開始位置の数え方まとめ
- 正の値:先頭から数える(1 = 先頭文字)
- 負の値:末尾から数える(-1 = 最後の文字)
- 0:1と同じ扱い(先頭文字から)
負の開始位置 + 文字数のパターン一覧
'ABCDEFGHIJ'(10文字)を例に、負の開始位置の動作を確認しましょう。
SQL
SELECT
SUBSTR('ABCDEFGHIJ', -1) AS last_1, -- J
SUBSTR('ABCDEFGHIJ', -3) AS last_3, -- HIJ
SUBSTR('ABCDEFGHIJ', -5, 2) AS mid_2, -- FG
SUBSTR('ABCDEFGHIJ', -7, 4) AS mid_4 -- DEFG
FROM dual;
実行結果
LAST_1 LAST_3 MID_2 MID_4
------ ------ ----- -----
J HIJ FG DEFG
開始位置に0を指定した場合の動作
Oracleでは開始位置に 0 を指定した場合、1と同じ扱いになります。
SQL
-- 開始位置0 と 開始位置1 の比較
SELECT
SUBSTR('ABCDE', 0, 3) AS pos_0, -- ABC
SUBSTR('ABCDE', 1, 3) AS pos_1 -- ABC
FROM dual;
実行結果
POS_0 POS_1
----- -----
ABC ABC
注意:Oracle では開始位置 0 は 1 と同じ動作ですが、他のRDBMSでは異なる場合があります。可読性のためにも、先頭から切り出す場合は 1 を明示することを推奨します。
テーブルのカラムに対して使う
実務では文字列リテラルではなく、テーブルのカラムに対してSUBSTR()を使うことがほとんどです。
SQL
-- 従業員名の先頭2文字をイニシャルとして取得
SELECT
emp_name,
SUBSTR(emp_name, 1, 2) AS initial
FROM employees;
実行結果
EMP_NAME INITIAL
---------- -------
田中太郎 田中
鈴木花子 鈴木
Smith Sm
SUBSTRB() – バイト単位で切り出す
SUBSTRB() は、文字数ではなくバイト数を基準に切り出す関数です。
構文
SUBSTRB(文字列, 開始バイト位置 [, バイト数])
SUBSTR と SUBSTRB の違い
マルチバイト文字(日本語など)を扱う場合に、SUBSTR と SUBSTRB の差が出ます。
SQL(AL32UTF8環境の場合)
-- 文字単位(SUBSTR)
SELECT SUBSTR('あいうえお', 1, 3) AS char_result FROM dual;
-- バイト単位(SUBSTRB)
SELECT SUBSTRB('あいうえお', 1, 3) AS byte_result FROM dual;
実行結果
-- SUBSTR(文字単位)
CHAR_RESULT
-----------
あいう
-- SUBSTRB(バイト単位)
BYTE_RESULT
-----------
あ
UTF-8 では日本語1文字が3バイトなので、SUBSTRB で3バイトを指定すると1文字分しか取得できません。
| 関数 |
単位 |
マルチバイト文字 |
主な用途 |
SUBSTR() |
文字単位 |
1文字 = 1 |
通常の文字列操作 |
SUBSTRB() |
バイト単位 |
1文字 = 2〜4バイト |
固定長レコードの処理 |
注意:SUBSTRBでマルチバイト文字の途中のバイトを指定すると、文字化けや空白が返される場合があります。バイト境界を意識して指定してください。
SUBSTRB の実務的な使用例
外部システム連携で固定長レコードを扱う場合など、バイト単位での切り出しが必要になることがあります。
SQL
-- 固定長レコード(100バイト)から各フィールドを抽出
SELECT
SUBSTRB(record_data, 1, 10) AS customer_code, -- 1〜10バイト
SUBSTRB(record_data, 11, 30) AS customer_name, -- 11〜40バイト
SUBSTRB(record_data, 41, 15) AS phone_number -- 41〜55バイト
FROM import_records;
WHERE句での活用
SUBSTR() は WHERE 句でも使えます。先頭文字列で条件を絞り込む場合に活用できます。
前方一致的な使い方
SQL
-- 社員番号の先頭2文字が「AB」の社員を取得
SELECT emp_id, emp_name
FROM employees
WHERE SUBSTR(emp_id, 1, 2) = 'AB';
注意:WHERE句でSUBSTR()を使うとインデックスが効きません(関数インデックスを作成している場合を除く)。前方一致であれば LIKE 'AB%' のほうがパフォーマンスが良い場合が多いです。
末尾の文字列で絞り込む
SQL
-- ファイル名の末尾4文字が「.csv」のレコードを取得
SELECT file_name
FROM file_list
WHERE SUBSTR(file_name, -4) = '.csv';
末尾の文字列で絞り込む場合は、負の開始位置が非常に便利です。LIKE '%.csv' と同等ですが、SUBSTR のほうが文字数を厳密に指定できます。
INSTR()と組み合わせた動的な切り出し
INSTR() 関数で特定の文字の位置を取得し、それをSUBSTR()の引数に使うことで、動的な位置で文字列を切り出せます。
基本パターン:区切り文字の前後を取得
SQL
-- メールアドレスからユーザー名とドメインを分離
SELECT
email,
SUBSTR(email, 1, INSTR(email, '@') - 1) AS user_name,
SUBSTR(email, INSTR(email, '@') + 1) AS domain
FROM employees;
実行結果
EMAIL USER_NAME DOMAIN
-------------------- ----------- -----------
tanaka@example.com tanaka example.com
suzuki@company.co.jp suzuki company.co.jp
ポイント:INSTR(email, '@') は @ の位置を返します。その位置の前後でSUBSTRの範囲を調整することで、区切り文字を含まない形で分割できます。
ファイルパスからファイル名を取得
SQL
-- ファイルパスから最後の「/」以降(ファイル名)を取得
SELECT
file_path,
SUBSTR(file_path, INSTR(file_path, '/', -1) + 1) AS file_name
FROM file_list;
実行結果
FILE_PATH FILE_NAME
--------------------------- ----------
/home/user/docs/report.pdf report.pdf
/var/log/app/error.log error.log
INSTR(file_path, '/', -1) は末尾から検索して最後の / の位置を返すため、ファイル名だけを正確に取得できます。
ファイル名から拡張子を取得
SQL
-- ファイル名から拡張子を取得
SELECT
file_name,
SUBSTR(file_name, INSTR(file_name, '.', -1) + 1) AS extension
FROM file_list;
実行結果
FILE_NAME EXTENSION
------------- ---------
report.pdf pdf
data.csv csv
image.jpeg jpeg
実務で使える応用パターン
1. 電話番号の分解
ハイフン区切りの電話番号を市外局番・市内局番・加入者番号に分割します。
SQL
-- 電話番号「03-1234-5678」を分解
SELECT
phone,
SUBSTR(phone, 1, INSTR(phone, '-') - 1) AS area_code,
SUBSTR(phone,
INSTR(phone, '-') + 1,
INSTR(phone, '-', 1, 2) - INSTR(phone, '-') - 1
) AS local_code,
SUBSTR(phone, INSTR(phone, '-', 1, 2) + 1) AS subscriber
FROM customers;
実行結果
PHONE AREA_CODE LOCAL_CODE SUBSCRIBER
------------ --------- ---------- ----------
03-1234-5678 03 1234 5678
06-9876-5432 06 9876 5432
INSTR(phone, '-', 1, 2) は「1文字目から検索して2番目に見つかった-の位置」を返します。これにより、2つ目の区切り文字以降を正確に取得できます。
2. 郵便番号の分割
SQL
-- 郵便番号「123-4567」を前半3桁・後半4桁に分割
SELECT
postal_code,
SUBSTR(postal_code, 1, 3) AS area,
SUBSTR(postal_code, 5, 4) AS detail
FROM addresses
WHERE postal_code LIKE '___-____';
実行結果
POSTAL_CODE AREA DETAIL
----------- ---- ------
100-0001 100 0001
530-0001 530 0001
3. 年月日の分解(文字列形式)
SQL
-- 「20260305」形式の日付文字列を分解
SELECT
date_str,
SUBSTR(date_str, 1, 4) AS yyyy,
SUBSTR(date_str, 5, 2) AS mm,
SUBSTR(date_str, 7, 2) AS dd
FROM (
SELECT '20260305' AS date_str FROM dual
);
実行結果
DATE_STR YYYY MM DD
-------- ---- -- --
20260305 2026 03 05
4. 文字列のマスク処理
個人情報の一部をマスクする場合にも SUBSTR() が活用できます。
SQL
-- 名前の先頭1文字だけ表示し、残りを「***」でマスク
SELECT
emp_name,
SUBSTR(emp_name, 1, 1) || '***' AS masked_name
FROM employees;
-- クレジットカード番号の末尾4桁のみ表示
SELECT
'****-****-****-' || SUBSTR(card_number, -4) AS masked_card
FROM payments;
実行結果
EMP_NAME MASKED_NAME
-------- -----------
田中太郎 田***
鈴木花子 鈴***
MASKED_CARD
-------------------
****-****-****-1234
****-****-****-5678
REGEXP_SUBSTR()との比較
Oracle 10g以降では、正規表現で文字列を切り出す REGEXP_SUBSTR() が使えます。SUBSTR() との使い分けを見てみましょう。
| 比較項目 |
SUBSTR() |
REGEXP_SUBSTR() |
| 切り出し基準 |
位置と文字数 |
正規表現パターン |
| パフォーマンス |
高速 |
正規表現の評価分やや遅い |
| 柔軟性 |
固定位置・固定長向け |
パターンマッチ向け |
| 対応バージョン |
全バージョン |
Oracle 10g以降 |
| 可読性 |
シンプル |
正規表現の知識が必要 |
同じ処理をSUBSTR と REGEXP_SUBSTR で比較
SQL
-- 「ABC-123-XYZ」から数字部分を取得
-- SUBSTR + INSTR の場合
SELECT SUBSTR('ABC-123-XYZ',
INSTR('ABC-123-XYZ', '-') + 1,
INSTR('ABC-123-XYZ', '-', 1, 2) - INSTR('ABC-123-XYZ', '-') - 1
) AS result1 FROM dual;
-- REGEXP_SUBSTR の場合
SELECT REGEXP_SUBSTR('ABC-123-XYZ', '\d+') AS result2 FROM dual;
実行結果(両方同じ)
RESULT
------
123
使い分けの指針
- 位置や長さが決まっている →
SUBSTR() を使う(シンプル・高速)
- パターンで抽出したい →
REGEXP_SUBSTR() を使う(柔軟)
- パフォーマンスが重要 → 可能な限り
SUBSTR() を選択
他のRDBMSとの比較
文字列切り出し関数はRDBMSによって名前や構文が異なります。
| RDBMS |
関数名 |
構文例 |
開始位置0の扱い |
| Oracle |
SUBSTR() |
SUBSTR(str, 1, 3) |
0は1と同じ |
| MySQL |
SUBSTRING() / SUBSTR() |
SUBSTRING(str, 1, 3) |
空文字を返す |
| PostgreSQL |
SUBSTRING() / SUBSTR() |
SUBSTRING(str FROM 1 FOR 3) |
0は1と同じ |
| SQL Server |
SUBSTRING() |
SUBSTRING(str, 1, 3) |
0は1と同じ |
主な違い
| 機能 |
Oracle |
MySQL |
PostgreSQL |
SQL Server |
| 負の開始位置 |
対応 |
対応 |
非対応 |
非対応 |
| 文字数省略 |
末尾まで |
末尾まで |
末尾まで |
省略不可(必須) |
| バイト単位関数 |
SUBSTRB() |
なし |
SUBSTRING(... USING OCTETS) |
なし |
各RDBMSのコード例
各RDBMS比較
-- Oracle
SELECT SUBSTR('Hello World', 1, 5) FROM dual; -- Hello
SELECT SUBSTR('Hello World', -5) FROM dual; -- World
-- MySQL
SELECT SUBSTRING('Hello World', 1, 5); -- Hello
SELECT SUBSTRING('Hello World', -5); -- World
-- PostgreSQL
SELECT SUBSTRING('Hello World' FROM 1 FOR 5); -- Hello
SELECT SUBSTR('Hello World', 1, 5); -- Hello
-- SQL Server
SELECT SUBSTRING('Hello World', 1, 5); -- Hello
-- ※ SQL ServerではSUBSTR()は使えません
よくあるエラーと対処法
| エラー / 問題 |
原因 |
対処法 |
ORA-00909 |
引数の数が不正 |
引数は2つまたは3つ必要 |
ORA-01722 |
開始位置や文字数に数値以外を指定 |
数値を指定する(文字列の場合はTO_NUMBERで変換) |
| NULLが返る |
元の文字列がNULL |
NVL()でNULLを事前に置換 |
| 空文字が返る |
開始位置が文字列長を超えている |
LENGTH()で文字列長を事前に確認 |
| 文字化け(SUBSTRB) |
マルチバイト文字の途中で切り出し |
文字境界を考慮した位置指定、またはSUBSTR()を使用 |
NULLの場合の対処
SUBSTR() に NULL を渡すと結果も NULL になります。NVL() で事前にデフォルト値を設定しておくと安全です。
SQL
-- NULLの場合の動作
SELECT SUBSTR(NULL, 1, 3) AS result FROM dual;
-- 結果: NULL
-- NVLで安全に処理
SELECT SUBSTR(NVL(emp_name, '(未設定)'), 1, 5) AS result
FROM employees;
文字列長を超えた場合の動作
SQL
-- 開始位置が文字列長を超える場合
SELECT SUBSTR('ABC', 10, 3) AS result FROM dual;
-- 結果: NULL
-- 文字数が残りの文字列長より大きい場合
SELECT SUBSTR('ABC', 2, 100) AS result FROM dual;
-- 結果: BC(エラーにならず、残りすべてが返る)
ポイント:文字数に大きな値を指定してもエラーにはなりません。残りの文字数分だけ返されるので、「開始位置以降すべて取得」する場合に大きな値を指定するテクニックも使えます。ただし、可読性を考えると文字数を省略するほうが望ましいです。
パフォーマンスの注意点
1. WHERE句でのインデックス無効化
WHERE SUBSTR(column, ...) のように関数を使うと、そのカラムのインデックスは使われません。
SQL
-- インデックスが効かない(フルスキャンになる可能性)
SELECT * FROM employees
WHERE SUBSTR(emp_code, 1, 3) = 'ABC';
-- 代替案1: LIKEを使う(インデックスが効く)
SELECT * FROM employees
WHERE emp_code LIKE 'ABC%';
-- 代替案2: 関数インデックスを作成
CREATE INDEX idx_emp_code_prefix
ON employees (SUBSTR(emp_code, 1, 3));
関数インデックスについて
- WHERE句で SUBSTR() を使う検索が頻繁にある場合は、関数インデックス(Function-Based Index)を検討しましょう
- ただし、インデックスの維持コスト(INSERT/UPDATE時のオーバーヘッド)も考慮してください
- 前方一致の検索であれば
LIKE 'prefix%' のほうがシンプルで効率的です
2. SELECT句での大量レコード処理
SELECT句でSUBSTR()を使うのは通常問題ありませんが、大量レコードに対して複雑な文字列操作を繰り返す場合は、処理時間に注意が必要です。
SQL
-- 非効率: 同じカラムに対してSUBSTRを何度も呼ぶ
SELECT
SUBSTR(data, 1, 3) AS part1,
SUBSTR(data, 4, 5) AS part2,
SUBSTR(data, 9, 2) AS part3,
SUBSTR(data, 11, 4) AS part4,
SUBSTR(data, 15) AS part5
FROM large_table; -- 数百万件
-- ヒント: 多数のSUBSTR呼び出しは、
-- PL/SQL処理やアプリケーション側での分割も検討
他の文字列関数との組み合わせ
SUBSTR() は他の文字列関数と組み合わせることで、より高度な文字列操作が可能です。
| 関数の組み合わせ |
用途 |
SUBSTR + INSTR |
区切り文字の位置をもとに動的に切り出す |
SUBSTR + LENGTH |
文字列長に応じた切り出し |
SUBSTR + TRIM |
切り出し後の空白を除去 |
SUBSTR + UPPER / LOWER |
切り出した文字の大文字/小文字変換 |
SUBSTR + REPLACE |
切り出しと文字置換の組み合わせ |
SUBSTR + TO_NUMBER |
切り出した数値文字列を数値に変換 |
SUBSTR + LENGTH:先頭と末尾を除いた中身を取得
SQL
-- 括弧を除いた中身を取得 「(内容)」→「内容」
SELECT SUBSTR('(Oracle)', 2, LENGTH('(Oracle)') - 2) AS result
FROM dual;
実行結果
RESULT
------
Oracle
SUBSTR + UPPER:先頭文字を大文字にする
SQL
-- 先頭文字を大文字に変換(INITCAP相当の手動実装)
SELECT
UPPER(SUBSTR('oracle database', 1, 1)) ||
SUBSTR('oracle database', 2) AS result
FROM dual;
実行結果
RESULT
---------------
Oracle database
まとめ
| 項目 |
内容 |
| 基本構文 |
SUBSTR(文字列, 開始位置 [, 文字数]) |
| 開始位置 |
正の値 = 先頭から、負の値 = 末尾から、0 = 1と同じ |
| 文字数省略 |
開始位置から末尾までを取得 |
| バイト単位 |
SUBSTRB() を使用(マルチバイト文字に注意) |
| 動的切り出し |
INSTR() と組み合わせて区切り位置を動的に取得 |
| パフォーマンス |
WHERE句での使用はインデックス無効化に注意 |
| NULL対策 |
NVL() で事前にデフォルト値を設定 |
SUBSTR() はOracleの文字列操作において最も基本的かつ重要な関数です。INSTR() との組み合わせで動的な切り出しができるようになれば、電話番号・メールアドレス・ファイルパスなど、実務で必要な文字列分割のほとんどに対応できます。
まずは基本構文をしっかり覚え、次に負の開始位置やINSTR()との組み合わせパターンを身につけていきましょう。