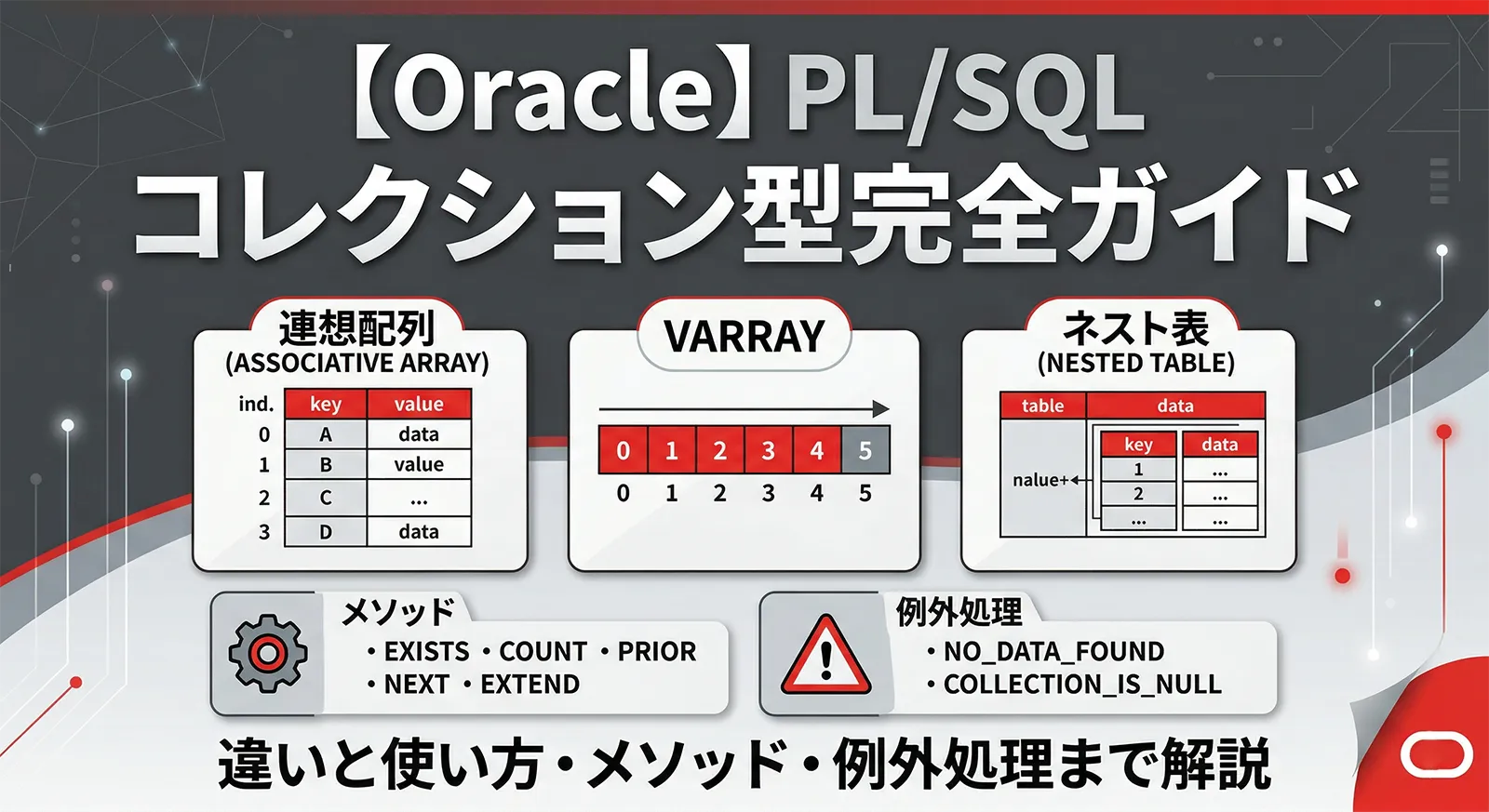
Oracle PL/SQL では複数の値をまとめて扱うためにコレクション型が用意されています。配列・リスト・マップのような機能を持ち、BULK COLLECT / FORALL と組み合わせることで行単位のループを避け、SQL エンジンとの往復(コンテキストスイッチ)を大幅に削減できます。
コレクション型には3種類あり、それぞれ特性が異なります。この記事では違いと選び方、主要メソッド、例外処理、TABLE() 関数による SQL 参照まで実例で解説します。
この記事でわかること
- 連想配列・VARRAY・ネスト表の違いと使い分け
- コレクションの宣言・初期化・要素の追加・削除
- COUNT / FIRST / LAST / NEXT / EXISTS / EXTEND / TRIM / DELETE メソッドの使い方
- BULK COLLECT INTO でコレクションにデータを一括取得する
- コレクション例外(COLLECTION_IS_NULL / SUBSCRIPT_BEYOND_COUNT など)の原因と対処
- TABLE() 関数でコレクションを SQL から参照する方法
3種類のコレクション型の比較
| 特性 | 連想配列(Associative Array) | VARRAY | ネスト表(Nested Table) |
|---|---|---|---|
| 宣言キーワード | TYPE t IS TABLE OF … INDEX BY | TYPE t IS VARRAY(n) OF … | TYPE t IS TABLE OF … |
| 要素数の上限 | なし(動的) | あり(宣言時に固定) | なし(動的) |
| インデックス型 | PLS_INTEGER または VARCHAR2 | 1 から始まる整数のみ | 1 から始まる整数のみ |
| 初期化(コンストラクタ) | 不要(宣言後すぐ使える) | 必要 | 必要 |
| EXTEND が必要か | 不要(キーで直接代入) | 必要 | 必要 |
| DB列として保存 | 不可 | 可 | 可 |
| BULK COLLECT との組み合わせ | 使用可(INDEX BY PLS_INTEGER) | 使用可 | 使用可 |
| 主な用途 | ルックアップテーブル・キャッシュ | 固定サイズリスト | 動的リスト・DB格納 |
連想配列(Associative Array)
連想配列は PL/SQL のみで使用できるコレクションで、初期化不要で最も手軽に使えます。キーに整数(PLS_INTEGER)または VARCHAR2 を使えるため、ハッシュマップ的なキャッシュ・ルックアップの実装に適しています。
連想配列の基本(整数キー)
DECLARE
-- PLS_INTEGER キーの連想配列
TYPE t_salary_tbl IS TABLE OF NUMBER INDEX BY PLS_INTEGER;
v_salary t_salary_tbl;
BEGIN
-- キーで直接代入(EXTEND 不要)
v_salary(101) := 50000;
v_salary(102) := 60000;
v_salary(103) := 45000;
-- キーで参照
DBMS_OUTPUT.PUT_LINE('101: ' || v_salary(101));
-- 全要素をループ(FIRST / NEXT でスパースなキーも安全に走査)
DECLARE
v_key PLS_INTEGER := v_salary.FIRST;
BEGIN
WHILE v_key IS NOT NULL LOOP
DBMS_OUTPUT.PUT_LINE(v_key || ' => ' || v_salary(v_key));
v_key := v_salary.NEXT(v_key);
END LOOP;
END;
END;
/
VARCHAR2 キーの連想配列(ルックアップテーブル)
DECLARE
-- 文字列キーの連想配列(ハッシュマップ的な使い方)
TYPE t_dept_map IS TABLE OF VARCHAR2(100) INDEX BY VARCHAR2(20);
v_dept_name t_dept_map;
BEGIN
v_dept_name('10') := 'Administration';
v_dept_name('20') := 'Marketing';
v_dept_name('50') := 'Shipping';
-- キー存在確認
IF v_dept_name.EXISTS('20') THEN
DBMS_OUTPUT.PUT_LINE('部門20: ' || v_dept_name('20'));
END IF;
-- 要素数
DBMS_OUTPUT.PUT_LINE('件数: ' || v_dept_name.COUNT);
END;
/
VARRAY(可変長配列)
VARRAY は最大要素数を宣言時に固定した配列です。サイズが決まっている固定リストの格納や、テーブルの列型としてデータベースに直接保存できるのが特徴です。
VARRAY の基本
DECLARE
-- 最大5要素の VARRAY
TYPE t_tag_array IS VARRAY(5) OF VARCHAR2(50);
v_tags t_tag_array;
BEGIN
-- コンストラクタで初期化(初期値を設定できる)
v_tags := t_tag_array('Oracle', 'SQL', 'PL/SQL');
-- 要素を追加(EXTEND で拡張してから代入)
v_tags.EXTEND; -- 1要素拡張
v_tags(4) := 'Performance';
v_tags.EXTEND;
v_tags(5) := 'Tuning';
-- 最大数を超えると SUBSCRIPT_BEYOND_COUNT エラー
-- v_tags.EXTEND; -- ← 6要素目は ORA-06532
-- 全要素をループ
FOR i IN 1 .. v_tags.COUNT LOOP
DBMS_OUTPUT.PUT_LINE(i || ': ' || v_tags(i));
END LOOP;
END;
/
ネスト表(Nested Table)
ネスト表は上限なく要素を追加できる動的配列です。BULK COLLECT との組み合わせで大量データを一括取得する場面で最もよく使われます。VARRAY と同様に DB 列型として保存もできます。
ネスト表の基本と BULK COLLECT
DECLARE
-- ネスト表の型宣言(上限なし)
TYPE t_emp_id_tbl IS TABLE OF employees.employee_id%TYPE;
TYPE t_last_name_tbl IS TABLE OF employees.last_name%TYPE;
v_ids t_emp_id_tbl;
v_names t_last_name_tbl;
BEGIN
-- BULK COLLECT で一括取得(コンテキストスイッチを最小化)
SELECT employee_id, last_name
BULK COLLECT INTO v_ids, v_names
FROM employees
WHERE department_id = 50
ORDER BY employee_id;
DBMS_OUTPUT.PUT_LINE('取得件数: ' || v_ids.COUNT);
-- インデックスでアクセス
FOR i IN 1 .. v_ids.COUNT LOOP
DBMS_OUTPUT.PUT_LINE(v_ids(i) || ': ' || v_names(i));
END LOOP;
END;
/
ネスト表への要素追加(EXTEND + 代入)
DECLARE
TYPE t_str_tbl IS TABLE OF VARCHAR2(100);
v_list t_str_tbl;
BEGIN
-- コンストラクタで空の初期化(初期化しないと COLLECTION_IS_NULL エラー)
v_list := t_str_tbl();
-- 要素を1件ずつ追加
v_list.EXTEND;
v_list(v_list.LAST) := 'item A';
v_list.EXTEND;
v_list(v_list.LAST) := 'item B';
v_list.EXTEND;
v_list(v_list.LAST) := 'item C';
DBMS_OUTPUT.PUT_LINE('件数: ' || v_list.COUNT);
-- 特定要素を削除(DELETE はスパースなコレクションにする)
v_list.DELETE(2); -- インデックス2を削除
DBMS_OUTPUT.PUT_LINE('DELETE後の件数: ' || v_list.COUNT);
-- TRIM は末尾から削除(稠密なまま)
-- v_list.TRIM; -- 末尾1件削除
-- v_list.TRIM(2); -- 末尾2件削除
END;
/
コレクションメソッド一覧
| メソッド | 説明 | 戻り値 | 使用可能な型 |
|---|---|---|---|
COUNT |
現在の要素数(削除された要素はカウントされない) | INTEGER | 全型 |
FIRST |
最初のインデックス値(空の場合 NULL) | INTEGER / VARCHAR2 | 全型 |
LAST |
最後のインデックス値(空の場合 NULL) | INTEGER / VARCHAR2 | 全型 |
NEXT(n) |
インデックス n の次のインデックス(なければ NULL) | INTEGER / VARCHAR2 | 全型 |
PRIOR(n) |
インデックス n の前のインデックス(なければ NULL) | INTEGER / VARCHAR2 | 全型 |
EXISTS(n) |
インデックス n の要素が存在するか | BOOLEAN | 全型 |
EXTEND |
末尾に要素を1つ追加(NULL で初期化) | — | VARRAY・ネスト表 |
EXTEND(n) |
末尾に n 個の要素を追加 | — | VARRAY・ネスト表 |
EXTEND(n, i) |
インデックス i の値をコピーして n 個追加 | — | VARRAY・ネスト表 |
TRIM |
末尾の要素を1つ削除 | — | VARRAY・ネスト表 |
TRIM(n) |
末尾の n 個の要素を削除 | — | VARRAY・ネスト表 |
DELETE |
全要素を削除 | — | 連想配列・ネスト表 |
DELETE(n) |
インデックス n の要素を削除(スパースになる) | — | 連想配列・ネスト表 |
DELETE(m, n) |
インデックス m ~ n の要素を削除 | — | 連想配列・ネスト表 |
LIMIT |
最大要素数(VARRAY のみ。それ以外は NULL) | INTEGER | VARRAY のみ |
FIRST/NEXT を使ったスパースコレクションの安全なループ
DELETE でインデックスが飛んだ(スパースな)コレクションを
DELETE でインデックスが飛んだ(スパースな)コレクションを
FOR i IN 1..v.COUNT でループすると NO_DATA_FOUND が発生します。FIRST / NEXT を使えばスパースなコレクションも安全に走査できます。
コレクション例外の原因と対処
| 例外名 | 原因 | 対処法 |
|---|---|---|
COLLECTION_IS_NULL |
初期化されていない VARRAY / ネスト表を操作しようとした | コンストラクタ(t_tbl())で初期化する |
SUBSCRIPT_BEYOND_COUNT |
COUNT を超えるインデックスにアクセスした(VARRAY・ネスト表) | EXTEND してから代入する。アクセス前に EXISTS で確認 |
SUBSCRIPT_OUTSIDE_LIMIT |
VARRAY の最大サイズを超えて EXTEND しようとした | VARRAY の最大サイズを見直す |
NO_DATA_FOUND |
存在しないインデックスにアクセスした(連想配列・ネスト表) | EXISTS で事前確認する |
コレクション例外の発生例と対処
DECLARE
TYPE t_num_tbl IS TABLE OF NUMBER;
v_list t_num_tbl; -- 未初期化
BEGIN
-- COLLECTION_IS_NULL: 初期化なしでアクセス
-- v_list.EXTEND; -- ← ORA-06531: 参照がネストした表またはVARRAYが初期化されていません
-- 正しい初期化
v_list := t_num_tbl(10, 20, 30);
-- SUBSCRIPT_BEYOND_COUNT: COUNT を超えてアクセス
-- DBMS_OUTPUT.PUT_LINE(v_list(5)); -- ← ORA-06533
-- EXISTS で事前確認
IF v_list.EXISTS(5) THEN
DBMS_OUTPUT.PUT_LINE(v_list(5));
ELSE
DBMS_OUTPUT.PUT_LINE('インデックス5は存在しません');
END IF;
-- DELETE後にスパースなコレクションを安全にループ
v_list.DELETE(2); -- インデックス2を削除 → 1, (2削除済み), 3
DECLARE
i PLS_INTEGER := v_list.FIRST;
BEGIN
WHILE i IS NOT NULL LOOP
DBMS_OUTPUT.PUT_LINE(i || ' => ' || v_list(i));
i := v_list.NEXT(i);
END LOOP;
END;
END;
/
TABLE() 関数でコレクションを SQL から参照する
ネスト表やオブジェクト型のコレクションは TABLE() 関数を使うことでSQL の FROM 句に指定し、通常のテーブルと同様にクエリできます。
TABLE() 関数でコレクションを SQL から参照する
-- まずスキーマレベルの型を作成(PL/SQLブロック内の型は TABLE() に使えない)
CREATE OR REPLACE TYPE t_number_list IS TABLE OF NUMBER;
/
-- PL/SQL でコレクションを作成して SQL に渡す
DECLARE
v_dept_ids t_number_list := t_number_list(10, 20, 50, 80);
BEGIN
-- TABLE() を使って IN 句の代わりに使う
FOR rec IN (
SELECT e.employee_id, e.last_name, e.department_id
FROM employees e
WHERE e.department_id IN (SELECT COLUMN_VALUE FROM TABLE(v_dept_ids))
ORDER BY e.department_id, e.employee_id
) LOOP
DBMS_OUTPUT.PUT_LINE(rec.department_id || ': ' || rec.last_name);
END LOOP;
END;
/
SQL から TABLE() でコレクションを直接クエリする
-- スキーマレベルのネスト表型を使って SQL でクエリ -- ※ PL/SQL ブロック内の型では使用不可 -- 作成済みの型を使ってSQLのみで利用 SELECT COLUMN_VALUE AS dept_id FROM TABLE(t_number_list(10, 20, 50)); -- 別テーブルとの JOIN SELECT e.last_name, e.salary FROM employees e JOIN TABLE(t_number_list(50, 80)) dept_list ON e.department_id = dept_list.COLUMN_VALUE ORDER BY e.salary DESC;
まとめ
- 連想配列:初期化不要・整数/文字列キー対応・PL/SQLのみで使えるハッシュマップ的な用途に最適
- VARRAY:最大サイズが決まっている固定リスト・DB 列型に保存可能
- ネスト表:上限なしの動的配列・BULK COLLECT との組み合わせ・DB 列型に保存可能
- EXTEND が必要な型:VARRAY・ネスト表は代入前に EXTEND が必要。連想配列は不要
- スパースループ:DELETE 後のコレクションは
FOR i IN 1..COUNTでなくFIRST/NEXTでループする - COLLECTION_IS_NULL:VARRAY・ネスト表はコンストラクタ(
t_tbl())で初期化してから使う - TABLE() 関数:スキーマレベルの型のみ SQL の FROM 句で使用可能
コレクションと BULK COLLECT / FORALL の組み合わせについては明示的カーソル完全ガイドも参照してください。コレクションを返すストアドファンクションの実装はストアドプロシージャ・ファンクション完全ガイドを参照してください。

