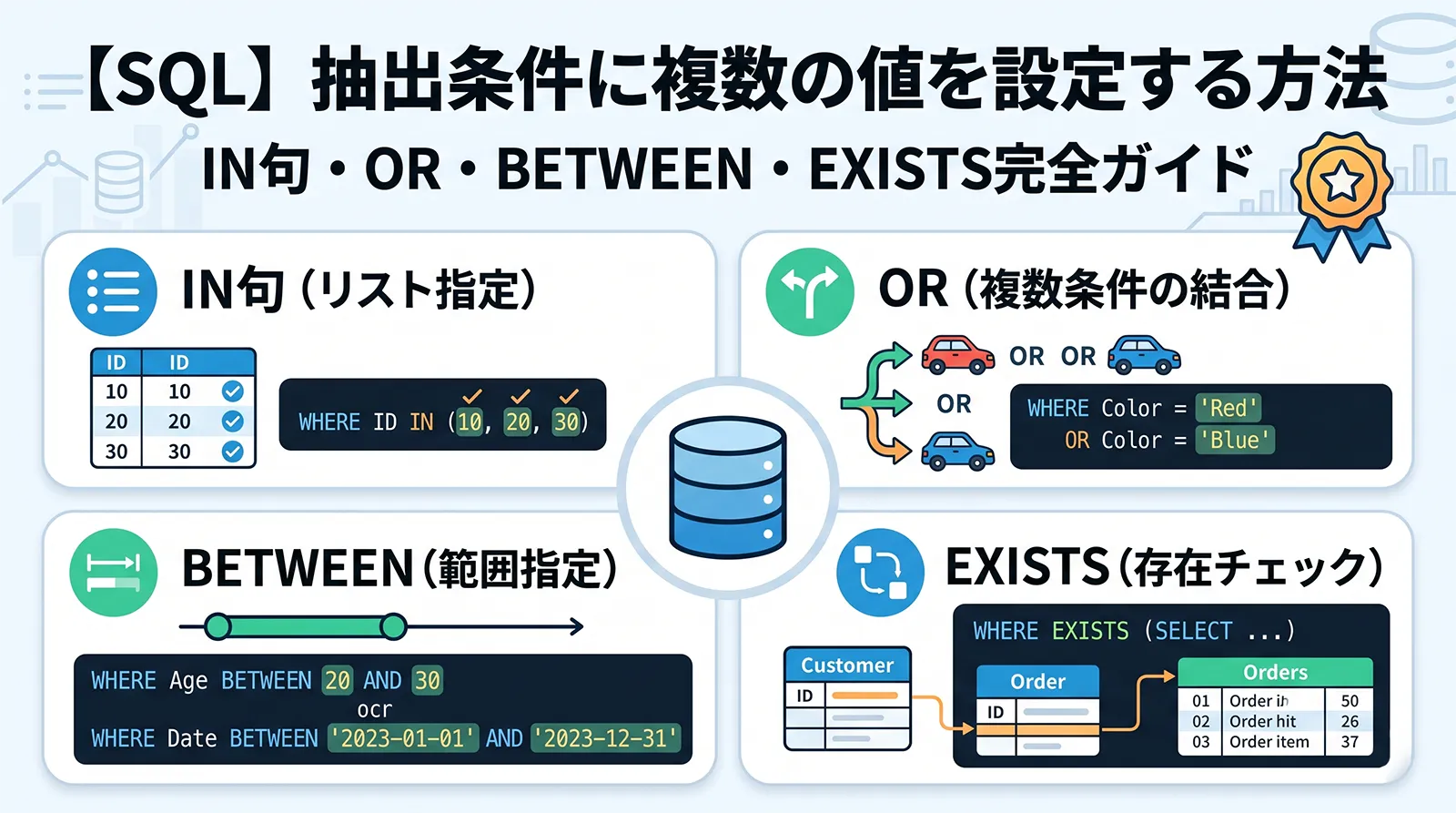
SQL の LIKE 演算子は、文字列の部分一致・前方一致・後方一致を WHERE 句で手軽に検索できる演算子です。名前の一部・メールドメイン・商品コードの前方一致など、実務で頻繁に登場します。
この記事では %・_ のワイルドカードの使い方から、% 自体を検索するエスケープ・大文字小文字の扱い・NOT LIKE・パフォーマンス問題と全文検索への移行まで体系的に解説します。
-- customers テーブル(顧客) -- id | name | email | phone | memo -- 1 | 田中 太郎 | tanaka@example.com | 090-1234-5678| VIP顧客 -- 2 | 田中 花子 | hanako@gmail.com | 080-2345-6789| NULL -- 3 | 鈴木 一郎 | suzuki@example.co.jp | 070-3456-7890| 特別割引 10% -- 4 | 高橋_美咲 | takahashi@company.com | 090-4567-8901| NULL -- 5 | Tanaka Taro | tanaka.t@example.com | NULL | 海外在住 -- 6 | SUZUKI ICHIRO | s.ichiro@EXAMPLE.COM | 090-5678-9012| NULL
LIKE 演算子の基本構文
LIKE は WHERE 句で文字列パターンとの一致を検索します。パターン文字(ワイルドカード)は %(任意の文字列)と _(任意の 1 文字)の 2 種類です。
-- 基本形 SELECT 列名 FROM テーブル名 WHERE 列名 LIKE 'パターン'; -- 前方一致: 「田」で始まる名前 SELECT * FROM customers WHERE name LIKE '田%'; -- 後方一致: 「郎」で終わる名前 SELECT * FROM customers WHERE name LIKE '%郎'; -- 部分一致(中間一致): 名前に「一」を含む SELECT * FROM customers WHERE name LIKE '%一%'; -- 完全一致(= と同じ動作、実用上は = を使う) SELECT * FROM customers WHERE name LIKE '田中 太郎';
% ワイルドカード(任意の文字列)
% は 0 文字以上の任意の文字列にマッチします。位置によって前方一致・後方一致・中間一致を使い分けます。
| パターン | 意味 | マッチする例 | マッチしない例 |
|---|---|---|---|
'田%' |
「田」で始まる(前方一致) | 田中, 田辺 次郎, 田 | 伊藤 田中 |
'%郎' |
「郎」で終わる(後方一致) | 太郎, 次郎, 郎 | 郎太, 太郎 Jr |
'%一%' |
「一」を含む(中間一致) | 一郎, 鈴木一, 第一号 | 壱, 一(単体は含む) |
'%example%' |
「example」を含む | test@example.com, example.co.jp | EXAMPLE.COM(大文字)※ |
'%' |
すべての文字列(NULL 以外) | 空文字・任意の文字列 | NULL |
LIKE '%' は NULL にマッチしない:WHERE memo LIKE '%' は NULL の行を除外します。NULL を含めたい場合は WHERE memo IS NOT NULL を使ってください。LIKE で NULL との比較は常に UNKNOWN(≠ TRUE)になるためです。-- example.com ドメインのメールアドレスを取得 SELECT id, name, email FROM customers WHERE email LIKE '%@example%'; -- 結果: -- id=1: tanaka@example.com ✓ -- id=3: suzuki@example.co.jp ✓ -- id=5: tanaka.t@example.com ✓ -- 電話番号が 090 で始まる顧客 SELECT id, name, phone FROM customers WHERE phone LIKE '090%'; -- パーセントや割引に関するメモを含む顧客 -- ※ % 自体を検索する場合は後述のエスケープが必要 SELECT id, name, memo FROM customers WHERE memo LIKE '%割引%';
_ ワイルドカード(任意の 1 文字)
_(アンダースコア)は任意の 1 文字にマッチします。文字数を指定したパターン検索や、特定位置の文字を絞り込むときに使います。
-- 「田中 ??」(田中 の後に空白と任意の2文字) SELECT * FROM customers WHERE name LIKE '田中 __'; -- マッチ: 田中 太郎(田中[空白]太郎 → _=太, _=郎)✓ -- 不マッチ: 田中 花子太(4文字なのでマッチしない) -- 3文字の名前 SELECT * FROM customers WHERE name LIKE '___'; -- 電話番号の形式チェック(090-XXXX-XXXX) SELECT * FROM customers WHERE phone LIKE '0__-____-____%'; -- 2文字目が「中」である名前 SELECT * FROM customers WHERE name LIKE '_中%';
| パターン | 意味 | マッチ例 |
|---|---|---|
'_郎' |
2文字で「郎」で終わる | 太郎, 一郎(次郎は3文字) |
'田中_' |
「田中」の後に1文字 | 田中太(スペースも1文字とカウント) |
'___' |
ちょうど3文字 | abc, 太郎 , 123 |
'_@%.%' |
1文字@ドメイン.何か | a@b.c(極めて短いメール形式) |
% や _ 自体を検索するエスケープ
% や _ 自体を検索したい場合(例:「10%OFF」「商品_A」を検索)は、エスケープ文字を使って特殊文字を無効化します。
-- 「10%」という文字列を検索(% をエスケープ) -- ESCAPE '!' → !の直後の % はワイルドカードではなく文字として扱う SELECT * FROM customers WHERE memo LIKE '%10!%%' ESCAPE '!'; -- 「商品_A」という文字列を含む検索(_ をエスケープ) SELECT * FROM products WHERE product_code LIKE '%商品!_A%' ESCAPE '!'; -- 標準 SQL の ESCAPE 句(すべての RDBMS で動作) SELECT * FROM customers WHERE memo LIKE '%割引 !__%' ESCAPE '!'; -- ↑ 「割引 _」で始まるもの( _ は文字として扱われる) -- MySQL では \ をエスケープ文字として使うことも可(非推奨) -- SELECT * FROM ... WHERE memo LIKE '%10\%%'; -- MySQL 固有
| RDBMS | デフォルトエスケープ文字 | 推奨の書き方 |
|---|---|---|
| MySQL | \(バックスラッシュ) |
LIKE '%10\%%' または ESCAPE '!' を明示 |
| PostgreSQL | \(バックスラッシュ) |
LIKE '%10\%%' または ESCAPE '!' |
| SQL Server | なし(ESCAPE 句を必ず使う) | LIKE '%10[%]%' または ESCAPE '!' |
| Oracle | なし(ESCAPE 句を必ず使う) | LIKE '%10!%%' ESCAPE '!' |
- 移植性のために
ESCAPE '!'を明示することを推奨(MySQL のデフォルト\は RDBMS 固有) - SQL Server は
LIKE '%10[%]%'のように角括弧[]で 1 文字を囲む方法も使える - エスケープ文字自体を検索したい場合は 2 回続ける(例:
!!で!を検索)
大文字小文字の扱いと ILIKE(RDBMS 別)
LIKE の大文字小文字の扱いは RDBMS によって異なります。特にメールアドレス・ユーザー名・コード検索では注意が必要です。
| RDBMS | デフォルトの挙動 | 大文字小文字を区別しない方法 |
|---|---|---|
| MySQL | 照合順序(Collation)に依存_ci サフィックス付きは区別しない |
照合順序を utf8mb4_general_ci 等にする(デフォルト) |
| PostgreSQL | 区別する(大文字小文字を厳密に区別) | ILIKE 演算子を使う(PostgreSQL 独自) |
| SQL Server | 照合順序に依存 多くのデフォルトは区別しない |
COLLATE SQL_Latin1_General_CP1_CI_AS を指定 |
| Oracle | 区別する | UPPER() で統一するか NLS_COMP/NLS_SORT を設定 |
-- 方法1: UPPER() / LOWER() で統一する(すべての RDBMS で使える)
SELECT * FROM customers
WHERE UPPER(name) LIKE UPPER('%tanaka%');
-- → 「田中」「TANAKA」「Tanaka」すべてにマッチ
-- 方法2: PostgreSQL の ILIKE(大文字小文字を区別しない LIKE)
-- ILIKE は PostgreSQL 専用。MySQL では使えない
SELECT * FROM customers
WHERE email ILIKE '%@EXAMPLE%';
-- → example, EXAMPLE, Example すべてにマッチ
-- 方法3: MySQL の照合順序を明示(COLLATE)
SELECT * FROM customers
WHERE email LIKE '%@example%'
COLLATE utf8mb4_general_ci; -- ci = case insensitive
-- サンプルデータでの確認
-- id=6: s.ichiro@EXAMPLE.COM
-- LIKE '%@example%' → MySQL(ci照合順序)ではマッチ、PostgreSQL ではマッチしない
-- ILIKE '%@example%' → PostgreSQL でマッチ
-- UPPER(email) LIKE '%@EXAMPLE%' → すべての RDBMS でマッチ
NOT LIKE で除外検索
NOT LIKE は LIKE の否定で、パターンに一致しない行を取得します。NULL の行は NOT LIKE でも除外されます(UNKNOWN になるため)。
-- gmail.com 以外のメールアドレス SELECT id, name, email FROM customers WHERE email NOT LIKE '%@gmail.com'; -- 結果: id=1, 3, 4, 5, 6 (id=2 の hanako@gmail.com が除外) -- NULL の email も除外される点に注意 -- id=5 は NULL ではないのでマッチする (NULL はない) -- 「VIP」を含まないメモの顧客(NULL も除外される) SELECT id, name, memo FROM customers WHERE memo NOT LIKE '%VIP%'; -- id=3(特別割引)のみ → id=2,4,6 の NULL も除外される -- NULL を含めたい場合 SELECT id, name, memo FROM customers WHERE memo NOT LIKE '%VIP%' OR memo IS NULL;
NOT LIKE・NOT IN・NOT EXISTS・NOT BETWEEN の使い分けと注意点は一致しないデータを抽出する方法で詳しく解説しています。
複数パターンの LIKE 検索
SQL には「複数のパターンのどれかに一致」する構文が標準にないため、OR で複数の LIKE を並べます。件数が多い場合は正規表現や全文検索を検討します。
-- 「田中」または「鈴木」を含む名前(OR で複数の LIKE を並べる)
SELECT * FROM customers
WHERE name LIKE '%田中%'
OR name LIKE '%鈴木%';
-- example.com または gmail.com のメール
SELECT * FROM customers
WHERE email LIKE '%@example%'
OR email LIKE '%@gmail.com';
-- IN と LIKE は直接組み合わせられない(エラーになる)
-- NG: WHERE email IN LIKE ('%@example%', '%@gmail%') -- 構文エラー
-- 3 つ以上のパターンがある場合: OR を列挙するか、RDBMS 固有の方法を使う
-- MySQL: REGEXP で代替
SELECT * FROM customers
WHERE email REGEXP '@example|@gmail|@company';
-- PostgreSQL: SIMILAR TO または ~ 演算子
-- WHERE email SIMILAR TO '%(example|gmail|company)%'
-- 正規表現の詳細は別記事を参照
正規表現(MySQL: REGEXP、PostgreSQL: ~、Oracle: REGEXP_LIKE)を使うとより柔軟なパターン検索が可能です。詳しくは正規表現で特定のパターン以外を抽出する方法を参照してください。
LIKE のパフォーマンスと全文検索への移行
LIKE は手軽ですが、使い方によってはインデックスが全く効かず、テーブルの全件スキャンになります。データ量が増えるほど深刻になります。
| パターン | インデックス | 理由 |
|---|---|---|
'田%'(前方一致) |
✓ 使われる | 先頭文字が確定しているためインデックスで絞り込める |
'%田'(後方一致) |
✗ 使われない | 先頭が不明なのでインデックスをスキャンできない |
'%田%'(中間一致) |
✗ 使われない | 同上:全件スキャン(フルスキャン)になる |
'田中'(完全一致) |
✓ 使われる | = と同等の絞り込みが可能 |
-- 前方一致: インデックスが使われる(type: range や ref)
EXPLAIN SELECT * FROM customers WHERE name LIKE '田%';
-- 後方・中間一致: インデックスが使われない(type: ALL = フルスキャン)
EXPLAIN SELECT * FROM customers WHERE name LIKE '%田%';
-- 解決策1: 前方一致に書き換えられないか検討する
-- NG: WHERE email LIKE '%@example.com'
-- OK: 設計段階でドメイン列を別に持つ → WHERE domain = 'example.com'
-- 解決策2: MySQL の FULLTEXT インデックス(全文検索)
-- 大量データの中間一致には FULLTEXT INDEX が有効
CREATE FULLTEXT INDEX idx_name ON customers (name);
SELECT * FROM customers
WHERE MATCH(name) AGAINST ('田中' IN BOOLEAN MODE);
数万件以下では問題になりにくいですが、数十万件・数百万件になると顕著に遅くなります。MySQL の
FULLTEXT INDEX、PostgreSQL の GIN インデックス + to_tsvector、または Elasticsearch などの専用検索エンジンへの移行を検討してください。-- PostgreSQL: GIN インデックス + pg_trgm(トライグラム)で中間一致を高速化
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE INDEX idx_name_trgm ON customers USING GIN (name gin_trgm_ops);
-- インデックスを使った中間一致検索(高速)
SELECT * FROM customers WHERE name LIKE '%田中%';
-- GIN インデックスがあれば %キーワード% でもインデックスが効く
-- MySQL: FULLTEXT インデックスの全文検索
ALTER TABLE customers ADD FULLTEXT INDEX ft_name (name);
SELECT * FROM customers
WHERE MATCH(name) AGAINST ('田中' IN BOOLEAN MODE);
実務でよく使う LIKE パターン集
-- 姓だけで検索(スペースの前まで) SELECT * FROM customers WHERE name LIKE '田中%'; -- メールアドレスのドメイン検索 SELECT * FROM customers WHERE email LIKE '%@example.com'; -- 複数ドメイン(OR で並べる) SELECT * FROM customers WHERE email LIKE '%@example.com' OR email LIKE '%@example.co.jp'; -- 商品コードの前方一致(例: 「A-」で始まる商品) SELECT * FROM products WHERE product_code LIKE 'A-%'; -- 電話番号の形式チェック(ハイフンなし 11 桁) SELECT * FROM customers WHERE phone NOT LIKE '%-%' -- ハイフンなし AND phone LIKE '0__________'; -- 0 で始まる 11 桁
-- 住所に「東京」を含む(フルスキャンになるため件数が少ない場合のみ推奨) SELECT * FROM users WHERE address LIKE '%東京%'; -- 複合条件: カテゴリが「食品」かつ名前に「有機」を含む SELECT * FROM products WHERE category = '食品' -- インデックスが効く(= 条件) AND name LIKE '%有機%'; -- category で絞った後に LIKE -- テクニック: 絞り込みやすい条件を先に書く -- category = '食品' で先に行数を減らすと LIKE のスキャン対象が減る -- 期間 + LIKE の組み合わせ(WHERE複数条件) SELECT * FROM orders WHERE order_date >= '2024-01-01' AND customer_name LIKE '田%';
よくある質問(FAQ)
LIKE '%' で全件取得しようとしたら NULL の行が含まれませんでした。LIKE '%' は空文字を含む任意の文字列にマッチしますが、NULL にはマッチしません。NULL との LIKE 比較は UNKNOWN になり、WHERE で除外されます。NULL を含めたい場合は WHERE 列 IS NOT NULL または WHERE 列 LIKE '%' OR 列 IS NULL を使ってください。utf8mb4_general_ci(ci = case insensitive)の場合は大文字小文字を区別しません。区別したい場合は BINARY キーワードを使います: WHERE BINARY name LIKE '%Tanaka%'。または照合順序を utf8mb4_bin に変更してください。% がワイルドカードとして解釈されているためです。% 自体を検索するには ESCAPE 句でエスケープ文字を指定します。例: WHERE memo LIKE '%10!%%' ESCAPE '!'。これで ! の直後の % はワイルドカードではなく文字として扱われます。%キーワード%)で検索したら非常に遅くなりました。FULLTEXT INDEX を使う、③PostgreSQL なら pg_trgm 拡張の GIN インデックスを使う、④大量データなら Elasticsearch などの全文検索エンジンを導入する、の 4 つです。LIKE '田中_' を使います。_ は任意の 1 文字にマッチするため、「田中」+ 1 文字 = 合計 3 文字の名前が取れます。日本語 1 文字は _ 1 つで表現できます(マルチバイト対応の RDBMS では)。ただし MySQL では文字コードと照合順序の設定によってバイト数で数える場合があるため、CHAR_LENGTH と組み合わせて確認してください。まとめ
| やりたいこと | 書き方・ポイント |
|---|---|
| 前方一致 | LIKE 'キーワード%'(インデックスが効く) |
| 後方一致 | LIKE '%キーワード'(インデックス効かない・フルスキャン) |
| 中間一致(部分一致) | LIKE '%キーワード%'(インデックス効かない・大量データは全文検索を検討) |
| 任意の 1 文字 | _ を使う(例: '田中_' = 田中 + 1 文字) |
| % や _ 自体を検索 | ESCAPE '!' で !%・!_ とエスケープ |
| 大文字小文字を区別しない | UPPER(列) LIKE UPPER('...') または PostgreSQL の ILIKE |
| パターンに一致しない行 | NOT LIKE(NULL は除外される点に注意) |
| 複数パターンのいずれか | LIKE ... OR LIKE ...(または正規表現 REGEXP/ILIKE) |
| 大量データの中間一致を高速化 | MySQL: FULLTEXT INDEX / PostgreSQL: pg_trgm GIN インデックス |
LIKE と組み合わせた複数条件の絞り込みはWHERE句で複数条件を組み合わせる完全ガイドを、さらに高度なパターンマッチング(正規表現)は正規表現で特定のパターン以外を抽出する方法を参照してください。