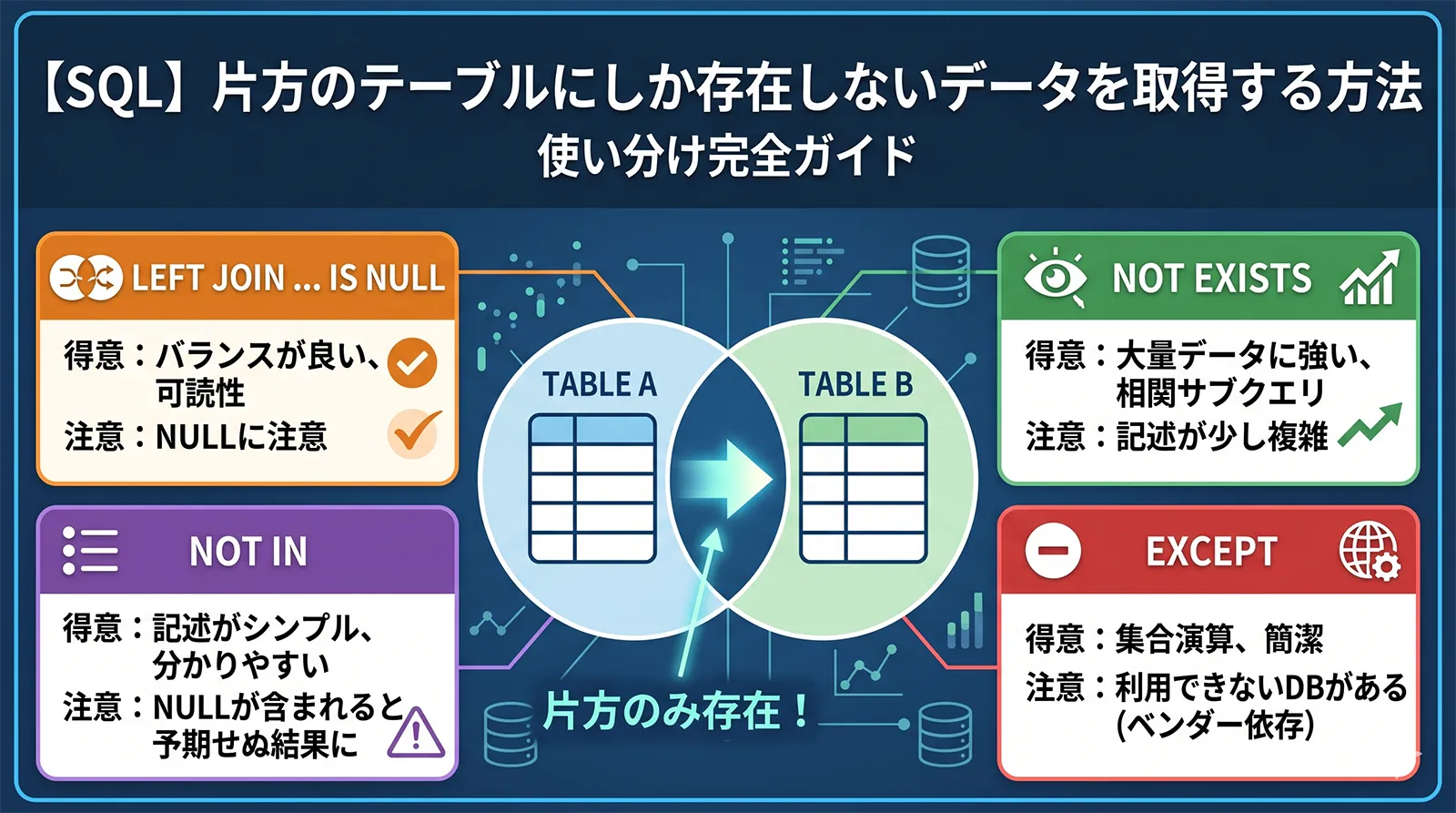
「テーブルAにはあるがテーブルBには存在しないレコード」を取得したい場面は実務で頻繁に発生します。未購入の顧客、マスタ未登録の取引、同期もれのデータなど、差分を特定する操作はアンチジョイン(anti-join)と呼ばれます。
SQLでアンチジョインを実現する手法は主に4つあります。それぞれ動作・性能・NULL対応が異なるため、状況に応じた使い分けが品質と速度を左右します。本記事ではそれぞれの仕組みを丁寧に解説し、実務でそのまま使えるパターンを紹介します。
サンプルデータの準備
「全ユーザー(users)のうち、一度も購入していないユーザー」を取得する例で解説します。
-- 全ユーザーテーブル
CREATE TABLE users (
user_id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL
);
INSERT INTO users VALUES
(1, '田中'), (2, '佐藤'), (3, '鈴木'), (4, '高橋'), (5, '伊藤');
-- 購入済みユーザーテーブル
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT, -- NULLが入る可能性がある列
product VARCHAR(50)
);
INSERT INTO orders VALUES
(101, 1, '商品A'), (102, 3, '商品B'), (103, NULL, '商品C');
-- users: user_id = 1,2,3,4,5
-- orders に存在する user_id: 1, 3, NULL
-- 期待結果: 未購入ユーザー = 佐藤(2)・高橋(4)・伊藤(5)
方法1: LEFT JOIN + IS NULL(最もよく使われる手法)
LEFT JOINは左テーブルの全行を保持し、右テーブルに対応行がない場合はNULLを補填します。その「NULLになった行」だけをWHERE 右テーブル.列 IS NULLで絞り込むのがこのパターンです。
SELECT u.user_id, u.name FROM users u LEFT JOIN orders o ON u.user_id = o.user_id WHERE o.user_id IS NULL; -- 結果 -- user_id | name -- --------+------ -- 2 | 佐藤 -- 4 | 高橋 -- 5 | 伊藤
仕組みを図で理解する
LEFT JOINの結果は下表のようになります。orders.user_idがNULLの行だけが「購入なし」です。
| u.user_id | u.name | o.user_id(JOINに使う列) | IS NULL? |
|---|---|---|---|
| 1 | 田中 | 1 | × |
| 2 | 佐藤 | NULL | ○ ← 取得 |
| 3 | 鈴木 | 3 | × |
| 4 | 高橋 | NULL | ○ ← 取得 |
| 5 | 伊藤 | NULL | ○ ← 取得 |
複数列で一致させる場合
一致条件が2列以上になる場合もON句に追加するだけです。
SELECT a.category, a.product_code, a.product_name
FROM master_products a
LEFT JOIN sales_data b
ON a.category = b.category
AND a.product_code = b.product_code
WHERE b.category IS NULL; -- 右テーブルの列ならどちらでも可
LEFT JOIN IS NULL vs EXCEPT どちらを使うか
方法2: NOT EXISTS(NULL安全・大規模テーブルに強い)
NOT EXISTSは相関サブクエリを使い、「サブクエリが1件も返さない」行だけを残します。相関サブクエリとは外側のクエリの値をサブクエリ内で参照する書き方です。
SELECT u.user_id, u.name
FROM users u
WHERE NOT EXISTS (
SELECT 1
FROM orders o
WHERE o.user_id = u.user_id -- 外側のu.user_idを参照
);
-- 結果: 佐藤(2)・高橋(4)・伊藤(5) ← NULLに強く正確
NOT EXISTSがNULLに強い理由
EXISTS / NOT EXISTSはサブクエリが「行を返すかどうか」だけを評価します。返された行の値がNULLであっても「行が存在した」と判断されます。そのためorders.user_idにNULL行があっても、NULL = u.user_idは成立しないためスキップされ、他の一致行の評価に影響しません。
u.user_id = 2 のとき → サブクエリ「WHERE o.user_id = 2」を実行 → 0件 → NOT EXISTS = TRUE → 取得
u.user_id = 1 のとき → サブクエリ「WHERE o.user_id = 1」を実行 → 1件 → NOT EXISTS = FALSE → スキップ
SELECT 1 vs SELECT * — どちらを書くべきか
SELECT 1とSELECT *はEXISTSの文脈では同じ意味です。EXISTS句はサブクエリの「結果が存在するか」だけを見るため、SELECT句の内容は評価されません。慣習としてSELECT 1が広く使われます。インデックスとの相性
NOT EXISTSのサブクエリはWHERE句の条件列(ここではorders.user_id)にインデックスがあると高速に動作します。最初にマッチする行が見つかった時点で評価が停止するショートサーキット動作により、全件スキャンを避けられます。
方法3: NOT IN(シンプルだがNULLに注意)
NOT IN (サブクエリ)は可読性が高く直感的ですが、サブクエリ結果にNULLが1件でも含まれると全件0件になるという重大な落とし穴があります。
-- サブクエリにNULLが含まれない前提なら正しく動作する
SELECT user_id, name
FROM users
WHERE user_id NOT IN (
SELECT user_id FROM orders WHERE user_id IS NOT NULL -- NULL除外が必須
);
-- user_id IS NOT NULL なしだと結果が0件になる(後述)
NULLが引き起こす「0件問題」の仕組み
SQLの三値論理(TRUE/FALSE/UNKNOWN)がNOT INと組み合わさると次の問題が起きます。
-- orders.user_id には NULL が含まれている(INSERT INTO orders VALUES (103, NULL, '商品C'))
-- このクエリは0件を返す(ワナ)
SELECT user_id, name
FROM users
WHERE user_id NOT IN (
SELECT user_id FROM orders -- NULL が含まれる: (1, 3, NULL)
);
-- 内部的に展開されると:
-- WHERE user_id NOT IN (1, 3, NULL)
-- = WHERE user_id <> 1 AND user_id <> 3 AND user_id <> NULL
-- = WHERE user_id <> 1 AND user_id <> 3 AND UNKNOWN
-- = UNKNOWN(どの行もFALSEでもTRUEでもなくUNKNOWNになる)
-- 結果: 0件
NOT INリストにNULLが1つでもあると、全行の評価がUNKNOWNになり結果が0件になります。回避するには必ずWHERE user_id IS NOT NULLをサブクエリに追加してください。右テーブルの結合キーにNULLが入り得る設計の場合はLEFT JOIN IS NULL か NOT EXISTSを使う方が安全です。NULL問題を回避した安全な書き方
-- サブクエリ側でNULLを明示的に除外する
SELECT user_id, name
FROM users
WHERE user_id NOT IN (
SELECT user_id
FROM orders
WHERE user_id IS NOT NULL -- これが必須
);
-- 結果: 佐藤(2)・高橋(4)・伊藤(5)
NOT INが有効な場面
右テーブルがNOT NULL制約付きの場合(NULLが入らないと保証されている場合)や、サブクエリが定数リストNOT IN (1, 2, 3)の場合はシンプルで問題ありません。
-- カテゴリID 5, 10 以外の商品を取得(NULLなし確定)
SELECT product_name
FROM products
WHERE category_id NOT IN (5, 10);
-- NOT NULL制約のある社員IDに対して使う
SELECT employee_id, employee_name
FROM employees
WHERE department_id NOT IN (
SELECT department_id FROM closed_departments -- NOT NULL制約あり
);
方法4: EXCEPT / MINUS(集合演算で差分を取る)
集合演算子EXCEPT(OracleではMINUS)は、前のSELECT結果から後ろのSELECT結果を除いた差集合を返します。両クエリの列数と型を合わせる必要があります。
-- PostgreSQL / SQL Server: EXCEPT SELECT user_id FROM users EXCEPT SELECT user_id FROM orders WHERE user_id IS NOT NULL; -- 結果: 2, 4, 5
-- Oracle: MINUS SELECT user_id FROM users MINUS SELECT user_id FROM orders WHERE user_id IS NOT NULL;
-- MySQL 8.0.31 以降 SELECT user_id FROM users EXCEPT SELECT user_id FROM orders WHERE user_id IS NOT NULL; -- 注意: MySQL 5.7・8.0未満では使えないためLEFT JOINを使う
EXCEPTの特徴と制限
EXCEPT ALL(PostgreSQL)を使います。また列数が一致していなければ構文エラーになるため、取得したい列が多い場合は他の方法の方がシンプルです。| 観点 | EXCEPT/MINUS | LEFT JOIN IS NULL |
|---|---|---|
| 重複排除 | 自動(DISTINCT相当) | 手動でDISTINCT追加 |
| 取得列の自由度 | 低い(列数・型一致必須) | 高い(自由に選べる) |
| NULL扱い | NULLを等しいと見なして除外 | 結合失敗をNULLで補填 |
| 対応DBMS | MySQL 8.0.31+/PgSQL/Oracle(MINUS)/MSSQL | すべて |
4つの手法の比較一覧
シチュエーション別にどの手法を選ぶべきか整理します。
| 手法 | 可読性 | NULL安全 | パフォーマンス | 主な用途・特徴 |
|---|---|---|---|---|
| LEFT JOIN + IS NULL | ○ | ◎ | ◎ | 最もよく使われる。汎用的で全DBで動作。結合列のインデックスが効く |
| NOT EXISTS | ○ | ◎ | ○〜◎ | NULL安全。ショートサーキットで大規模テーブルに有利。相関サブクエリ |
| NOT IN | ◎ | △(要注意) | ○ | 可読性が高い。右テーブルにNULLがあると0件バグ。リストが少ない場合に適切 |
| EXCEPT / MINUS | ◎ | ○ | △〜○ | 集合演算として差分が直感的。列数一致が必要。MySQL古バージョンでは不可 |
パフォーマンスの考え方
どの手法が速いかはテーブルサイズ・インデックス有無・DBMSのオプティマイザに依存します。現代のオプティマイザは多くの場合、3手法を同等の実行計画に変換します。ただし以下のポイントは把握しておく価値があります。
| 状況 | 推奨手法 | 理由 |
|---|---|---|
| 結合列にインデックスあり(大規模) | LEFT JOIN / NOT EXISTS | インデックスネステッドループが効く |
| サブクエリ件数が少ない | NOT IN | インリストが小さければオーバーヘッドが低い |
| サブクエリ件数が多い(数万件以上) | NOT EXISTS / LEFT JOIN | NOT INは全リスト展開で遅くなる可能性 |
| MySQLで最適化したい | LEFT JOIN + IS NULL | MySQLのNOT EXISTSは以前はLEFT JOIN変換が速かった(8.0で改善) |
EXPLAIN SELECT ...、PostgreSQLならEXPLAIN ANALYZE SELECT ...で確認できます。-- LEFT JOIN + IS NULLの実行計画
EXPLAIN
SELECT u.user_id, u.name
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
WHERE o.user_id IS NULL;
-- NOT EXISTSの実行計画
EXPLAIN
SELECT u.user_id, u.name
FROM users u
WHERE NOT EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.user_id
);
-- type列がrefやeq_refならインデックスが効いている証拠
DBMS別の注意点
-- LEFT JOIN + IS NULL: 全バージョンで使用可(推奨) SELECT u.user_id, u.name FROM users u LEFT JOIN orders o ON u.user_id = o.user_id WHERE o.user_id IS NULL; -- EXCEPT: MySQL 8.0.31以降のみ対応(それ以前は使えない) -- NOT IN: NULLが入る可能性があればIS NOT NULLフィルタを追加
-- EXCEPT ALL: 重複を残す場合 SELECT user_id FROM users EXCEPT ALL SELECT user_id FROM orders WHERE user_id IS NOT NULL; -- DISTINCT ONを使う場合(PostgreSQL独自) SELECT DISTINCT ON (u.user_id) u.user_id, u.name FROM users u LEFT JOIN orders o ON u.user_id = o.user_id WHERE o.user_id IS NULL;
-- MINUS(OracleはEXCEPTではなくMINUS)
SELECT user_id FROM users
MINUS
SELECT user_id FROM orders WHERE user_id IS NOT NULL;
-- NOT EXISTS(Oracleでは相関サブクエリが高速になりやすい)
SELECT u.user_id, u.name
FROM users u
WHERE NOT EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.user_id
);
-- EXCEPT(SQL Serverも対応) SELECT user_id FROM users EXCEPT SELECT user_id FROM orders WHERE user_id IS NOT NULL; -- LEFT JOIN + IS NULL(汎用) SELECT u.user_id, u.name FROM users u LEFT JOIN orders o ON u.user_id = o.user_id WHERE o.user_id IS NULL;
実務でよく使うパターン集
マスタ未登録チェック
トランザクションに存在するが、マスタに登録されていないコードを検出します。データ品質確認で頻用されます。
-- sales_data に存在するが customers マスタにない customer_code を検出 SELECT DISTINCT s.customer_code FROM sales_data s LEFT JOIN customers c ON s.customer_code = c.customer_code WHERE c.customer_code IS NULL ORDER BY s.customer_code;
差分バッチ処理(未処理レコードの抽出)
処理済みテーブルに存在しない未処理レコードを対象に絞って処理します。
-- raw_data のうち processed_data にない行だけを取得
INSERT INTO processed_data (id, value, processed_at)
SELECT r.id, r.value, NOW()
FROM raw_data r
WHERE NOT EXISTS (
SELECT 1
FROM processed_data p
WHERE p.id = r.id
);
両方向の差分を一度に確認(FULL OUTER JOINパターン)
「AにあってBにない」と「BにあってAにない」を同時に確認したい場合はFULL OUTER JOINを使います。
-- PostgreSQL / Oracle / SQL Server
SELECT
COALESCE(a.id, b.id) AS id,
CASE
WHEN b.id IS NULL THEN 'Aのみ存在'
WHEN a.id IS NULL THEN 'Bのみ存在'
END AS status
FROM table_a a
FULL OUTER JOIN table_b b ON a.id = b.id
WHERE a.id IS NULL OR b.id IS NULL;
-- MySQL(FULL OUTER JOINなし)は UNION で代替
SELECT a.id, 'Aのみ存在' AS status
FROM table_a a LEFT JOIN table_b b ON a.id = b.id WHERE b.id IS NULL
UNION ALL
SELECT b.id, 'Bのみ存在' AS status
FROM table_b b LEFT JOIN table_a a ON b.id = a.id WHERE a.id IS NULL;
複合キーでの差分抽出
主キーが複数列の場合、LEFT JOIN の ON句に全条件を追加します。
-- planned(計画)にあり、actual(実績)にない予算項目を抽出
SELECT p.fiscal_year, p.dept_code, p.budget_item
FROM planned p
LEFT JOIN actual a
ON p.fiscal_year = a.fiscal_year
AND p.dept_code = a.dept_code
AND p.budget_item = a.budget_item
WHERE a.dept_code IS NULL; -- JOIN条件の右側列の一つ
削除検知(論理削除・変更検知)
スナップショットを比較して削除されたレコードを検知します。
-- snapshot_prev(前回)にあり snapshot_curr(今回)にないIDを削除済みと判断
SELECT p.record_id, p.record_name
FROM snapshot_prev p
WHERE NOT EXISTS (
SELECT 1
FROM snapshot_curr c
WHERE c.record_id = p.record_id
);
よくある質問
SELECT VERSION();で確認できます。SELECT DISTINCT user_id FROM ordersとして重複を除去してからJOINするのが基本です。または最初からNOT EXISTSを使えば重複問題を回避できます。FROM a LEFT JOIN b ON ... LEFT JOIN c ON ... WHERE b.id IS NULL AND c.id IS NULL。またはNOT EXISTSをAND NOT EXISTS(...)で組み合わせます。EXCEPTの場合はA EXCEPT Bの結果をさらにEXCEPT Cします。まとめ
「片方のテーブルにしか存在しないデータ」を取得するアンチジョインは、実務で頻繁に登場する操作です。4つの手法をシーンに合わせて使い分けましょう。
- LEFT JOIN + IS NULL:最も汎用的。全DBで動作し、インデックスが効き、取得列を自由に選べる。迷ったらこれ
- NOT EXISTS:NULL安全。ショートサーキット動作で大規模テーブルにも対応。複雑な条件を書きやすい
- NOT IN:可読性が高い。ただし右テーブルにNULLが含まれると0件バグが発生。必ずIS NOT NULLフィルタを追加するか使用を避ける
- EXCEPT / MINUS:集合演算として差分が直感的。重複を自動排除。MySQL 8.0.31未満では使用不可
関連記事:NOT IN完全ガイド(基本・NULL問題・NOT EXISTS比較)、UNION完全ガイド(EXCEPT/MINUS含む)、IN句・OR・BETWEEN・EXISTS完全ガイド