SQL Serverで「急にSQLが遅くなった」「実行計画の推定行数と実際の行数が大きくズレる」「インデックスはあるのに使われない」といった問題がある場合、統計情報が古い可能性があります。統計情報は、SQL Serverのクエリオプティマイザーが行数を見積もり、実行計画を選ぶための材料です。
この記事では、SQL Serverの統計情報とは何か、更新が必要になる場面、UPDATE STATISTICS、sp_updatestats、AUTO_UPDATE_STATISTICS の確認、sys.dm_db_stats_properties による更新日時・変更行数の確認、FULLSCAN や SAMPLE の使い分けまで実務向けに整理します。
遅いSQLの原因として統計情報を疑うときは、まず実行計画で推定行数と実際の行数のズレを確認します。次に
sys.dm_db_stats_properties で last_updated、rows、rows_sampled、modification_counter を見ます。対象が明確なら UPDATE STATISTICS dbo.TableName StatisticName、テーブル単位なら UPDATE STATISTICS dbo.TableName、DB全体なら EXEC sp_updatestats を検討します。ただし、統計情報更新は再コンパイルや負荷につながるため、頻繁に全件FULLSCANする運用は避けます。SQL Serverの統計情報とは
統計情報は、テーブルやインデックスの列にどのような値がどれくらい分布しているかを示す情報です。SQL Serverはこの情報を使って、WHERE句やJOIN条件で何行くらい返るかを見積もります。この見積もりをカーディナリティ推定と呼びます。
行数の見積もりが外れると、SQL Serverは不適切な実行計画を選びやすくなります。たとえば、本当は大量行を処理するのに少数行だと見積もると、Nested Loops と Key Lookup が大量に繰り返されることがあります。逆に、本当は少数行なのに大量行だと見積もると、不要に重い Hash Match やスキャンが選ばれることがあります。
| 統計情報が影響するもの | 具体例 |
|---|---|
| 行数見積もり | 推定行数、結合後の行数、フィルター後の行数 |
| アクセス方法 | Index Seek、Index Scan、Table Scan の選択 |
| 結合方法 | Nested Loops、Hash Match、Merge Join の選択 |
| メモリ見積もり | SortやHash Matchで必要なメモリ、Spillの発生しやすさ |
| 実行計画の安定性 | パラメータ値やデータ分布による計画変化 |
実行計画の見方は、次の記事で詳しく整理しています。
統計情報を更新すべき場面
統計情報は自動更新されることがありますが、すべての問題を自動で解決してくれるわけではありません。特に大量データの追加、偏ったデータの投入、日付のように増え続ける列では、実行計画の見積もりが外れやすくなります。
| 場面 | 疑う理由 | 確認すること |
|---|---|---|
| 大量INSERT/UPDATE/DELETE後に遅くなった | 統計情報作成時のデータ分布と現在の分布が変わった | modification_counter と実行計画の推定行数 |
| 日付の新しい範囲だけ遅い | 昇順キーで新しい値の見積もりが外れることがある | 対象日付列の統計情報、最新データの件数 |
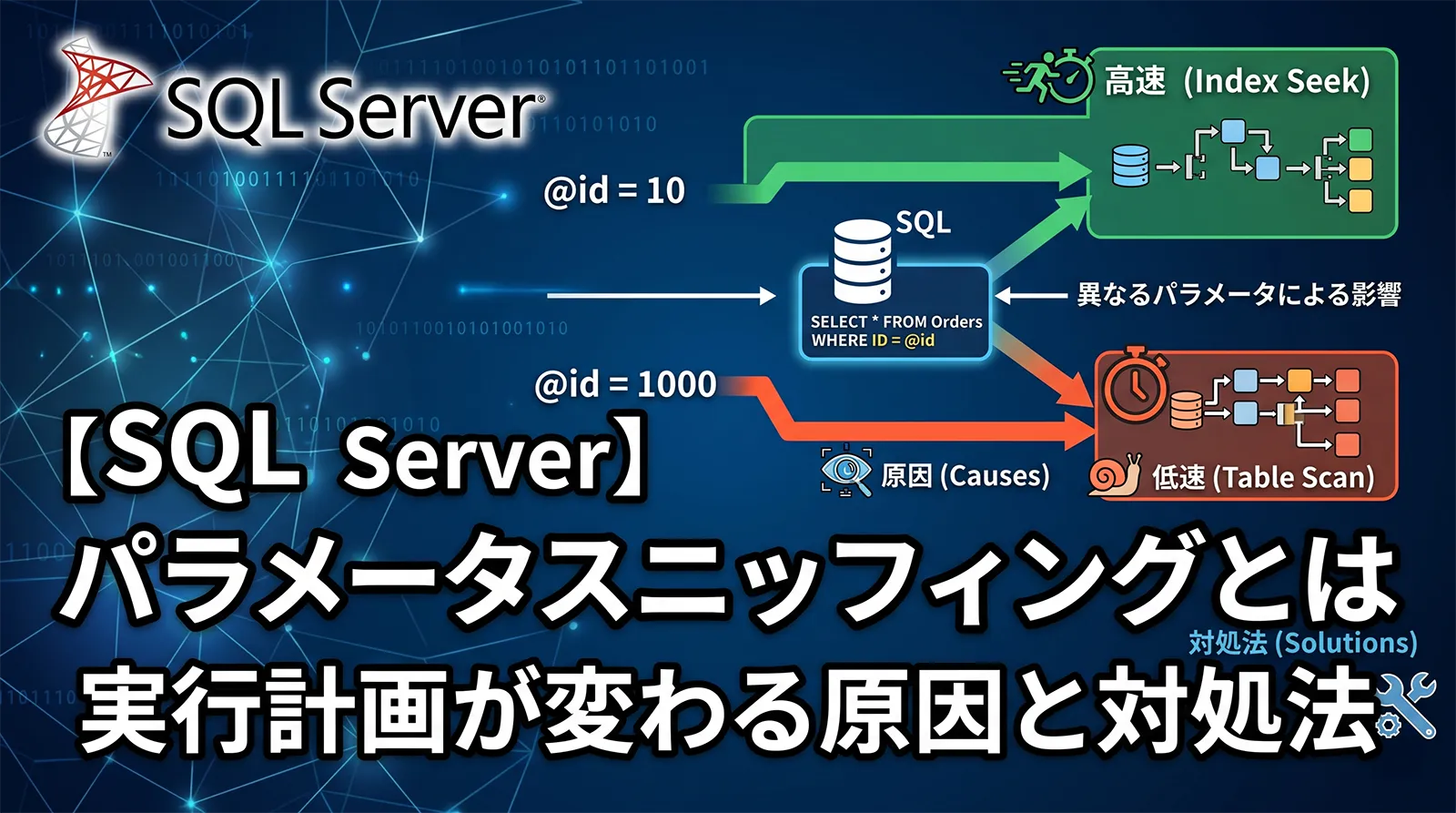
| 特定パラメータだけ遅い | データの偏りやパラメータスニッフィングの影響を受ける | 実際のパラメータ値、推定行数と実際の行数 |
| インデックスを作ったのに使われない | 統計情報や条件式の影響で選択性を見誤っている | 統計情報、WHERE句、暗黙変換、列側関数 |
| SortやHash MatchがSpillする | メモリ見積もりが外れている可能性がある | 実行計画の警告、tempdb使用量、統計情報の鮮度 |
tempdb が増える場合も、実行計画の見積もりズレからSortやHash MatchがSpillしていることがあります。その場合は統計情報だけでなく、実行計画と tempdb の使用内訳も合わせて確認します。
SQL Serverでtempdbが肥大化する原因と確認方法
AUTO_UPDATE_STATISTICSを確認する
まず、データベースの自動統計更新が有効か確認します。通常は AUTO_UPDATE_STATISTICS を ON にしておくのが基本です。OFF の場合、統計情報が古くなっても自動更新されず、古い統計に基づいた実行計画が選ばれ続けることがあります。
SELECT
name AS database_name,
is_auto_create_stats_on,
is_auto_update_stats_on,
is_auto_update_stats_async_on
FROM sys.databases
WHERE name = DB_NAME();
| 設定 | 意味 | 基本方針 |
|---|---|---|
AUTO_CREATE_STATISTICS |
必要に応じて単一列統計を自動作成する | 通常はON |
AUTO_UPDATE_STATISTICS |
古くなった統計情報を必要に応じて自動更新する | 通常はON |
AUTO_UPDATE_STATISTICS_ASYNC |
統計更新を非同期で行う | 即時のコンパイル待ちを避けたい環境で検討 |
設定を変更する場合は、影響範囲を理解してから行います。AUTO_UPDATE_STATISTICS_ASYNC をONにすると、統計更新待ちによるコンパイル遅延を避けられる一方で、最初の実行では古い統計情報に基づく計画が使われることがあります。
ALTER DATABASE YourDatabaseName SET AUTO_CREATE_STATISTICS ON; ALTER DATABASE YourDatabaseName SET AUTO_UPDATE_STATISTICS ON; -- 必要な場合だけ検討 ALTER DATABASE YourDatabaseName SET AUTO_UPDATE_STATISTICS_ASYNC ON;
自動更新がONでも、データ変更の直後に必ず統計情報が更新されるわけではありません。SQL Serverは統計情報が古くなったと判断したタイミングで更新します。そのため、大量ロード直後に重要なSQLを実行する処理や、データ分布が極端に偏るテーブルでは、自動更新だけでは実行計画の見積もりが追いつかないことがあります。
NORECOMPUTEで自動更新が止まっていないか確認する
統計情報単位で NORECOMPUTE が設定されていると、データベースの AUTO_UPDATE_STATISTICS がONでも、その統計情報は自動更新されません。過去のチューニングやメンテナンスで設定されていることがあるため、遅いSQLの対象テーブルでは no_recompute も確認します。
SELECT
SCHEMA_NAME(o.schema_id) AS schema_name,
o.name AS table_name,
s.name AS stats_name,
s.no_recompute,
s.auto_created,
s.user_created
FROM sys.stats AS s
JOIN sys.objects AS o
ON o.object_id = s.object_id
WHERE o.type = 'U'
AND s.no_recompute = 1
ORDER BY schema_name, table_name, stats_name;
NORECOMPUTE を安易に使うと、統計情報が古いまま残り、不適切な実行計画につながることがあります。特別な理由がない限り、統計情報の自動更新を止める運用は避けます。解除したい場合は、対象統計を NORECOMPUTE なしで更新します。
-- NORECOMPUTEを付けずに更新すると、対象統計の自動更新を再び有効にできる UPDATE STATISTICS dbo.Orders IX_Orders_OrderDate;
統計情報の更新日時と変更行数を確認する
統計情報が古いかどうかを確認するには、sys.stats と sys.dm_db_stats_properties を使います。last_updated は最後に統計情報が更新された日時、rows は更新時点の行数、rows_sampled はサンプリング行数、modification_counter は統計情報の先頭列に対する変更行数の目安です。
SELECT
SCHEMA_NAME(o.schema_id) AS schema_name,
o.name AS table_name,
s.name AS stats_name,
sp.last_updated,
sp.rows,
sp.rows_sampled,
sp.modification_counter,
s.auto_created,
s.user_created,
s.no_recompute,
s.has_filter,
s.filter_definition
FROM sys.stats AS s
JOIN sys.objects AS o
ON o.object_id = s.object_id
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS sp
WHERE o.type = 'U'
ORDER BY sp.modification_counter DESC, sp.last_updated;
特定テーブルだけ見る場合は、OBJECT_ID で絞ります。
SELECT
s.name AS stats_name,
sp.last_updated,
sp.rows,
sp.rows_sampled,
sp.modification_counter
FROM sys.stats AS s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS sp
WHERE s.object_id = OBJECT_ID(N'dbo.Orders')
ORDER BY sp.modification_counter DESC;
STATS_DATE でも更新日時を確認できます。ただし、変更行数やサンプリング行数も見たい場合は sys.dm_db_stats_properties のほうが便利です。
last_updated が NULL になることもあります。新規の空テーブルや、フィルター条件に一致する行がないフィルター統計では、統計情報の実体がまだ作られていない場合があるためです。単にNULLだから異常と判断せず、対象テーブルの行数やフィルター条件も確認します。
SELECT
s.name AS stats_name,
STATS_DATE(s.object_id, s.stats_id) AS stats_last_updated
FROM sys.stats AS s
WHERE s.object_id = OBJECT_ID(N'dbo.Orders');
UPDATE STATISTICSの基本
統計情報を手動更新する基本は UPDATE STATISTICS です。統計情報単位、テーブル単位、インデックス統計を含む全統計情報など、対象を選んで更新できます。
| 更新範囲 | SQL例 | 使いどころ |
|---|---|---|
| 特定統計 | UPDATE STATISTICS dbo.Orders IX_Orders_OrderDate; |
原因統計が明確なとき |
| テーブル内の統計 | UPDATE STATISTICS dbo.Orders; |
対象テーブルのSQLが遅いとき |
| DB内の更新が必要な統計 | EXEC sp_updatestats; |
DB全体でメンテナンスしたいとき |
-- 特定の統計情報だけ更新 UPDATE STATISTICS dbo.Orders IX_Orders_OrderDate; -- テーブル内の統計情報を更新 UPDATE STATISTICS dbo.Orders; -- データベース内の統計情報をまとめて更新 EXEC sp_updatestats;
対象が明確な場合は、いきなりDB全体を更新せず、問題SQLに関係するテーブルや統計から確認します。DB全体の統計更新は、再コンパイルやIO負荷を引き起こすことがあるため、実行時間帯に注意します。
FULLSCAN・SAMPLE・RESAMPLEの使い分け
UPDATE STATISTICS では、統計情報をどの程度のデータから作るかを指定できます。常に FULLSCAN が最善とは限りません。大きなテーブルでは負荷が高く、更新時間も長くなります。
| 指定 | 意味 | 使いどころ |
|---|---|---|
指定なし |
SQL Serverがサンプルサイズを決める | 多くの通常運用 |
FULLSCAN |
全行を読んで統計を作る | データ分布の偏りが強い重要テーブル、検証時 |
SAMPLE n PERCENT |
指定割合でサンプリングする | FULLSCANは重いが、既定サンプルより精度を上げたいとき |
RESAMPLE |
前回のサンプル率で更新する | 同じサンプル率を維持したいとき |
-- 既定サンプリング UPDATE STATISTICS dbo.Orders IX_Orders_OrderDate; -- 全件スキャン。大きいテーブルでは負荷に注意 UPDATE STATISTICS dbo.Orders IX_Orders_OrderDate WITH FULLSCAN; -- サンプル率を指定 UPDATE STATISTICS dbo.Orders IX_Orders_OrderDate WITH SAMPLE 30 PERCENT; -- 前回のサンプル率を使用 UPDATE STATISTICS dbo.Orders IX_Orders_OrderDate WITH RESAMPLE;
日付やステータスなどでデータ分布が偏っている場合、既定サンプリングでは見積もりが外れることがあります。その場合は、対象統計だけ FULLSCAN や高めの SAMPLE を検証します。ただし、複雑な実行計画ではFULLSCANにしても必ず速くなるとは限りません。改善前後の実行計画と STATISTICS IO で確認します。
DB全体を更新するsp_updatestats
sp_updatestats は、現在のデータベース内のユーザー定義テーブルと内部テーブルに対して、UPDATE STATISTICS を実行するストアドプロシージャです。ディスクベースのテーブルでは、sys.dm_db_stats_properties の変更情報に基づいて、少なくとも1行変更された統計が更新対象になります。
USE YourDatabaseName; GO EXEC sp_updatestats; -- 前回のサンプル率を使いたい場合 EXEC sp_updatestats 'resample';
sp_updatestats は便利ですが、必要以上に頻繁に実行するものではありません。統計更新によってストアドプロシージャやクエリの再コンパイルが起き、一時的にCPUやIOが増えることがあります。特に大きなDBでは、対象テーブルを絞った更新や、メンテナンス時間帯での実行を検討します。
DBCC SHOW_STATISTICSで中身を見る
統計情報の中身を詳しく見たい場合は、DBCC SHOW_STATISTICS を使います。ヘッダー、密度情報、ヒストグラムを確認できます。特にヒストグラムを見ると、先頭列の値分布や範囲ごとの行数を把握できます。
DBCC SHOW_STATISTICS (N'dbo.Orders', N'IX_Orders_OrderDate'); -- ヒストグラムだけ確認 DBCC SHOW_STATISTICS (N'dbo.Orders', N'IX_Orders_OrderDate') WITH HISTOGRAM;
| 出力 | 見ること |
|---|---|
| Header | 更新日時、行数、サンプリング行数、ステップ数 |
| Density Vector | 複合列統計の密度情報 |
| Histogram | 統計の先頭列の値分布 |
複合インデックスの統計では、ヒストグラムは先頭列を中心に作られます。複合インデックスがあるのに見積もりが外れる場合は、列順や検索条件との対応も確認します。
統計情報更新後に改善したか確認する
統計情報を更新したら、必ず改善前後を比較します。見たいのは、実行時間だけではありません。推定行数と実際の行数のズレ、logical reads、CPU時間、実行計画の変化も確認します。
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
-- 対象SQLを実行して、実行計画とIOを確認する
SELECT
OrderID,
CustomerID,
OrderDate,
TotalAmount
FROM dbo.Orders
WHERE OrderDate >= '2026-01-01'
AND OrderDate < '2026-02-01';
SET STATISTICS TIME OFF;
SET STATISTICS IO OFF;
日付条件では、列側を関数で加工するとインデックスや統計情報を活かしにくくなることがあります。日付のみで比較したい場合も、列側を加工せず範囲条件にするのが基本です。
統計情報更新でロックやログに注意する
統計情報の更新は、読み取りや計算の負荷が発生します。大きなテーブルで FULLSCAN を行うと、IO負荷が高くなり、実行中のSQLに影響することがあります。また、運用中のメンテナンス作業では、ロック待ちやトランザクションログの使用量も合わせて確認します。
ロック待ちが疑われる場合は、統計情報より先にブロッキング元を確認します。
大量更新やメンテナンスでログが増える場合は、復旧モデルやログバックアップの状態も確認します。
SQL Serverでトランザクションログがいっぱいになる原因と対処法
メンテナンスジョブの考え方
統計情報更新は、毎回DB全体をFULLSCANするより、対象を絞って実行するほうが現実的です。重要テーブル、更新量の多いテーブル、実行計画の見積もりが外れやすいSQLに関係する統計を優先します。
| 方針 | 内容 |
|---|---|
| 通常 | AUTO_CREATE_STATISTICS と AUTO_UPDATE_STATISTICS をONにする |
| 日次・週次 | 変更量の多い重要テーブルを中心に統計更新する |
| 障害調査時 | 対象SQLの実行計画から関係する統計を絞って更新する |
| 大規模テーブル | FULLSCANではなく、必要な統計だけSAMPLE率を調整する |
| 更新後 | 実行計画、logical reads、CPU時間、ロック影響を比較する |
SELECT
SCHEMA_NAME(o.schema_id) AS schema_name,
o.name AS table_name,
s.name AS stats_name,
sp.last_updated,
sp.rows,
sp.modification_counter,
CAST(sp.modification_counter * 100.0 / NULLIF(sp.rows, 0) AS decimal(10,2)) AS modified_percent
FROM sys.stats AS s
JOIN sys.objects AS o
ON o.object_id = s.object_id
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS sp
WHERE o.type = 'U'
AND sp.rows >= 10000
AND sp.modification_counter >= 1000
ORDER BY modified_percent DESC, sp.modification_counter DESC;
このSQLは候補抽出の例です。閾値はシステムのデータ量、更新頻度、重要SQLに合わせて調整します。単純に変更率だけで判断せず、実行計画の見積もりズレや業務影響も見ます。
やってはいけない対応
統計情報更新は便利ですが、雑に実行すると別の問題を作ります。特に本番環境では、次の対応は避けます。
| NG対応 | なぜ危ないか | 代わりにやること |
|---|---|---|
| 毎回DB全体をFULLSCANする | 大きなIO負荷と再コンパイルが発生しやすい | 対象テーブル・統計を絞る |
| 遅いSQLを見ずに統計だけ更新する | ロック待ち、SQLの書き方、インデックス不足が原因かもしれない | 実行計画と待機情報を先に確認する |
| AUTO_UPDATE_STATISTICSをOFFにする | 古い統計に基づく実行計画が使われ続ける | 特殊な理由がなければONを維持する |
| NORECOMPUTEを付けたまま放置する | 対象統計だけ自動更新されず、データ分布の変化に追従できない | 必要性を確認し、不要ならNORECOMPUTEなしで更新する |
| 効果測定せずに運用へ入れる | 計画が変わって別SQLが遅くなることがある | 改善前後のIO・時間・計画を保存する |
| 統計更新で必ず速くなると考える | 統計以外が原因なら改善しない | インデックス、SQL、ロック、tempdbも確認する |
よくある質問
UPDATE STATISTICSはいつ実行すればよいですか?
大量更新後、実行計画の推定行数と実際の行数が大きくズレているとき、特定テーブルに関係するSQLが急に遅くなったときに検討します。まず対象SQLと対象統計を絞って確認します。
sp_updatestatsを毎日実行してもよいですか?
小規模DBなら問題になりにくいこともありますが、大きなDBでは負荷や再コンパイルが問題になることがあります。変更量の多いテーブル、重要SQLに関係するテーブルを優先する運用が現実的です。
FULLSCANにすれば必ず速くなりますか?
必ずではありません。FULLSCANは統計の精度を上げられる可能性がありますが、負荷が高く、複雑な計画では効果が限定的なこともあります。実行計画と STATISTICS IO で比較します。
AUTO_UPDATE_STATISTICSがONなら手動更新は不要ですか?
通常は自動更新で十分なことが多いですが、データ分布が偏っているテーブル、更新直後に重要SQLを実行する処理、昇順キーの最新範囲を検索するSQLでは、手動更新を検討することがあります。
統計情報を更新すると実行計画は必ず変わりますか?
必ず変わるわけではありません。ただし統計更新によって再コンパイルが起き、新しい統計に基づく実行計画が選ばれる可能性があります。重要SQLでは更新前後の計画を保存して比較します。
インデックス再構築と統計情報更新は別物ですか?
別物です。インデックス再構築では関連するインデックス統計が更新されますが、すべての列統計や自動作成統計が更新されるとは限りません。断片化対策と統計情報更新は目的を分けて考えます。
まとめ
SQL Serverの統計情報は、実行計画の行数見積もりを支える重要な情報です。統計情報が古い、またはデータ分布をうまく表せていないと、Index Seek、Key Lookup、Hash Match、Sort などの選択がズレ、SQLが遅くなることがあります。
調査では、まず実行計画で推定行数と実際の行数を確認し、sys.dm_db_stats_properties で更新日時、サンプリング行数、変更行数を見ます。対象が明確なら UPDATE STATISTICS、DB全体なら sp_updatestats を検討します。ただし、統計情報更新は万能ではありません。SQLの書き方、インデックス、ロック待ち、tempdb、トランザクションログへの影響も合わせて見ながら、改善前後を実測して判断しましょう。