「AIにPRレビューを任せたら、今度は別のAIが新しい指摘を出した」——収束するはずのループが発散する。この経験をした開発者は少なくないはずです。
1つのAIに全部やらせると観点が浅く、複数のAIを並列で回すと収束しない。では、どう設計すればいいのか。
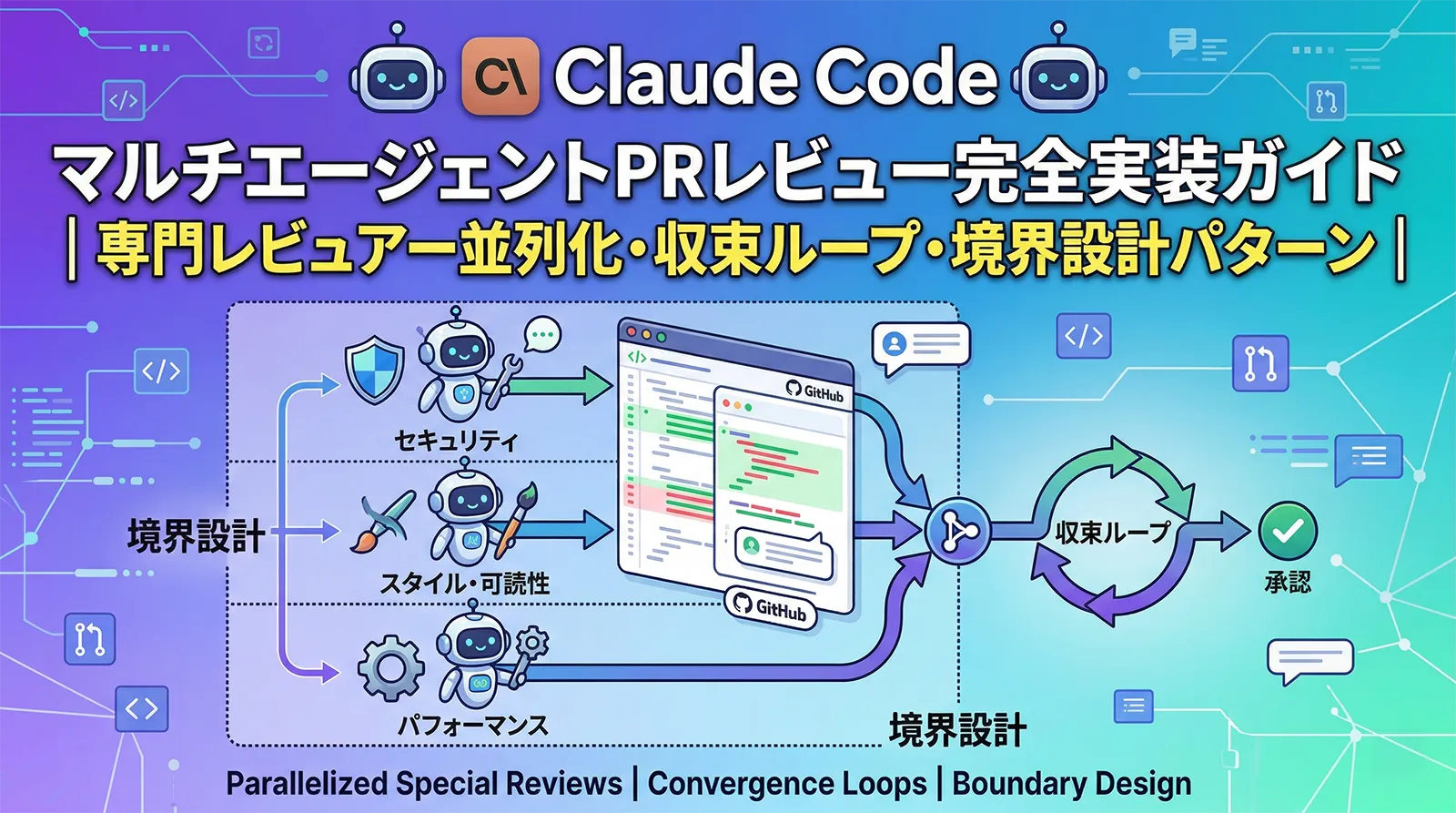
この記事では、Claude Code のSubagents・Skillsを活用して、複数の専門レビュアーを並列実行し、妥当性検証層を挟んで収束ループを安全に動かす実装パターンを解説します。「何を自動化して何を人間に返すか」という境界設計まで含めて体系的にまとめました。
シングルAIレビューが陥る3つの罠
Claude Code に「このPRをレビューして」と投げると、それなりの指摘は返ってきます。しかし実務で使い続けると、いくつかの限界が見えてきます。
観点の浅さ
1つのプロンプトで「ロジック・セキュリティ・テスト・設計・可読性」を全部カバーしようとすると、どれも表面的な確認になります。セキュリティ視点でコードを読むのと、テストカバレッジを精査するのでは、着目点が全く異なります。1つのコンテキストで全部こなすと、各観点の深度が犠牲になります。
指摘の揺らぎ
同じコードを繰り返しレビューさせると、毎回微妙に異なる指摘が出ます。これはモデルの確率的な性質によるもので、ある実行では見つかった問題が次の実行では見落とされることがあります。並列で複数エージェントを走らせると、この揺らぎが各観点に独立して影響するため、全体としての網羅性が上がります。
収束しない修正ループ
「指摘 → 修正 → 再レビュー」を繰り返すとき、前のエージェントが直した箇所に別のエージェントが新しい指摘を出す、という現象が起きます。安全弁なしで「指摘ゼロになるまで回す」ループを組むと、無限に近い状態に陥ります。重要なのは、ゼロを目指すことではなく、いつ人間に返すかの判断基準を設計することです。
この記事のスコープ: 以降では、上記3つの問題を解決するために「専門化・並列化・収束制限」を組み合わせた実装パターンを解説します。Claude Code Subagentsの基礎やSkillsの基本的な使い方を前提知識として持っておくと理解しやすいです。
設計の全体像
マルチエージェントレビューを安全に動かすには、3層の構造が必要です。
| 層 | 役割 | 実装 |
|---|---|---|
| レビュー層 | 専門エージェントが並列でコードを精査 | Skills(context: fork) |
| 検証層 | 指摘の妥当性をコンテキストと照合して精査 | バリデーションエージェント |
| 修正層 | Critical/Warningのみ自動修正、設計判断はスキップ | 修正エージェント + 安全弁 |
これを「レビュー → 検証 → 修正 → 再レビュー」のループで回します。ポイントは、このループを5ラウンド上限・20ファイル超で中断・テスト失敗3回でアボートという安全弁で囲んでいることです。
# 収束ループ(擬似コード) loop (max: 5 rounds): 1. 専門レビュアーを並列起動(context: fork) 2. 指摘を統合テーブルに集約 3. バリデーターが妥当性を検証(ノイズ除去) 4. Critical/Warning のみ自動修正対象に 5. 修正適用(スコープ: 20ファイル未満) 6. テスト実行(失敗3回でアボート) 7. 指摘ゼロ → break / 残存 → 次のラウンドへ end: 未解決の指摘をサマリーとして人間に返す
専門レビュアーの役割設計
単一のレビュアーを分割するとき、重要なのは観点が重複しないよう境界を明確にすることです。境界が曖昧だと同じ指摘が複数のレビュアーから出て、後段の統合処理が複雑になります。
| レビュアー名 | 担当観点 | 主な確認項目 |
|---|---|---|
| Code Reviewer | ロジック正確性 | エッジケース・エラー処理・境界値・null安全性・競合状態 |
| Security Reviewer | セキュリティ | SQLインジェクション・XSS・認証バイパス・シークレット露出・入力バリデーション |
| Test Reviewer | テスト品質 | カバレッジ不足・アサーション弱さ・モック過剰・テスト間依存 |
| Design Reviewer | 設計・責務分離 | 単一責任原則・集約境界・ドメインロジック漏れ・依存方向 |
| Readable Code Reviewer | 可読性 | 命名の明確さ・ネスト深度・マジックナンバー・コメント品質 |
| Spec Reviewer | 仕様整合性 | 要件との乖離・後方互換性・API契約違反・過去のrevert との不整合 |
6人である必要はありません: チームの規模や開発フェーズによって、最初は Code・Security・Test の3観点から始めるのが現実的です。後述のCI統合では軽量な3観点版も紹介します。
Skillsファイルの実装
各レビュアーを Claude Code の Skills として定義します。Skills設計の詳細については別記事で解説していますが、レビュー用Skillsで特に重要な設定を以下に示します。
ディレクトリ構成
.claude/
└── skills/
├── code-reviewer/
│ └── SKILL.md
├── security-reviewer/
│ └── SKILL.md
├── test-reviewer/
│ └── SKILL.md
├── design-reviewer/
│ └── SKILL.md
├── readable-code-reviewer/
│ └── SKILL.md
├── spec-reviewer/
│ └── SKILL.md
├── review-validator/
│ └── SKILL.md
└── review-fixer/
└── SKILL.md
Code Reviewer の実装例
---
name: code-reviewer
description: Logical correctness reviewer. Checks edge cases, error handling, null safety, race conditions, boundary values in changed code. Use when reviewing PR diff for correctness issues.
context: fork
agent: Explore
allowed-tools: Read, Grep, Glob, Bash
---
あなたはロジック正確性を専門とするコードレビュアーです。
## レビュー対象
引数で渡されたPR差分ファイルを対象とします。
変更箇所だけでなく、影響する呼び出し元・呼び出し先も確認してください。
## 確認項目
- エッジケース(空配列、null、0、最大値)の処理
- エラーハンドリングの欠落・握りつぶし
- 競合状態・非同期処理の順序問題
- 境界値(off-by-one)エラー
- 型の安全性(型アサーション・as キャストの乱用)
- 早期リターンの欠落による深いネスト
## 出力形式
以下のJSONで出力してください(他の文字は一切出力しない):
{
"reviewer": "code-reviewer",
"findings": [
{
"severity": "critical|warning|info",
"file": "ファイルパス",
"line": 行番号,
"message": "指摘内容(日本語)",
"suggestion": "修正案(コードスニペット、任意)"
}
]
}
Security Reviewer の実装例
--- name: security-reviewer description: Security vulnerability reviewer. Checks SQL injection, XSS, auth bypass, secrets exposure, input validation in code changes. Use for any PR touching auth, data access, or external input handling. context: fork agent: Explore allowed-tools: Read, Grep, Glob --- あなたはセキュリティを専門とするコードレビュアーです。 ## 確認項目 - SQLインジェクション(プリペアドステートメントの未使用) - XSS(ユーザー入力のHTMLへの直接埋め込み) - 認証・認可バイパス(ミドルウェアの欠落、権限チェック不足) - シークレット・認証情報のハードコード - 入力バリデーションの欠落 - パストラバーサル - CSRF対策の欠落 ## 出力形式 code-reviewer と同じJSON形式で出力してください。 reviewerフィールドは "security-reviewer" とすること。
Review Validator の実装例(妥当性検証層)
---
name: review-validator
description: Validates review findings from multiple reviewers. Removes false positives, duplicate findings, and context-blind suggestions. Use after collecting all reviewer outputs to filter before auto-fix.
context: fork
agent: Explore
allowed-tools: Read, Grep, Glob
---
あなたはコードレビューの指摘を検証するバリデーターです。
## 入力
複数のレビュアーからの指摘リスト(JSON配列)を受け取ります。
## 検証ルール
以下の条件に当てはまる指摘は "rejected" としてください:
1. **コンテキスト無視**: 既に対処済みの問題を指摘している(他のファイルや既存の処理を確認していない)
2. **重複**: 複数のレビュアーが同一の問題を指摘している(最初の1件を残す)
3. **設計方針の誤解**: このプロジェクトの既存パターンと矛盾する一般論的な指摘
4. **スコープ外**: PR差分と無関係なファイルへの指摘
## 重要な制約
- 確信がない場合は "accepted" として残してください(誤却下のリスクを避ける)
- Critical severity の指摘は原則 accepted とすること
## 出力形式
{
"validated_findings": [
{
...元の指摘フィールド,
"validation_status": "accepted|rejected",
"rejection_reason": "却下理由(rejectedの場合のみ)"
}
]
}
Review Fixer の実装例(修正層)
---
name: review-fixer
description: Applies validated review findings automatically. Only fixes critical and warning severity issues. Skips architectural decisions and design-choice changes. Use after validation step with filtered findings list.
context: fork
allowed-tools: Read, Edit, Bash
---
あなたは検証済みの指摘に基づいてコードを修正するエージェントです。
## 修正の原則
1. **最小限の変更**: 指摘された箇所のみを修正する。周辺のリファクタリングは一切しない
2. **設計判断はスキップ**: 「このクラスの責務が広すぎる」「アーキテクチャを変更すべき」
など設計判断が必要な指摘は修正せず、スキップリストに追加する
3. **テストは必ず実行**: 修正後に `npm test` または `pytest` を実行し、失敗したら修正を巻き戻す
4. **1ファイルずつ**: 複数ファイルの連鎖的な変更が必要な場合はスキップする
## 安全弁(必ず守ること)
- 変更対象が20ファイルを超える場合: 全件スキップして人間に委譲
- テスト失敗が3回続いた場合: 修正を全て巻き戻してアボート
- 修正前後でテスト結果が変わった場合: 差分を必ず記録する
## 出力形式
{
"fixed": ["修正したfile:line の説明"],
"skipped": ["スキップした指摘とその理由"],
"test_result": "passed|failed|aborted",
"abort_reason": "アボート理由(あれば)"
}
収束ループの実装
Skillsの定義が揃ったら、これらをオーケストレートする収束ループを組みます。Claude Code のワークフロー機能を活用して、CLAUDE.mdにループの司令塔を定義します。
CLAUDE.md でループを定義する
# PRレビュー収束ループ ## /review-pr コマンド `/review-pr` が呼ばれたら以下のループを実行する: ### 事前準備 1. `git diff main...HEAD --name-only` でPR差分ファイルを取得 2. ファイルをカテゴリ別に分類(src/, tests/, config/ など) ### 収束ループ(最大5ラウンド) ラウンドごとに以下を実行: **Step 1: 並列レビュー** 以下のSkillsを並列起動(context:forkにより独立実行): - /code-reviewer [diff_files] - /security-reviewer [diff_files] - /test-reviewer [diff_files] - /design-reviewer [diff_files] - /readable-code-reviewer [diff_files] - /spec-reviewer [diff_files] **Step 2: 指摘統合** 全レビュアーの出力JSONを統合し、findings テーブルを作成 **Step 3: 妥当性検証** /review-validator [findings_json] を実行 **Step 4: 修正** accepted かつ critical/warning の指摘のみ /review-fixer に渡す **Step 5: 評価** - fixer の test_result が "failed" or "aborted" → ループ中断 - accepted findings が0件 → ループ終了(成功) - ラウンド5完了 → ループ終了(未解決あり) ### 終了時出力 - 解決済み指摘の一覧 - 未解決(スキップ・人間委譲)指摘の一覧 - 各ラウンドの指摘数推移
TypeScriptでのオーケストレーション実装
CLAUDE.mdでの自然言語定義に加えて、より確実に制御したい場合はTypeScriptスクリプトでオーケストレーションを実装する方法もあります。
import { exec, execSync } from 'child_process';
import { promisify } from 'util';
import * as fs from 'fs';
const execAsync = promisify(exec);
interface Finding {
reviewer: string;
severity: 'critical' | 'warning' | 'info';
file: string;
line: number;
message: string;
suggestion?: string;
validation_status?: 'accepted' | 'rejected';
}
interface RoundResult {
round: number;
totalFindings: number;
acceptedFindings: number;
fixedCount: number;
skippedCount: number;
testResult: string;
}
const REVIEWERS = [
'code-reviewer',
'security-reviewer',
'test-reviewer',
'design-reviewer',
'readable-code-reviewer',
'spec-reviewer',
];
const MAX_ROUNDS = 5;
async function runReviewLoop(): Promise<void> {
const diffFiles = getDiffFiles();
if (diffFiles.length === 0) {
console.log('差分なし。レビューをスキップします。');
return;
}
const history: RoundResult[] = [];
for (let round = 1; round <= MAX_ROUNDS; round++) {
console.log(`\n=== ラウンド ${round}/${MAX_ROUNDS} ===`);
// Step 1: 並列レビュー(各Skillを個別プロセスで起動)
const allFindings = await runParallelReviewers(diffFiles);
console.log(` レビュー指摘数: ${allFindings.length}`);
if (allFindings.length === 0) {
console.log('指摘なし。ループを終了します。');
break;
}
// Step 2: 妥当性検証
const validatedFindings = await runValidator(allFindings);
const accepted = validatedFindings.filter(f => f.validation_status === 'accepted');
console.log(` 妥当と判定された指摘: ${accepted.length}/${allFindings.length}`);
const actionable = accepted.filter(f => f.severity !== 'info');
if (actionable.length === 0) {
console.log('自動修正対象なし。ループを終了します(infoのみ)。');
outputSummary(history, accepted);
return;
}
// Step 3: 修正
const fixResult = await runFixer(actionable);
const roundResult: RoundResult = {
round,
totalFindings: allFindings.length,
acceptedFindings: accepted.length,
fixedCount: fixResult.fixed.length,
skippedCount: fixResult.skipped.length,
testResult: fixResult.test_result,
};
history.push(roundResult);
if (fixResult.test_result === 'aborted' || fixResult.test_result === 'failed') {
console.log(`テスト${fixResult.test_result}。ループを中断します。`);
outputSummary(history, accepted);
return;
}
}
outputSummary(history, []);
}
function getDiffFiles(): string[] {
try {
const output = execSync('git diff main...HEAD --name-only').toString();
return output.trim().split('\n').filter(Boolean);
} catch {
return [];
}
}
async function runParallelReviewers(files: string[]): Promise<Finding[]> {
// 実際の実装では claude -p でヘッドレス実行
// ここでは並列実行のコンセプトを示す
const promises = REVIEWERS.map(reviewer =>
runSkill(reviewer, files)
);
const results = await Promise.all(promises);
return results.flat();
}
async function runSkill(skillName: string, files: string[]): Promise<Finding[]> {
// ファイル一覧はファイル経由で渡す(ARGMAXを避けるため直接埋め込まない)
const tmpFile = `/tmp/review-files-${skillName}.txt`;
fs.writeFileSync(tmpFile, files.join('\n'));
const prompt = `/${skillName} $(cat ${tmpFile})`;
// execAsync で真の非同期実行(Promise.all での並列実行に対応)
const { stdout } = await execAsync(
`claude -p "${prompt}" --output-format json --max-turns 5`,
{ timeout: 120000 }
);
try {
const result = JSON.parse(stdout);
return result.findings || [];
} catch {
return [];
}
}
async function runValidator(findings: Finding[]): Promise<Finding[]> {
const tmpFile = '/tmp/review-findings.json';
fs.writeFileSync(tmpFile, JSON.stringify(findings));
const { stdout } = await execAsync(
`claude -p "/review-validator $(cat ${tmpFile})" --output-format json --max-turns 3`,
{ timeout: 60000 }
);
const result = JSON.parse(stdout);
return result.validated_findings || findings;
}
async function runFixer(findings: Finding[]): Promise<any> {
const tmpFile = '/tmp/review-actionable.json';
fs.writeFileSync(tmpFile, JSON.stringify(findings));
const { stdout } = await execAsync(
`claude -p "/review-fixer $(cat ${tmpFile})" --output-format json --max-turns 10`,
{ timeout: 300000 }
);
return JSON.parse(stdout);
}
function outputSummary(history: RoundResult[], remaining: Finding[]): void {
console.log('\n=== レビューサマリー ===');
history.forEach(r => {
console.log(`ラウンド${r.round}: 指摘${r.totalFindings}件 → 修正${r.fixedCount}件 スキップ${r.skippedCount}件 [${r.testResult}]`);
});
if (remaining.length > 0) {
console.log(`\n未解決(人間レビュー推奨): ${remaining.length}件`);
remaining.forEach(f => console.log(` [${f.severity}] ${f.file}:${f.line} - ${f.message}`));
}
}
runReviewLoop().catch(console.error);
妥当性検証層の設計思想
6つのレビュアーを並列で走らせると、必ずノイズが混じります。「AIの指摘をAIで検証する」この層は、レビュー品質を決定的に左右します。
よくある誤指摘のパターン
| パターン | 具体例 | バリデーターの判定 |
|---|---|---|
| コンテキスト無視型 | 「入力バリデーションがない」→ 上位レイヤーで既に検証済み | 既存のミドルウェアを確認して却下 |
| 重複型 | Code/Readable の2人が同じ命名問題を指摘 | 後出しを重複として却下 |
| 設計方針誤解型 | 「リポジトリパターンを使うべき」→ このプロジェクトは意図的に使わない | プロジェクトパターンを確認して却下 |
| スコープ外型 | 変更と無関係なファイルの既存バグを指摘 | 差分外なので情報提供に降格 |
誤却下のリスクに注意: バリデーターが「コンテキスト無視型」と判断した指摘が、実は正当だったケースもあります。特にCriticalレベルの指摘は原則として却下しない設計にしておくことを強く推奨します。バリデーターは「ノイズを減らすフィルタ」であって、「完璧な判定器」ではありません。
バリデーターの精度を上げるには
バリデーターが参照できる情報を増やすことが精度向上の鍵です。以下のファイルをバリデーターのコンテキストとして渡すと効果的です。
# アーキテクチャ上の設計判断を記録 docs/architecture-decisions.md # このプロジェクトで使うコーディングパターン .claude/project-patterns.md # 意図的に採用していない(しない)パターン .claude/excluded-patterns.md
特に「このプロジェクトでは意図的に〇〇パターンを使わない」という情報は、Design Reviewer との齟齬を大幅に減らします。CLAUDE.mdに記述するか、専用ファイルに切り出してバリデーターに @import させましょう。
安全弁の設計:過剰修正を防ぐ境界
収束ループで最も危険なのは、「修正した箇所が別のレビュアーの新しい指摘を生む」というカスケードです。以下の5つの安全弁を必ず実装してください。
安全弁の一覧と設定値
| 安全弁 | 推奨値 | 理由 |
|---|---|---|
| 最大ラウンド数 | 5回 | 3回で収束しなければ構造的な問題がある可能性が高い |
| 修正ファイル上限 | 20ファイル | 広範囲の変更は予期せぬ副作用リスクが高い |
| テスト失敗リトライ上限 | 3回 | テストが通らない修正を繰り返すのは有害 |
| 1修正の影響ファイル数 | 1〜3ファイル | 連鎖的な変更が必要な修正は人間に委譲 |
| エージェント最大ターン数 | 10ターン | maxTurns でエージェントの暴走を防ぐ |
「修正しない」判断基準
どんな指摘を自動修正の対象外にするかは、ループの安定性に直結します。以下を基準として Review Fixer のプロンプトに明示してください。
# 自動修正スキップの基準 ## 設計判断が必要なもの - クラス/モジュールの責務分割 - インターフェースの変更 - データ構造の変更 - 外部APIの呼び出し方法の変更 ## リスクが高いもの - テスト以外のファイルとの連鎖変更(2ファイル超) - データベーススキーマへの影響 - 設定ファイルの変更 ## コンテキスト依存のもの - パフォーマンスのトレードオフ - 「〇〇パターンに変更すべき」という提案 - ビジネスロジックの解釈が必要な変更
Hooks を使ったシステムレベルの安全弁
Claude Code のHooks機能を使うと、エージェントが特定のコマンドを実行する前にチェックを挟めます。
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "scripts/validate-review-command.sh"
}
]
}
]
}
}
#!/bin/bash # Review Fixerが実行しようとするコマンドを検証 COMMAND="$CLAUDE_TOOL_INPUT_COMMAND" # git reset --hard, git checkout -- などの巻き戻し系は禁止 if echo "$COMMAND" | grep -E "git (reset --hard|checkout -- |clean -f)" > /dev/null 2>&1; then echo "ERROR: 破壊的なgitコマンドは自動修正で使用禁止です" >&2 exit 1 fi # npmスクリプト以外のシェルコマンドは制限 if echo "$COMMAND" | grep -E "^(rm -rf|chmod 777|curl.*\|.*sh)" > /dev/null 2>&1; then echo "ERROR: 危険なコマンドパターンが検出されました" >&2 exit 1 fi exit 0
CI統合:GitHub Actions への組み込み
6レビュアー版は深い分析ができますが、実行時間がかかります。PRのたびにCIで回すなら、Code・Security・Testの3観点に絞った軽量版がおすすめです。Claude Code GitHub Actionsの詳細設定も参照してください。
軽量3観点版のワークフロー
name: Claude Multi-Agent Review
on:
pull_request:
types: [opened, synchronize, reopened]
jobs:
code-review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Code Logic Review
uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: |
/code-reviewer
対象ファイル: $(git diff origin/main...HEAD --name-only | head -30 | tr "\n" " ")
claude_args: "--max-turns 5 --model claude-sonnet-4-6"
timeout-minutes: 10
security-review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Security Review
uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: |
/security-reviewer
対象ファイル: $(git diff origin/main...HEAD --name-only | head -30 | tr "\n" " ")
claude_args: "--max-turns 5 --model claude-sonnet-4-6"
timeout-minutes: 10
test-review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Test Coverage Review
uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: |
/test-reviewer
対象ファイル: $(git diff origin/main...HEAD --name-only | head -30 | tr "\n" " ")
claude_args: "--max-turns 5 --model claude-sonnet-4-6"
timeout-minutes: 10
review-summary:
needs: [code-review, security-review, test-review]
runs-on: ubuntu-latest
if: always()
steps:
- name: Summarize Review Results
run: |
echo "## レビュー完了" >> $GITHUB_STEP_SUMMARY
echo "- Code Review: ${{ needs.code-review.result }}" >> $GITHUB_STEP_SUMMARY
echo "- Security Review: ${{ needs.security-review.result }}" >> $GITHUB_STEP_SUMMARY
echo "- Test Review: ${{ needs.test-review.result }}" >> $GITHUB_STEP_SUMMARY
@claude メンション型のインタラクティブレビュー
常時CIで回すのではなく、レビュアーが必要に応じて特定の観点を依頼する形式もあります。PR上のコメントで @claude /security-reviewer と書くとそのスキルが起動します。
name: Claude Interactive Review
on:
issue_comment:
types: [created]
pull_request_review_comment:
types: [created]
jobs:
claude-review:
if: |
(github.event_name == 'issue_comment' || github.event_name == 'pull_request_review_comment')
&& contains(github.event.comment.body, '@claude')
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
issues: write
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
# コメント内容をそのままプロンプトとして渡す
prompt: ${{ github.event.comment.body }}
claude_args: "--max-turns 8"
自動化の限界と境界設計フレームワーク
マルチエージェントレビューを実際に回してみると、AIが得意なことと苦手なことの輪郭が見えてきます。この境界を認識せずに「全部AIに任せよう」とすると、品質低下または過剰修正のどちらかが起きます。
AIが代替できるレビュー(チェックリスト型)
| カテゴリ | 具体例 | AIの精度 |
|---|---|---|
| 命名・コードスタイル | 曖昧な変数名、略語、ネスト深度 | 高 |
| 定型セキュリティパターン | SQLインジェクション、XSS、シークレットのハードコード | 高 |
| テストカバレッジの欠落 | ハッピーパスのみでエラーケースのテストがない | 高 |
| エッジケースの列挙 | 空配列、null、境界値、型不一致 | 中〜高 |
| 未使用コード・デッドコード | インポートされているが使われていない関数 | 高 |
人間のレビュアーが担うべきレビュー
| カテゴリ | 具体例 | AIが苦手な理由 |
|---|---|---|
| 設計の妥当性 | このアーキテクチャ選択は3年後も維持できるか | 組織の戦略・技術的負債の文脈を知らない |
| ビジネス要件との整合 | この実装は要件定義の意図と合っているか | ビジネス文脈・ステークホルダーの優先度を知らない |
| PRの意図理解 | なぜこのアプローチを選んだか、他の方法は検討したか | 著者の判断プロセスを対話的に確認できない |
| チーム固有の判断 | 過去の障害事例からこのパターンは避ける | 暗黙知・口伝のコンテキストにアクセスできない |
| メンタリング的フィードバック | こう直せばいいだけでなく、なぜそうすべきかの説明 | 相手の理解レベルに合わせた説明が難しい |
実導入での効果: AIレビューを導入することで、人間のレビュアーが「コーディング規約の確認」や「明らかなバグ指摘」に費やす時間を削減でき、設計議論やアーキテクチャ判断に集中しやすくなるというのが実際の効果です。チェックリスト的なレビューはAIに任せ、人間は対話が必要な判断に注力する分業がうまく機能します。
チームへの段階的導入パターン
いきなり6レビュアー+収束ループを入れると、チームの混乱とコスト増が重なります。段階的に導入することを推奨します。
フェーズ1:Security レビューの単体導入(〜2週間)
最初は Security Reviewer だけを入れます。セキュリティ指摘は「正しいか間違いか」の判断がしやすく、チームがAIの指摘の質を評価するのに適しています。指摘に対してチームメンバーが「これは妥当」「これはノイズ」とフィードバックを蓄積していくことで、バリデーターの精度を上げるためのコンテキストが溜まります。
フェーズ2:3観点CI版の導入(〜1ヶ月)
Code・Security・Test の3観点でCIを回します。このフェーズでは自動修正は行わず、レビューコメントとして投稿するだけにします。人間のレビュアーが指摘の妥当性を判断し続けることで、プロジェクト固有の「スキップ基準」が明確になります。
フェーズ3:収束ループの導入(〜3ヶ月)
フェーズ2で蓄積した「スキップ基準」を Review Fixer のプロンプトに反映してから、自動修正ループを導入します。最初は Warning レベルのみを自動修正対象にして様子を見てください。Critical は人間の確認を必須とする運用から始めると安全です。
コスト目安
以下は差分100〜200行規模のPRを想定した参考値です。コードベースのサイズ・差分量・ラウンド数によって大きく変動します。
| 構成 | 1PR あたりの実行時間目安 | APIコスト目安 |
|---|---|---|
| Security のみ(claude-haiku-4-5) | 1〜2分 | 数円〜10円程度 |
| 3観点並列(claude-sonnet-4-6) | 3〜5分 | 20〜50円程度 |
| 6観点並列(claude-sonnet-4-6) | 5〜10分 | 50〜100円程度 |
| 6観点+収束ループ(claude-sonnet-4-6) | 15〜40分 | 150〜500円程度(ラウンド数次第) |
コストの見積もりは変動があります: 上記は参考値です。コードベースのサイズ・PRの差分量・ラウンド数によって大きく変動します。本番運用前に必ず小規模PRでコストを計測してください。Claude Codeの基本設定でAPIコスト管理の設定も確認しておきましょう。
よくある失敗パターンと対策
ループが収束しない
症状: 毎ラウンド指摘数が減らない、または増える。
原因: Review Fixer が指摘されていない箇所も「ついでにリファクタ」している。
対策: Fixer のプロンプトに「指摘箇所以外は一切変更しない」を明示し、Hooks で編集ファイル数を監視する。
バリデーターがほとんどの指摘を却下する
症状: accepted が全体の10%以下になる。
原因: バリデーターのプロンプトが厳しすぎる、またはコンテキストが少なすぎて「コンテキスト無視型」に分類しすぎている。
対策: 「確信がない場合は accepted に残す」を明示。Critical は無条件で accepted にするルールを追加する。
テストが修正前後で壊れる
症状: テスト失敗 → 巻き戻し → 同じ指摘 → テスト失敗、のループ。
原因: Fixer が修正した箇所に既存のテストが密結合している。
対策: テスト失敗時は「修正内容を人間に渡す」設計にする。Fixer に自動でテストを修正させると二次的なバグのリスクがある。
DDD/設計レビュアーだけノイズが多い
症状: Design Reviewer の指摘の却下率が他と比べて高い。
原因: 設計判断はチームの文脈なしには正確に評価できない。
対策: Design Reviewer の severity を info のみに制限し、自動修正対象から外す。人間への「参考情報」として出力する運用にとどめる。
よくある質問
まとめ
Claude Code でマルチエージェントPRレビューを実装する際の要点をまとめます。
| 要素 | 設計のポイント |
|---|---|
| 専門化 | 観点を重複なく分割し、各レビュアーが1つの責務に集中できるようにする |
| 並列化 | context: fork またはCIのjob並列で独立実行。サブエージェントのネストは不可 |
| 妥当性検証 | AIの指摘をAIで検証するが、Criticalは原則accepted。誤却下を避けた保守的設計で |
| 安全弁 | 5ラウンド上限・20ファイル超で中断・テスト失敗3回でアボート。最小限の変更のみ |
| 境界設計 | チェックリスト型はAIに任せ、設計判断・ビジネス整合・対話的FBは人間が担う |
これらを組み合わせることで、レビュー待ちのボトルネックを削減しながら、人間のレビュアーが本当に価値を発揮できる部分に集中できる環境が整います。まずはSecurity Reviewerの単体導入から始めて、チームのフィードバックを反映しながら段階的に拡張していくアプローチが現実的です。
Subagentsの詳細はClaude Code Subagents完全ガイド、Skillsの設計パターンはClaude Code Skills実践設計ガイドも参考にしてください。

