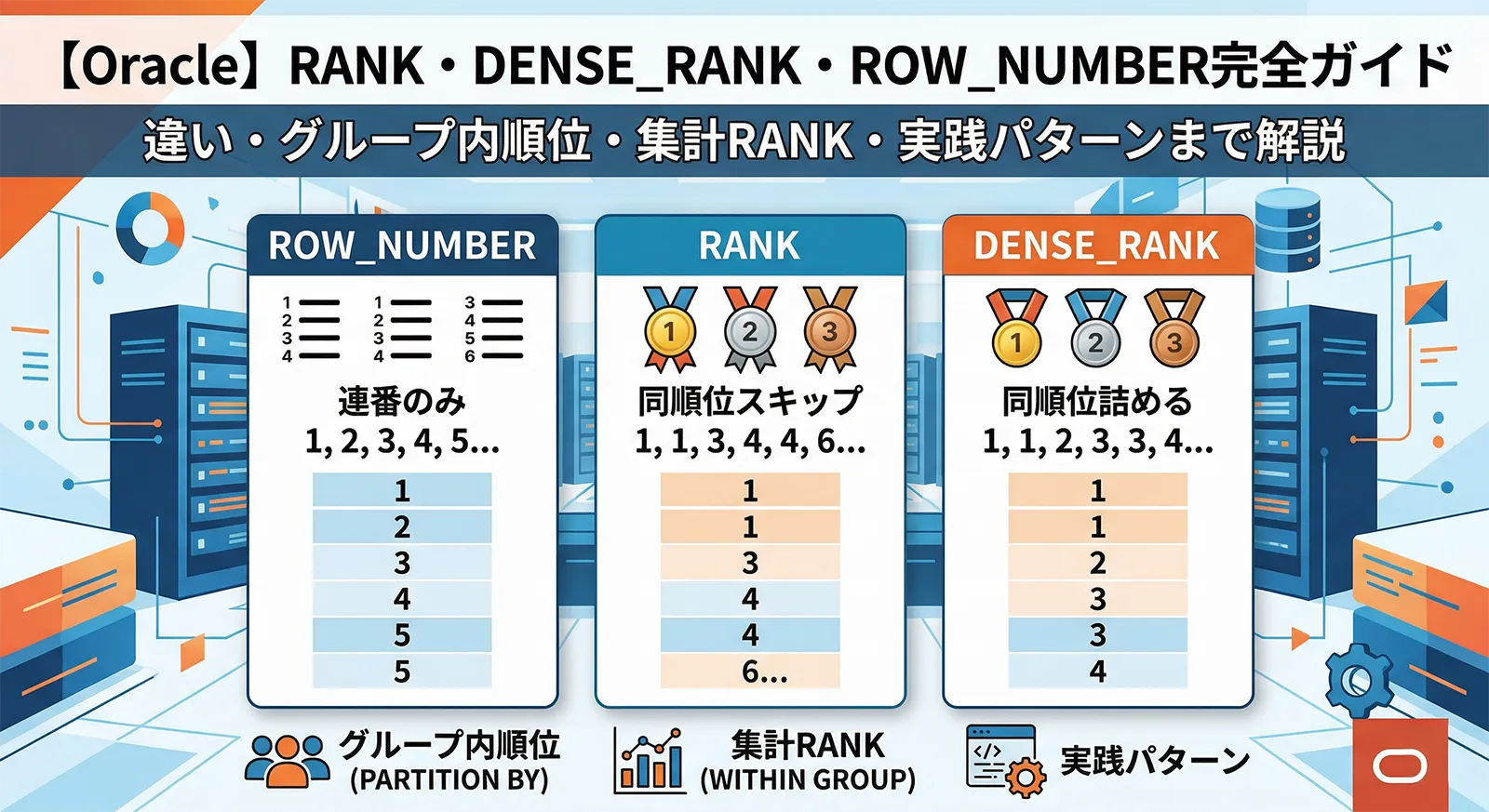
「RANK と DENSE_RANK はどう違うのか」「同点の場合に連番を振りたい」「部署ごとに給与ランキングを出したい」――こうした要求は、Oracle の順位付け関数を正確に理解すれば、サブクエリなしで1つの SELECT 文で解決できます。
Oracle には RANK()・DENSE_RANK()・ROW_NUMBER() に加え、「もしこの値が存在したら何位になるか」を計算する集計 RANK(RANK(v) WITHIN GROUP)や、「売上 1 位の商品名を同じ行に表示したい」を実現するFIRST/LAST KEEP DENSE_RANK など、他の RDBMS にはない強力な構文があります。
この記事では、各関数の同値時の動作の違いをサンプルデータで視覚的に比較し、グループ内ランキング・複数列ランキング・集計 RANK・CUME_DIST/PERCENT_RANK・NULL の扱い、そしてグループ内 Top N 取得・ページネーション・重複排除などの実践パターンまで体系的に解説します。
・RANK / DENSE_RANK / ROW_NUMBER / NTILE の違いと使い分け基準
・同値(タイ)があるとき各関数がどの数値を返すか
・PARTITION BY でグループ内順位を付ける方法
・複数列を使ったランキング(複合 ORDER BY)
・集計 RANK:RANK(val) WITHIN GROUP で仮の順位を求める方法
・FIRST / LAST KEEP DENSE_RANK で最高点の行の別列を取得する方法
・CUME_DIST / PERCENT_RANK で累積分布・相対順位を求める方法
・NULLS FIRST / NULLS LAST で NULL の順位を制御する方法
・グループ内 Top N 取得・重複排除・ページネーションの実践パターン
RANK / DENSE_RANK / ROW_NUMBER / NTILE の違い
4 つの順位付け関数は「同値(タイ)のときにどの数値を返すか」が主な違いです。次のサンプルデータで確認します。
SELECT
emp_name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rnk,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rnk,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num,
NTILE(3) OVER (ORDER BY salary DESC) AS ntile3
FROM (
SELECT 'Alice' AS emp_name, 8000 AS salary FROM dual UNION ALL
SELECT 'Bob', 6000 FROM dual UNION ALL
SELECT 'Carol', 6000 FROM dual UNION ALL
SELECT 'Dave', 4500 FROM dual UNION ALL
SELECT 'Eve', 4500 FROM dual UNION ALL
SELECT 'Frank', 3000 FROM dual
);
実行結果(イメージ):
| emp_name | salary | RANK | DENSE_RANK | ROW_NUMBER | NTILE(3) |
|---|---|---|---|---|---|
| Alice | 8000 | 1 | 1 | 1 | 1 |
| Bob | 6000 | 2 | 2 | 2 | 1 |
| Carol | 6000 | 2 | 2 | 3 | 2 |
| Dave | 4500 | 4 | 3 | 4 | 2 |
| Eve | 4500 | 4 | 3 | 5 | 3 |
| Frank | 3000 | 6 | 4 | 6 | 3 |
| 関数 | 同値の扱い | 飛び番 | 特徴・使いどころ |
|---|---|---|---|
| RANK() | 同値には同じ順位を付ける | あり(2位が2人なら次は4位) | 競技ランキング・売上ランキングなど、自然な番付が欲しい場合 |
| DENSE_RANK() | 同値には同じ順位を付ける | なし(2位が2人でも次は3位) | 順位に空きを作りたくない場合・カテゴリ分類の基準に使う場合 |
| ROW_NUMBER() | 同値でも必ず異なる連番を付ける | なし | 重複排除・ページネーション・ランダムな 1 行取得 |
| NTILE(N) | 全行を N 等分してグループ番号を付ける | なし | 上位 25% / 下位 25% などのパーセンタイル分類 |
・「同率 2 位」を表現したい →
RANK()・「同率 2 位が 2 人でも次は 3 位」にしたい →
DENSE_RANK()・「必ず 1 行だけ取りたい」「ページネーション」 →
ROW_NUMBER()・「上位 N% に分類したい」 →
NTILE(N)基本構文と OVER 句の構成
-- 基本: 全体の給与ランキング(降順)
SELECT
department_id,
employee_id,
last_name,
salary,
RANK() OVER (ORDER BY salary DESC) AS salary_rank,
DENSE_RANK() OVER (ORDER BY salary DESC) AS salary_dense_rank
FROM employees
ORDER BY salary DESC;
-- 部署ごとに給与の順位を付ける(PARTITION BY)
SELECT
department_id,
employee_id,
last_name,
salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dept_rank,
DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dept_dense_rank
FROM employees
ORDER BY department_id, salary DESC;
PARTITION BY department_id を指定すると、全体ではなく「各 department_id ごと」に順位がリセットされます。GROUP BY とは異なり、行は集約されず元のままで、順位の列が追加されるだけです。複数列を使ったランキング(複合 ORDER BY)
ORDER BY に複数の列を指定すると、複合条件でのランキングが実現できます。
-- 給与降順・入社日昇順(同じ給与なら早く入社した人を上位に)
SELECT
employee_id,
last_name,
hire_date,
salary,
RANK() OVER (
ORDER BY salary DESC, hire_date ASC
) AS salary_seniority_rank
FROM employees
ORDER BY salary DESC, hire_date ASC;
-- 部署内で「業績スコア高・欠勤少」の複合評価ランキング
SELECT
department_id,
employee_id,
performance_score,
absent_days,
DENSE_RANK() OVER (
PARTITION BY department_id
ORDER BY performance_score DESC, absent_days ASC
) AS eval_rank
FROM employee_eval
ORDER BY department_id, eval_rank;
昇順ランキングと下位ランキング
-- 欠勤日数が少ない順にランク付け(昇順 = 少ない方が1位)
SELECT
employee_id,
last_name,
absent_days,
RANK() OVER (ORDER BY absent_days ASC) AS absent_rank,
DENSE_RANK() OVER (ORDER BY salary DESC) AS salary_rank,
-- 下位ランキング(給与が低い方が1位)
RANK() OVER (ORDER BY salary ASC) AS low_salary_rank
FROM employees
ORDER BY absent_days;
集計 RANK(Aggregate RANK):仮の順位を求める
分析関数(ウィンドウ関数)としての RANK() OVER(...) とは別に、集計関数としての RANK(val) WITHIN GROUP (ORDER BY col) があります。これは「もし val という値がこの集合に存在したら何位になるか」を計算するもので、假想的な順位の計算に使います。
-- 給与 5000 は全社員の中で何位になるか?
SELECT RANK(5000) WITHIN GROUP (ORDER BY salary DESC) AS hypothetical_rank
FROM employees;
-- 5000 はその給与を下回る人数 + 1 位が返る(RANK の定義と同じ)
-- 結果: 5000以上の給与の人数 + 1
-- DENSE_RANK 版(飛び番なし)
SELECT DENSE_RANK(5000) WITHIN GROUP (ORDER BY salary DESC) AS hypothetical_dense_rank
FROM employees;
-- 部署ごとに「5000という給与は何位相当か」を確認
SELECT
department_id,
RANK(5000) WITHIN GROUP (ORDER BY salary DESC) AS rank_if_5000
FROM employees
GROUP BY department_id
ORDER BY department_id;
・「このスコアは全体の何位相当か」を1行のSQLで確認したい場合
・「採用候補者の年収はこの部署の平均と比べて何位相当か」などの評価
・PERCENTILE_CONT / PERCENTILE_DISC(中央値・パーセンタイル)と組み合わせた統計分析
FIRST / LAST KEEP DENSE_RANK:最高位の行の別列を取得する
MIN(col) KEEP (DENSE_RANK FIRST ORDER BY score DESC) は、score が最大の行(同率 1 位すべて)の中からcol の最小値を返す集計関数です。GROUP BY と組み合わせて「部署内で最高評価の社員名」などを取得できます。
-- 部署ごとに「最高給与の社員名(同率は姓の昇順で1人)」を取得
SELECT
department_id,
MAX(salary) AS max_salary,
MIN(last_name) KEEP (DENSE_RANK FIRST ORDER BY salary DESC)
AS top_earner_name,
COUNT(*) KEEP (DENSE_RANK FIRST ORDER BY salary DESC) AS tie_count
FROM employees
GROUP BY department_id
ORDER BY department_id;
-- 部署ごとに最低給与の社員名と入社日(LAST ORDER BY salary DESC = 最小給与)
SELECT
department_id,
MIN(salary) AS min_salary,
MIN(last_name) KEEP (DENSE_RANK LAST ORDER BY salary DESC) AS lowest_earner,
MIN(hire_date) KEEP (DENSE_RANK LAST ORDER BY salary DESC) AS hire_date_of_lowest
FROM employees
GROUP BY department_id
ORDER BY department_id;
ウィンドウ関数(
OVER 句)と混同しないでください。この構文は GROUP BY と組み合わせて使う集計関数です。MIN(...) KEEP (DENSE_RANK FIRST ORDER BY ...) の形で、MIN / MAX / SUM / AVG / COUNT のいずれかと組み合わせます。CUME_DIST / PERCENT_RANK:累積分布・相対順位を求める
| 関数 | 返す値の範囲 | 計算式 | 使いどころ |
|---|---|---|---|
| CUME_DIST() | 0 < 値 ≤ 1 | 自分以下の行数 ÷ 総行数(自分含む) | 「全体の上位 30% を抽出」などのパーセンタイルフィルタリング |
| PERCENT_RANK() | 0 ≤ 値 < 1 | (RANK − 1)÷(総行数 − 1) | 「自分は全体の何% のところにいるか」の相対位置の把握 |
SELECT
employee_id,
last_name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rnk,
CUME_DIST() OVER (ORDER BY salary ASC) AS cume_dist_pct, -- 0.x 形式
PERCENT_RANK() OVER (ORDER BY salary ASC) AS pct_rank, -- 0.x 形式
ROUND(CUME_DIST() OVER (ORDER BY salary ASC) * 100, 1) AS cume_dist_100
FROM employees
ORDER BY salary DESC;
-- 全体の上位 30%(CUME_DIST >= 0.7)に該当する社員を抽出
SELECT employee_id, last_name, salary, cd
FROM (
SELECT employee_id, last_name, salary,
CUME_DIST() OVER (ORDER BY salary ASC) AS cd
FROM employees
)
WHERE cd >= 0.7
ORDER BY salary DESC;
NULL の扱い:NULLS FIRST / NULLS LAST
ORDER BY 句に NULLS FIRST または NULLS LAST を指定すると、NULL 値を持つ行の順位を制御できます。
-- Oracle のデフォルト: DESC では NULL が先頭(最上位)、ASC では NULL が末尾
SELECT
employee_id,
commission_pct,
-- NULL を末尾に(コミッションなし社員を最下位にする)
RANK() OVER (ORDER BY commission_pct DESC NULLS LAST) AS rank_nulls_last,
-- NULL を先頭に(コミッションなし社員を最上位にする)
RANK() OVER (ORDER BY commission_pct DESC NULLS FIRST) AS rank_nulls_first
FROM employees
ORDER BY commission_pct DESC NULLS LAST;
・
ORDER BY col ASC(昇順): NULL は末尾(最大値扱い)・
ORDER BY col DESC(降順): NULL は先頭(最大値扱い)意図せず NULL が 1 位になってしまうバグを防ぐため、NULL が含まれる列でのランキングには必ず
NULLS LAST を明示することを推奨します。実践パターン集
パターン①:グループ内 Top N の抽出
最も頻繁に使うパターンです。サブクエリ(インラインビュー)または CTE で順位を付け、外側の WHERE 句で絞り込みます。
-- 部署ごとの給与上位 3 名(同率を含む → RANK を使う)
SELECT department_id, employee_id, last_name, salary, dept_rank
FROM (
SELECT
department_id,
employee_id,
last_name,
salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dept_rank
FROM employees
)
WHERE dept_rank <= 3
ORDER BY department_id, dept_rank;
-- 同率 3 位を除外して厳密に 3 名だけにする → ROW_NUMBER を使う
SELECT department_id, employee_id, last_name, salary, row_num
FROM (
SELECT
department_id, employee_id, last_name, salary,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS row_num
FROM employees
)
WHERE row_num <= 3
ORDER BY department_id, row_num;
パターン②:重複排除(最新の 1 件だけ取得)
-- 顧客ごとに最新の注文 1 件だけを取得(ROW_NUMBER で重複排除)
SELECT customer_id, order_id, order_date, amount
FROM (
SELECT
customer_id,
order_id,
order_date,
amount,
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY order_date DESC, order_id DESC -- 同日なら order_id 降順
) AS rn
FROM orders
)
WHERE rn = 1
ORDER BY customer_id;
パターン③:ページネーション(N 件ずつ取得)
-- 給与降順で 11〜20 件目(2 ページ目)を取得
SELECT employee_id, last_name, salary, rn
FROM (
SELECT
employee_id,
last_name,
salary,
ROW_NUMBER() OVER (ORDER BY salary DESC, employee_id) AS rn
FROM employees
)
WHERE rn BETWEEN 11 AND 20
ORDER BY rn;
-- Oracle 12c 以降は FETCH FIRST / OFFSET でシンプルに書ける
SELECT employee_id, last_name, salary
FROM employees
ORDER BY salary DESC, employee_id
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
パターン④:ランク帯ラベルの付与(A/B/C 評価)
-- 部署内の給与順位で A/B/C ランクを付与
-- Oracle ではウィンドウ関数のネストが不可のため 2 段階サブクエリで記述
SELECT
department_id,
employee_id,
last_name,
salary,
dense_rnk,
max_rank,
CASE
WHEN dense_rnk <= ROUND(max_rank * 0.2) THEN 'A'
WHEN dense_rnk <= ROUND(max_rank * 0.6) THEN 'B'
ELSE 'C'
END AS salary_grade
FROM (
-- 第 2 段階: 部署内の最大 DENSE_RANK を取得
SELECT
department_id, employee_id, last_name, salary, dense_rnk,
MAX(dense_rnk) OVER (PARTITION BY department_id) AS max_rank
FROM (
-- 第 1 段階: DENSE_RANK を計算
SELECT
department_id, employee_id, last_name, salary,
DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dense_rnk
FROM employees
)
)
ORDER BY department_id, dense_rnk;
パターン⑤:前後比較(順位が上がった・下がった社員の抽出)
-- 今月と先月の売上ランキングを比較して順位が上昇した商品を抽出
WITH current_rank AS (
SELECT product_id,
RANK() OVER (ORDER BY monthly_sales DESC) AS rnk
FROM sales_monthly WHERE yyyymm = '202412'
),
prev_rank AS (
SELECT product_id,
RANK() OVER (ORDER BY monthly_sales DESC) AS rnk
FROM sales_monthly WHERE yyyymm = '202411'
)
SELECT c.product_id,
p.rnk AS prev_rank,
c.rnk AS curr_rank,
p.rnk - c.rnk AS rank_up -- プラスが順位上昇
FROM current_rank c JOIN prev_rank p ON c.product_id = p.product_id
WHERE p.rnk - c.rnk > 0
ORDER BY rank_up DESC;
パフォーマンスの注意点
| 注意点 | 詳細 | 対処法 |
|---|---|---|
| インデックスの利用 | OVER(ORDER BY salary DESC) の ORDER BY に対してインデックスが使われる場合がある | ORDER BY に使う列にインデックスを作成しておく(特に PARTITION BY + ORDER BY の組み合わせ) |
| サブクエリの二重スキャン | Top N 抽出でサブクエリにテーブルフルスキャンが走り、外側でも処理が発生する | 件数が多い場合は FETCH FIRST(12c+)の利用を検討。インデックスが効く ORDER BY にする |
| PARTITION BY の列数 | PARTITION BY に多数の列を指定するとソートコストが増加 | 必要最低限の列に絞る。複合インデックスで補助する |
| 複数の ORDER BY OVER を同一 SELECT に列挙 | 窓関数ごとに独立したソートが発生するケースがある | 同じ PARTITION BY + ORDER BY の窓関数はまとめて書く(オプティマイザが最適化しやすい) |
よくある質問
RANK()、「1 位が 2 人いても次は 2 位」が必要なケース(Top N 件をちょうど N 件に絞りたい・カテゴリ分類)はDENSE_RANK() を使います。ほとんどの Top N 抽出は DENSE_RANK() <= N でちょうど N 番目の値まで含められるためDENSE_RANK() の方が便利です。分析 RANK は OVER 句を使い、全行を保持したまま各行に順位を付与します。2 つは用途がまったく異なります。
ORDER BY col DESC NULLS LAST と指定することで NULL を末尾(最下位)に移動できます。NULL を含む列のランキングでは NULLS FIRST/LAST を明示的に指定してください。ORDER BY はランキングの基準を決めるもので、結果セットの並び順を制御するものではありません。結果セットの表示順は最外側の ORDER BY で別途指定してください。両方を省略すると表示順は不定です。FETCH FIRST N ROWS ONLY は簡潔に先頭 N 件を取得できます(ページネーションも OFFSET で可能)。ただし同率処理が必要な場合(同率で含めたい・除外したい)は RANK() や DENSE_RANK() の方が柔軟です。単純な上位 N 件取得には FETCH FIRST、同率考慮や複雑なフィルタには ROW_NUMBER/RANK を使い分けてください。まとめ
Oracle の順位付け関数の要点をまとめます。
| やりたいこと | 使う関数・構文 |
|---|---|
| 同率に同じ順位・次は飛び番にしたい | RANK() OVER (ORDER BY …) |
| 同率に同じ順位・次も連番にしたい(飛び番なし) | DENSE_RANK() OVER (ORDER BY …) |
| 同率でも必ず連番にしたい(重複排除・ページング) | ROW_NUMBER() OVER (ORDER BY …) |
| 全体を N 等分してグループ番号を付けたい | NTILE(N) OVER (ORDER BY …) |
| グループ内で順位を付けたい | RANK() OVER (PARTITION BY グループ列 ORDER BY …) |
| NULL を末尾のランクにしたい | ORDER BY col DESC NULLS LAST |
| 仮の値が何位相当かを求めたい(集計 RANK) | RANK(val) WITHIN GROUP (ORDER BY col DESC) |
| 最高位の行の別列の値を取得したい | MIN(col) KEEP (DENSE_RANK FIRST ORDER BY score DESC) |
| 累積分布・相対順位を求めたい | CUME_DIST() / PERCENT_RANK() OVER (ORDER BY …) |
| グループ内 Top N を抽出したい | DENSE_RANK() OVER (PARTITION BY … ORDER BY …) <= N |
| 最新の 1 件だけ取得したい(重複排除) | ROW_NUMBER() OVER (PARTITION BY … ORDER BY … DESC) = 1 |
LAG/LEAD(前後行の参照)・FIRST_VALUE/LAST_VALUE(ウィンドウ内の先頭末尾)・SUM/AVG の累計・移動平均など、RANK 以外の分析関数については【Oracle】分析関数(ウィンドウ関数)の使い方完全ガイドを参照してください。

