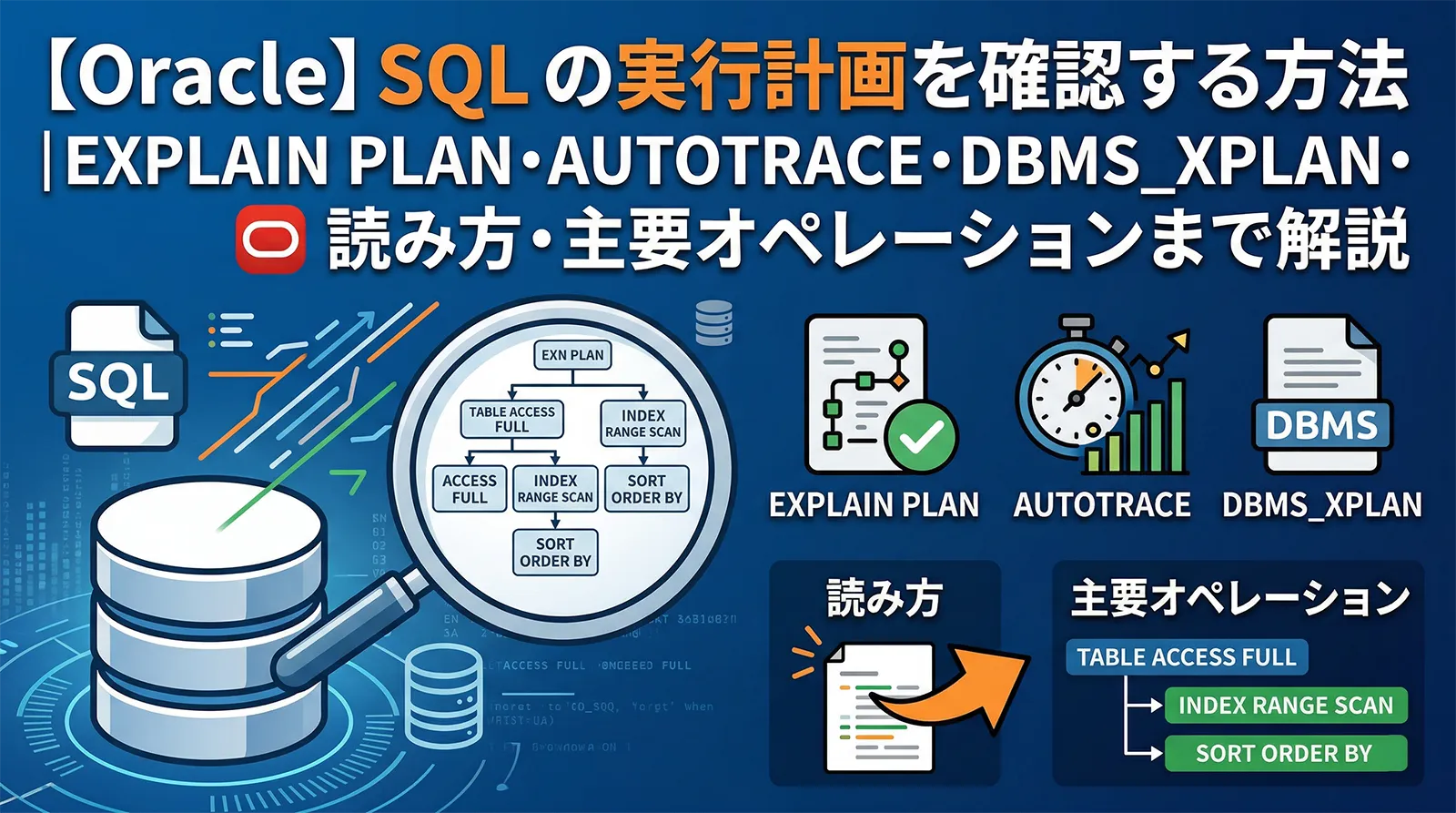
Oracle で SQL のパフォーマンスを改善するには、実行計画(Execution Plan)の確認が第一歩です。実行計画を見れば、テーブルへのアクセス方法、結合のアルゴリズム、インデックスの利用状況が一目でわかります。
本記事では、実行計画を確認する4 つの方法と、実行計画の読み方、主要オペレーションの意味、改善が必要な計画の見分け方まで解説します。
この記事でわかること
・EXPLAIN PLAN で事前に実行計画を確認する方法
・SET AUTOTRACE で実行計画 + 統計を同時に確認する方法
・DBMS_XPLAN.DISPLAY_CURSOR で実行済み SQL の実際の計画を確認する方法
・V$SQL_PLAN で共有プール内の計画を SQL で取得する方法
・実行計画の読み方(オペレーション / コスト / Rows / Bytes)
・主要オペレーションの意味と改善ポイント
・EXPLAIN PLAN で事前に実行計画を確認する方法
・SET AUTOTRACE で実行計画 + 統計を同時に確認する方法
・DBMS_XPLAN.DISPLAY_CURSOR で実行済み SQL の実際の計画を確認する方法
・V$SQL_PLAN で共有プール内の計画を SQL で取得する方法
・実行計画の読み方(オペレーション / コスト / Rows / Bytes)
・主要オペレーションの意味と改善ポイント
実行計画を確認する 4 つの方法
| 方法 | SQL 実行 | 実際の統計 | 用途 |
|---|---|---|---|
| EXPLAIN PLAN | しない(見積もりのみ) | なし | SQL を実行せずに計画だけ確認したい場合 |
| SET AUTOTRACE | する(結果も表示) | あり(統計情報付き) | SQL*Plus で手軽に確認 |
| DBMS_XPLAN.DISPLAY_CURSOR | 実行済みの実際の計画 | あり(A-Rows 等) | 最も推奨。実行済み SQL の正確な計画 |
| V$SQL_PLAN | 共有プール内の計画 | なし | sql_id から SQL で計画を取得 |
DBMS_XPLAN.DISPLAY_CURSOR が最も推奨
EXPLAIN PLAN は「見積もり」であり、実際の実行計画と異なることがあります(バインド変数の値やデータ分布による差異)。DBMS_XPLAN.DISPLAY_CURSOR は実際に実行された計画を表示するため、最も正確です。
EXPLAIN PLAN は「見積もり」であり、実際の実行計画と異なることがあります(バインド変数の値やデータ分布による差異)。DBMS_XPLAN.DISPLAY_CURSOR は実際に実行された計画を表示するため、最も正確です。
EXPLAIN PLAN で事前に確認する
SQL(EXPLAIN PLAN 基本)
-- (1) EXPLAIN PLAN を生成 EXPLAIN PLAN FOR SELECT e.employee_id, e.last_name, d.department_name FROM employees e JOIN departments d ON e.department_id = d.department_id WHERE e.salary > 5000; -- (2) 結果を表示 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
出力例
| Id | Operation | Name | Rows | Bytes | Cost | |----|------------------------------|---------------|------|-------|------| | 0 | SELECT STATEMENT | | 30 | 1200 | 5 | | 1 | NESTED LOOPS | | 30 | 1200 | 5 | | 2 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 30 | 900 | 3 | |* 3 | INDEX RANGE SCAN | IDX_EMP_SAL | 30 | | 1 | | 4 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 | 10 | 1 | |* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 |
EXPLAIN PLAN は「見積もり」
EXPLAIN PLAN は SQL を実行せずにオプティマイザの見積もりを表示します。バインド変数の値が不明なため、実際の実行計画と異なる場合があります。正確な計画を見たい場合は DBMS_XPLAN.DISPLAY_CURSOR を使ってください。
EXPLAIN PLAN は SQL を実行せずにオプティマイザの見積もりを表示します。バインド変数の値が不明なため、実際の実行計画と異なる場合があります。正確な計画を見たい場合は DBMS_XPLAN.DISPLAY_CURSOR を使ってください。
SET AUTOTRACE で計画 + 統計を確認する
SQL(AUTOTRACE の使い方)
-- SQL*Plus で有効化 SET AUTOTRACE ON -- 結果 + 実行計画 + 統計 SET AUTOTRACE ON EXPLAIN -- 結果 + 実行計画のみ SET AUTOTRACE ON STATISTICS -- 結果 + 統計のみ SET AUTOTRACE TRACEONLY -- 実行計画 + 統計(結果は非表示) -- SQL を実行すると自動的に計画が表示される SELECT * FROM employees WHERE salary > 5000; -- 終了 SET AUTOTRACE OFF
| オプション | 結果表示 | 実行計画 | 統計 |
|---|---|---|---|
| SET AUTOTRACE ON | あり | あり | あり |
| SET AUTOTRACE ON EXPLAIN | あり | あり | なし |
| SET AUTOTRACE ON STATISTICS | あり | なし | あり |
| SET AUTOTRACE TRACEONLY | なし | あり | あり |
| SET AUTOTRACE TRACEONLY EXPLAIN | なし(SQL 未実行) | あり | なし |
TRACEONLY EXPLAIN は SQL を実行しない
TRACEONLY EXPLAIN は EXPLAIN PLAN と同等で SQL を実行しません。大量データを返す SQL の計画だけ確認したい場合に便利です。
TRACEONLY EXPLAIN は EXPLAIN PLAN と同等で SQL を実行しません。大量データを返す SQL の計画だけ確認したい場合に便利です。
DBMS_XPLAN.DISPLAY_CURSOR で実行済みの計画を確認する(最も推奨)
SQL(直前に実行した SQL の計画)
-- SQL を実行 SELECT * FROM employees WHERE salary > 5000; -- 直前の SQL の実行計画を表示 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST'));
SQL(sql_id を指定して特定 SQL の計画を表示)
-- sql_id を指定(V$SQL で事前に確認)
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('abc123def456', NULL, 'ALLSTATS LAST'));
SQL(GATHER_PLAN_STATISTICS で実際の行数を取得)
-- ヒントで実際の行数を収集 SELECT /*+ GATHER_PLAN_STATISTICS */ * FROM employees WHERE salary > 5000; -- 実際の行数(A-Rows)と見積もり(E-Rows)を比較 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); -- 出力に A-Rows(実際の行数)が追加される -- E-Rows と A-Rows に大きな乖離がある = 統計情報が不正確
E-Rows と A-Rows の乖離はチューニングの最大のヒント
E-Rows(見積もり行数)と A-Rows(実際の行数)が大きく異なる場合、オプティマイザが不正確な統計情報に基づいて計画を選んでいます。
E-Rows(見積もり行数)と A-Rows(実際の行数)が大きく異なる場合、オプティマイザが不正確な統計情報に基づいて計画を選んでいます。
DBMS_STATS.GATHER_TABLE_STATS で統計情報を更新すると改善されることが多いです。V$SQL_PLAN で共有プール内の計画を SQL で取得する
SQL(V$SQL_PLAN)
-- sql_id を指定して実行計画を取得
SELECT id, operation, options, object_name,
cost, cardinality AS est_rows, bytes
FROM v$sql_plan
WHERE sql_id = 'abc123def456'
AND child_number = 0
ORDER BY id;
-- DBMS_XPLAN.DISPLAY_AWR で過去の計画を取得(AWR)
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_AWR('abc123def456'));
実行計画の読み方
主要な列の意味
| 列 | 意味 | 見るポイント |
|---|---|---|
| Id | ステップの番号 | インデントが深いほど先に実行される |
| Operation | 実行されるオペレーション | TABLE ACCESS FULL / INDEX SCAN 等 |
| Name | 対象のオブジェクト名 | テーブル名 / インデックス名 |
| Rows(E-Rows) | オプティマイザの見積もり行数 | A-Rows と大きく異なれば統計情報を更新 |
| Bytes | 見積もりデータ量 | 大きい値のステップがボトルネック候補 |
| Cost | オプティマイザが算出した相対コスト | 数値が大きいステップが負荷の中心 |
| A-Rows | 実際に処理された行数 | GATHER_PLAN_STATISTICS 使用時に表示 |
| Predicate Information | WHERE 条件の適用箇所 | access(インデックス利用)/ filter(フィルタ) |
読み方のルール
実行計画の読み方
-- 実行計画は「最もインデントが深い行」から読む -- 同じインデントレベルでは上から順に実行 -- 例: -- | 0 | SELECT STATEMENT | | -- 最後に実行 -- | 1 | NESTED LOOPS | | -- 3 番目 -- | 2 | TABLE ACCESS FULL | EMPLOYEES | -- 1 番目(最深) -- | 3 | INDEX UNIQUE SCAN | PK_DEPT | -- 2 番目
主要オペレーションの意味と改善ポイント
| オペレーション | 意味 | 改善ポイント |
|---|---|---|
| TABLE ACCESS FULL | テーブル全件スキャン | WHERE 条件の列にインデックスを作成。ただし小テーブルでは正常 |
| TABLE ACCESS BY INDEX ROWID | インデックス経由でテーブルにアクセス | 正常(インデックスが使われている) |
| INDEX RANGE SCAN | インデックスの範囲検索 | 正常。WHERE の範囲条件に一致 |
| INDEX UNIQUE SCAN | インデックスの一意検索(PK / UNIQUE) | 最も効率的 |
| INDEX FULL SCAN | インデックス全件スキャン | ORDER BY でインデックス順を利用する場合は正常 |
| INDEX FAST FULL SCAN | インデックスをテーブル代わりにフルスキャン | SELECT にインデックス列しかない場合は正常 |
| NESTED LOOPS | 入れ子ループ結合 | 内側テーブルにインデックスがあれば高速。大テーブル同士では遅い場合あり |
| HASH JOIN | ハッシュ結合 | 大テーブル同士の等値結合で効率的。PGA メモリを消費 |
| SORT MERGE JOIN | ソートマージ結合 | 両テーブルがソート済みの場合に効率的 |
| SORT ORDER BY | ORDER BY のためのソート | インデックスで ORDER BY を代替できる場合は不要 |
| SORT GROUP BY | GROUP BY のためのソート | HASH GROUP BY の方が効率的な場合あり |
| HASH GROUP BY | ハッシュを使った GROUP BY | 通常は SORT GROUP BY より高速 |
| FILTER | 行のフィルタリング | サブクエリのフィルタ。NOT EXISTS 等で出現 |
| COUNT STOPKEY | ROWNUM による件数制限 | 高速な打ち切り最適化 |
| WINDOW SORT PUSHED RANK | FETCH FIRST / ROW_NUMBER の最適化 | 上位 N 件の効率取得 |
TABLE ACCESS FULL が必ずしも悪いわけではない
小テーブル(数百行以下)ではフルスキャンの方がインデックス経由より速いことがあります。また、テーブルの大部分を取得する SELECT でもフルスキャンが最適です。「大テーブル + 少数行の取得」でフルスキャンが出ている場合にインデックスを検討してください。
小テーブル(数百行以下)ではフルスキャンの方がインデックス経由より速いことがあります。また、テーブルの大部分を取得する SELECT でもフルスキャンが最適です。「大テーブル + 少数行の取得」でフルスキャンが出ている場合にインデックスを検討してください。
改善が必要な実行計画のパターン
| パターン | 症状 | 改善策 |
|---|---|---|
| 大テーブルの TABLE ACCESS FULL | Cost / Rows が非常に大きい | WHERE 条件の列にインデックスを作成 |
| E-Rows と A-Rows の乖離 | 見積もり 10 行、実際 100,000 行 | DBMS_STATS.GATHER_TABLE_STATS で統計更新 |
| 大テーブル同士の NESTED LOOPS | Cost が極めて高い | HASH JOIN への変更を検討(USE_HASH ヒント) |
| 不要な SORT ORDER BY | ORDER BY のソートが負荷に | インデックスで ORDER BY を代替 |
| FILTER + サブクエリが N 回実行 | Starts が大量 | EXISTS をJOIN に書き換え、またはスカラーサブクエリをキャッシュ |
統計情報の更新
SQL(統計情報の更新)
-- テーブルの統計情報を更新
EXEC DBMS_STATS.GATHER_TABLE_STATS('HR', 'EMPLOYEES');
-- スキーマ全体の統計を更新
EXEC DBMS_STATS.GATHER_SCHEMA_STATS('HR');
-- 統計情報の最終更新日を確認
SELECT table_name, last_analyzed, num_rows
FROM all_tables
WHERE owner = 'HR'
ORDER BY last_analyzed;
統計情報が古いと実行計画が不正確になる
大量の INSERT / DELETE の後は統計情報が実態と乖離します。定期的に DBMS_STATS で統計を更新し、E-Rows と A-Rows の乖離を防いでください。Oracle はデフォルトで夜間に自動統計収集を行いますが、大量データ変更後は手動更新が推奨です。
大量の INSERT / DELETE の後は統計情報が実態と乖離します。定期的に DBMS_STATS で統計を更新し、E-Rows と A-Rows の乖離を防いでください。Oracle はデフォルトで夜間に自動統計収集を行いますが、大量データ変更後は手動更新が推奨です。
実務パターン集
パターン(1): 遅い SQL の実行計画を確認する手順
SQL
-- (1) 遅い SQL の sql_id を V$SQL で特定
SELECT sql_id, elapsed_time/1000000 AS sec, executions,
SUBSTR(sql_text, 1, 80) AS sql_text
FROM v$sql ORDER BY elapsed_time DESC FETCH FIRST 5 ROWS ONLY;
-- (2) 実行計画を表示
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('abc123', NULL, 'ALLSTATS LAST'));
-- (3) TABLE ACCESS FULL や E-Rows/A-Rows 乖離を確認
-- (4) 必要に応じてインデックス作成 / 統計更新
パターン(2): インデックスが使われているか確認
SQL
-- GATHER_PLAN_STATISTICS で実際の計画を確認 SELECT /*+ GATHER_PLAN_STATISTICS */ * FROM orders WHERE customer_id = 100; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, 'ALLSTATS LAST')); -- INDEX RANGE SCAN が出ていればインデックスが使われている -- TABLE ACCESS FULL が出ていればインデックスが使われていない
パターン(3): 過去の実行計画を確認(AWR)
SQL
-- AWR に記録された過去の実行計画(EE + Diagnostics Pack)
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_AWR('abc123def456'));
よくある質問
QEXPLAIN PLAN と DBMS_XPLAN.DISPLAY_CURSOR の違いは?
AEXPLAIN PLAN は SQL を実行せずに「見積もり」の計画を表示します。バインド変数の値が不明なため、実際と異なる計画が出ることがあります。DBMS_XPLAN.DISPLAY_CURSOR は実行済み SQL の「実際の計画」を表示するため、より正確です。
Q実行計画はどこから読めばいいですか?
A最もインデントが深い行から読みます。同じインデントレベルでは上から順に実行されます。最終的に Id=0 の SELECT STATEMENT に結果が返ります。
QCost の数値が大きい = 遅いのですか?
ACost はオプティマイザの「相対的な見積もり」であり、絶対的な実行時間ではありません。同じ SQL の異なる計画を比較する場合には有用ですが、異なる SQL 間で Cost を比較しても意味がありません。
QTABLE ACCESS FULL が出たらインデックスを作るべきですか?
A必ずしもそうではありません。小テーブルや取得行数がテーブルの大部分の場合、フルスキャンの方が効率的です。「大テーブル + 少数行の取得」でフルスキャンが出ている場合にインデックスを検討してください。
QGATHER_PLAN_STATISTICS ヒントの影響は?
A実行時にステップごとの実際の行数(A-Rows)を収集するため、わずかなオーバーヘッドがあります。本番環境では調査対象の SQL にだけ付けてください。全 SQL に常時付けるものではありません。
QSET AUTOTRACE は SQL Developer でも使えますか?
ASQL Developer には独自の「実行計画」機能があり、F10 キーで EXPLAIN PLAN、F6 キーで実行 + 計画を確認できます。SET AUTOTRACE は SQL*Plus / SQLcl 専用のコマンドです。
まとめ
実行計画の確認方法をまとめます。
| やりたいこと | 方法 |
|---|---|
| SQL を実行せずに計画を確認 | EXPLAIN PLAN FOR …; SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY); |
| SQL*Plus で計画 + 統計を確認 | SET AUTOTRACE ON |
| 実行済み SQL の実際の計画(最も推奨) | SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(NULL, NULL, ‘ALLSTATS LAST’)) |
| sql_id から特定 SQL の計画 | DBMS_XPLAN.DISPLAY_CURSOR(‘sql_id’) |
| 実際の行数を収集 | /*+ GATHER_PLAN_STATISTICS */ ヒントを付けて実行 |
| 過去の計画(AWR) | DBMS_XPLAN.DISPLAY_AWR(‘sql_id’) |
| 統計情報の更新 | DBMS_STATS.GATHER_TABLE_STATS(‘owner’, ‘table’) |
遅い SQL の特定方法は「遅い SQL を特定する方法」も併せて参照してください。