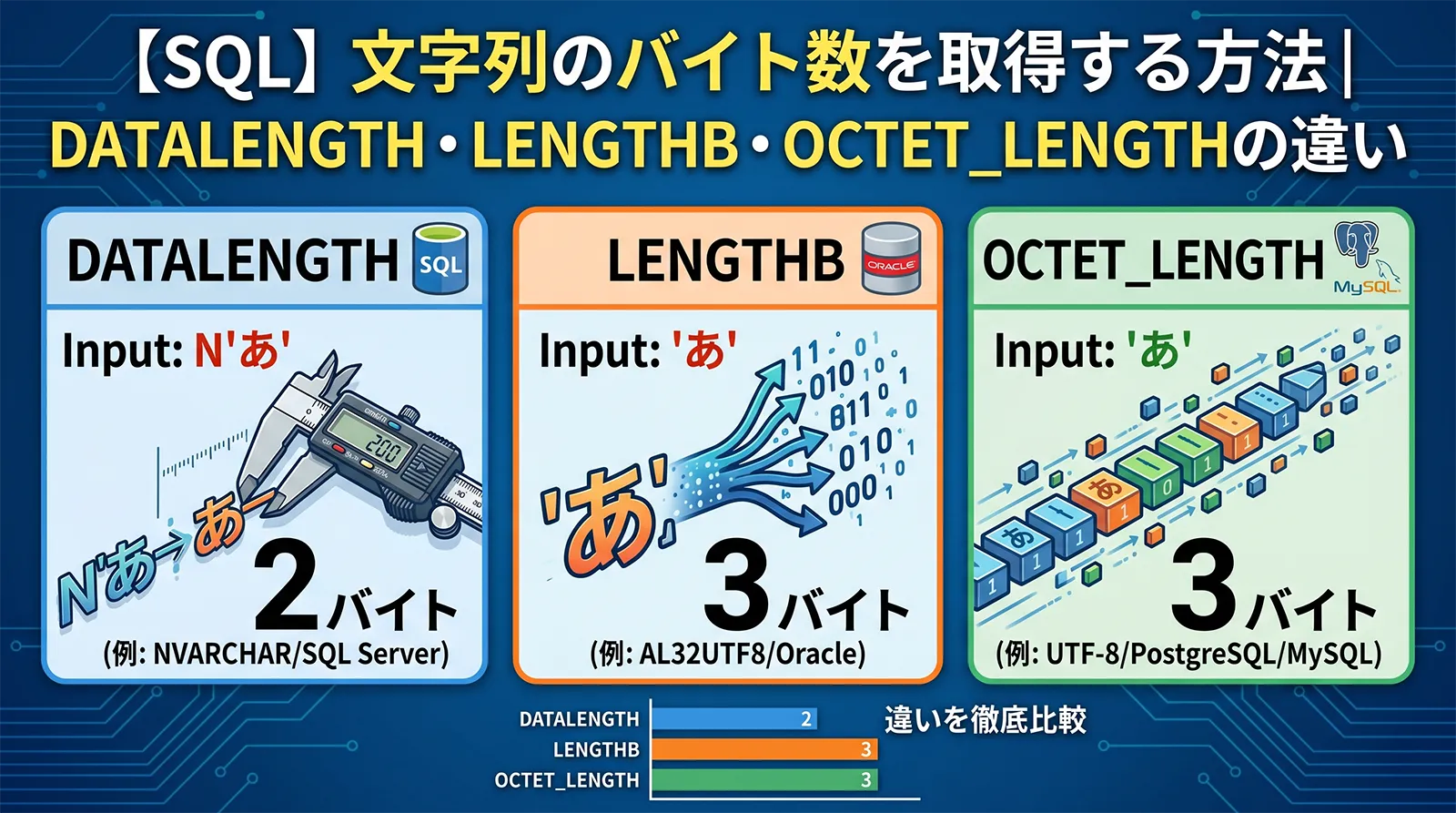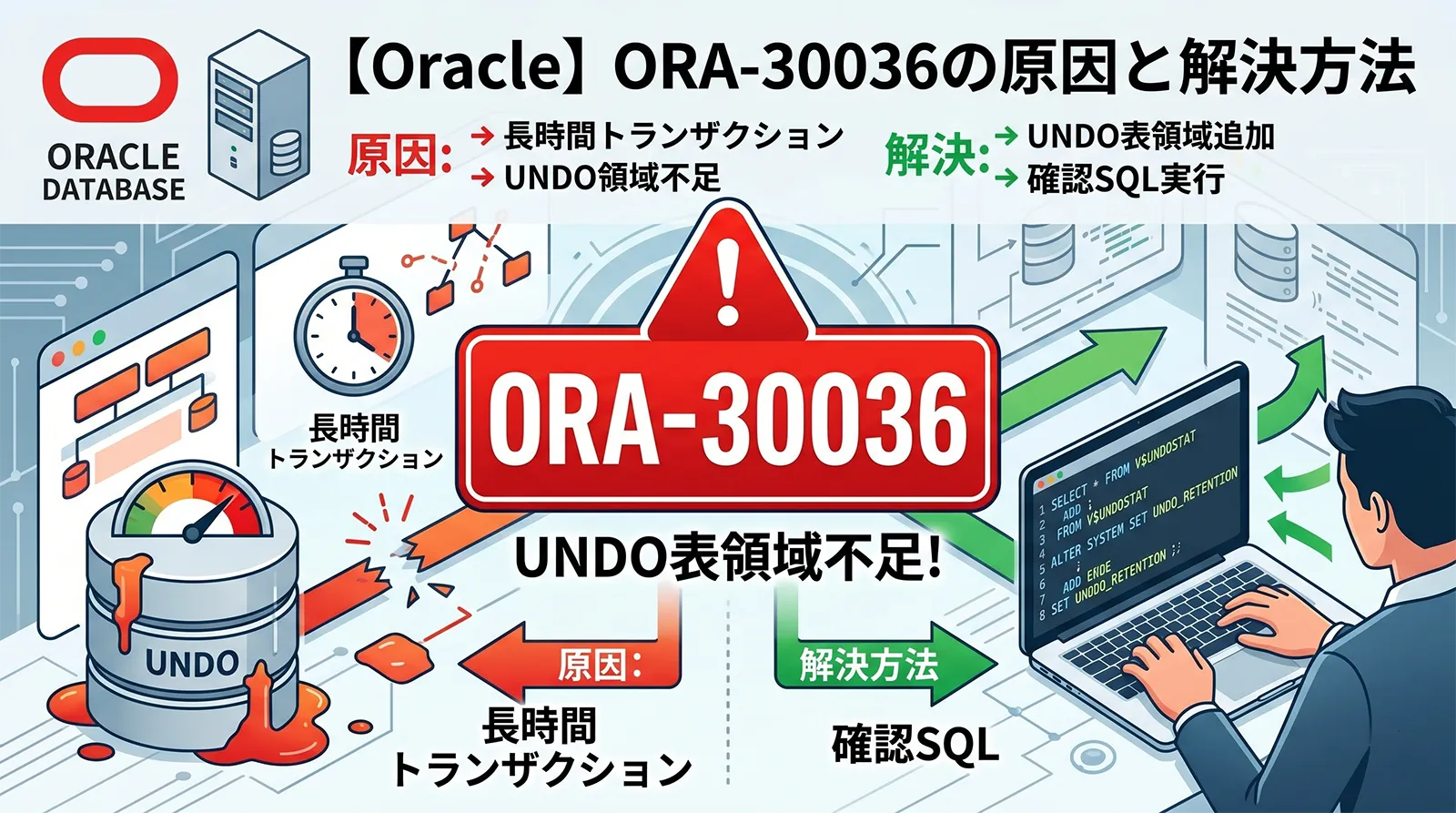
ORA-30036: unable to extend segment by ... in undo tablespace ... は、OracleがUNDO表領域内のUNDOセグメントを拡張できないときに発生するエラーです。INSERT、UPDATE、DELETE、MERGE、Data Pump、バッチ更新、長時間トランザクションなどでUNDOを大量に使うと、処理が途中で止まります。
Oracle公式のエラーメッセージでも、原因は「指定されたUNDO表領域に空きがないこと」、対処は「UNDO表領域に領域を追加する、またはアクティブなトランザクションのCOMMITを待つこと」とされています。ただし、本番では単純にデータファイルを足すだけでは再発します。どの処理がUNDOを消費しているか、AUTOEXTENDの上限に達していないか、UNDO_RETENTION や RETENTION GUARANTEE が効いていないかまで確認します。
表領域全体の考え方は Oracle表領域完全ガイド、容量不足の緊急対応は Oracle容量不足の緊急対応完全ガイド、UNDOと大量DMLの設計は 大量データ処理のコミット頻度とUNDO最適化 もあわせて確認してください。
- ORA-30036が発生する仕組み
- まず止血するためのUNDO表領域追加・AUTOEXTEND設定
- UNDO使用状況、ACTIVE/UNEXPIRED/EXPIREDの確認SQL
- 長時間トランザクションと大量DMLの見つけ方
- UNDO_RETENTIONとRETENTION GUARANTEEの注意点
- ORA-01555やORA-01652との違い
- 再発防止の監視SQLと設計チェック
- 最初に結論:止血は領域追加、再発防止は原因特定
- 原因別の判断フロー
- ORA-30036の意味
- まず確認するエラーメッセージ
- 止血:UNDO表領域に領域を追加する
- UNDO表領域の現在サイズを確認する
- UNDOのACTIVE/UNEXPIRED/EXPIREDを確認する
- UNDOを多く使っているトランザクションを探す
- UNDOの発生傾向をV$UNDOSTATで見る
- 原因1:UNDO表領域が単純に小さい
- 原因2:長時間トランザクションがUNDOを握っている
- 原因3:大量DMLのCOMMIT粒度が大きすぎる
- 原因4:UNDO_RETENTIONが高すぎる・RETENTION GUARANTEEが有効
- 原因5:Data Pumpや一括更新が集中している
- ORA-01555との違い
- 再発防止の監視SQL
- 本番対応フロー
- やってはいけない対応
- まとめ
最初に結論:止血は領域追加、再発防止は原因特定
ORA-30036が本番で出ている最中は、まず処理を再開できる状態にする必要があります。最短の止血はUNDO表領域へのデータファイル追加、既存データファイルの拡張、AUTOEXTEND上限の見直しです。一方で、根本原因は長時間トランザクション、大量DML、COMMIT粒度、UNDO保持期間、領域設計のいずれかにあります。
DBA_UNDO_EXTENTS、V$UNDOSTAT、V$TRANSACTION、V$SESSION を確認します。ORA-01652、古いUNDOが消えた ORA-01555、通常表領域不足とは対処が違います。TEMP表領域不足は ORA-01652の原因と解決方法、スナップショットが古すぎるエラーは ORA-01555完全ガイド が近いテーマです。
原因別の判断フロー
ORA-30036が出たときは、いきなりパラメータを変えるより、どの種類の不足かを短時間で分けます。判断の軸は、データファイル上限、ACTIVEなUNDO、UNEXPIREDなUNDO、発生時間帯の4つです。
autoextensible がNO、または bytes が maxbytes に近い場合です。領域追加やMAXSIZE見直しが第一候補です。V$TRANSACTION で対象セッションを確認します。ORA-30036の意味
UNDOは、更新前のデータを保持する領域です。OracleはROLLBACK、一貫性読み取り、Flashback QueryなどのためにUNDOを使います。DMLが増えるほどUNDOは増え、処理がCOMMITまたはROLLBACKされるまではACTIVEなUNDOとして保持されます。
ORA-30036は、UNDO表領域に新しいUNDO領域を確保できなかったことを示します。つまり、更新処理に必要なUNDOを置く場所が足りません。空き領域がない、AUTOEXTENDできない、アクティブなトランザクションが領域を握っている、保持すべきUNDOが多すぎる、といった状態で起きます。
まず確認するエラーメッセージ
エラーメッセージには、どのUNDO表領域で、どれだけ拡張しようとして失敗したかが出ます。まず表領域名を控えます。
ORA-30036: unable to extend segment by 128 in undo tablespace 'UNDOTBS1'
この例では、UNDOTBS1 というUNDO表領域で拡張に失敗しています。以降の確認SQLでは、この表領域を中心に見ます。
止血:UNDO表領域に領域を追加する
本番で処理が止まっている場合、まず空きを作ります。ディスク容量に余裕があること、バックアップや監視の運用に問題がないことを確認したうえで実行します。
既存データファイルを拡張する
ALTER DATABASE DATAFILE '/u01/oradata/ORCL/undotbs01.dbf' RESIZE 20G;
データファイルを追加する
ALTER TABLESPACE UNDOTBS1 ADD DATAFILE '/u01/oradata/ORCL/undotbs02.dbf' SIZE 10G AUTOEXTEND ON NEXT 512M MAXSIZE 50G;
AUTOEXTENDを有効化する
ALTER DATABASE DATAFILE '/u01/oradata/ORCL/undotbs01.dbf' AUTOEXTEND ON NEXT 512M MAXSIZE 50G;
AUTOEXTEND ON は便利ですが、無制限に伸ばす設計は危険です。OSやASMの領域まで使い切ると、別の障害に広がります。必ず MAXSIZE を決め、監視で上限に近づいたことを検知できるようにします。表領域の空き容量確認は 表領域の使用状況を確認するSQLまとめ も参考になります。
UNDO表領域の現在サイズを確認する
止血後、まず現在のUNDO表領域とデータファイルの状態を確認します。CDB/PDB構成では、対象PDBで確認するか、必要に応じてCDBビューを使います。
SELECT p.value AS current_undo_tablespace
FROM v$parameter p
WHERE p.name = 'undo_tablespace';
SELECT tablespace_name,
file_name,
ROUND(bytes / 1024 / 1024) AS current_mb,
autoextensible,
ROUND(maxbytes / 1024 / 1024) AS max_mb,
ROUND(increment_by * 8 / 1024) AS next_mb
FROM dba_data_files
WHERE tablespace_name = (
SELECT value
FROM v$parameter
WHERE name = 'undo_tablespace'
)
ORDER BY file_name;
bytes が現在サイズ、maxbytes がAUTOEXTEND時の上限です。autoextensible がYESでも、maxbytes に達していれば拡張できません。
現在の空きと上限をまとめて見る
SELECT df.tablespace_name,
ROUND(SUM(df.bytes) / 1024 / 1024) AS current_mb,
ROUND(SUM(df.maxbytes) / 1024 / 1024) AS max_mb,
MAX(df.autoextensible) AS autoextensible
FROM dba_data_files df
WHERE df.tablespace_name = (
SELECT value
FROM v$parameter
WHERE name = 'undo_tablespace'
)
GROUP BY df.tablespace_name;
UNDOのACTIVE/UNEXPIRED/EXPIREDを確認する
DBA_UNDO_EXTENTS を見ると、UNDO領域がどの状態で使われているかを確認できます。ORA-30036の切り分けでは、ACTIVEが多いのか、UNEXPIREDが多いのかが重要です。
SELECT tablespace_name,
status,
ROUND(SUM(bytes) / 1024 / 1024) AS mb
FROM dba_undo_extents
GROUP BY tablespace_name, status
ORDER BY tablespace_name, status;
-- 状態の見方
-- ACTIVE : 現在のトランザクションが使用中
-- UNEXPIRED : 保持期間内で、読み取り一貫性のために残している
-- EXPIRED : 必要なら再利用できる
ACTIVEが大きい場合は、実行中のDMLや未COMMITトランザクションが領域を使っています。UNEXPIREDが大きい場合は、UNDO_RETENTIONや長時間クエリ、RETENTION GUARANTEEの影響を確認します。EXPIREDが十分あるのにエラーが出る場合は、断片化やファイル上限、別の表領域を見ている可能性もあります。
UNDOを多く使っているトランザクションを探す
ORA-30036の原因が長時間トランザクションや大量DMLなら、対象セッションを特定します。すぐにKILLするのではなく、業務影響、処理内容、再実行可否を確認してから判断します。
SELECT s.sid,
s.serial#,
s.username,
s.program,
s.module,
s.sql_id,
t.start_time,
t.used_ublk,
t.used_urec,
ROUND(t.used_ublk * TO_NUMBER(p.value) / 1024 / 1024) AS undo_mb
FROM v$transaction t
JOIN v$session s
ON s.taddr = t.addr
JOIN v$parameter p
ON p.name = 'db_block_size'
ORDER BY t.used_ublk DESC;
USED_UBLK と USED_UREC が大きいセッションほどUNDOを多く消費しています。アプリケーション側で DBMS_APPLICATION_INFO のMODULE/ACTIONを設定していると、どの処理か追いやすくなります。運用観測性は PL/SQLインストゥルメンテーション設計 が関連します。
UNDOの発生傾向をV$UNDOSTATで見る
V$UNDOSTAT は、UNDO使用量、チューニングされたUNDO保持時間、ORA-01555発生数などを見るためのビューです。直近だけでなく、いつUNDO圧迫が起きやすいかを確認できます。
SELECT begin_time,
end_time,
undoblks,
txncount,
maxquerylen,
tuned_undoretention,
ssolderrcnt,
nospaceerrcnt
FROM v$undostat
ORDER BY begin_time DESC
FETCH FIRST 24 ROWS ONLY;
NOSPACEERRCNT が増えている時間帯は、UNDO不足が実際に発生しています。MAXQUERYLEN が長い場合は、長時間クエリのために古いUNDOを保持する必要があり、DML側と競合しやすくなります。
原因1:UNDO表領域が単純に小さい
データ量や更新量に対してUNDO表領域が小さい場合、解決策はサイズを増やすことです。ただし、現在サイズだけでなくピーク時の更新量、長時間クエリ、バッチ時間帯を考慮して設計します。
V$UNDOSTAT.UNDOBLKS、ORA-30036発生時間帯です。原因2:長時間トランザクションがUNDOを握っている
COMMITされていない大きなトランザクションがあると、そのUNDOはACTIVEのままです。ほかの処理がUNDOを使おうとしても再利用できず、ORA-30036につながります。
SELECT s.sid,
s.serial#,
s.username,
s.status,
s.module,
s.sql_id,
t.start_time,
t.used_ublk,
t.used_urec
FROM v$transaction t
JOIN v$session s
ON s.taddr = t.addr
ORDER BY t.start_time;
対象が不要なセッションであれば、業務影響を確認して終了を検討します。ただし、KILLするとロールバックが走り、その間もUNDOやI/Oを使います。本当に止めてよい処理かを確認してから実行します。
ALTER SYSTEM KILL SESSION '123,456' IMMEDIATE;
原因3:大量DMLのCOMMIT粒度が大きすぎる
一度に大量のDELETEやUPDATEを行い、最後に1回だけCOMMITする処理はUNDOを大きく消費します。業務的に分割できるなら、キー範囲や日付範囲でチャンク化し、適切な単位でCOMMITします。
DECLARE
l_rows PLS_INTEGER;
BEGIN
LOOP
DELETE FROM access_logs
WHERE log_date < ADD_MONTHS(TRUNC(SYSDATE), -12)
AND ROWNUM <= 10000;
l_rows := SQL%ROWCOUNT;
COMMIT;
EXIT WHEN l_rows = 0;
END LOOP;
END;
/
ただし、COMMITを細かくしすぎると、業務整合性や再実行設計が難しくなります。チャンク処理は、再開位置、失敗時の扱い、途中結果の一貫性まで決めます。大規模バッチの並列化は DBMS_PARALLEL_EXECUTEによる大規模バッチの並列化戦略 も関連します。
原因4:UNDO_RETENTIONが高すぎる・RETENTION GUARANTEEが有効
UNDO_RETENTION は、古いUNDOをどれくらい保持しようとするかの設定です。長時間クエリやFlashback用途には重要ですが、値が大きすぎるとUNDO表領域の圧迫につながります。さらに RETENTION GUARANTEE が有効なUNDO表領域では、未期限切れUNDOをより強く保持するため、DMLがORA-30036で失敗しやすくなります。
SHOW PARAMETER undo_retention;
SELECT tablespace_name,
retention
FROM dba_tablespaces
WHERE contents = 'UNDO';
SELECT begin_time,
tuned_undoretention,
maxquerylen,
nospaceerrcnt
FROM v$undostat
ORDER BY begin_time DESC
FETCH FIRST 12 ROWS ONLY;
短期的に UNDO_RETENTION を下げると領域圧迫が緩むことがありますが、ORA-01555を増やす可能性があります。本番では、単に値を下げるのではなく、長時間クエリの必要性、Flashback要件、UNDO表領域サイズをセットで見直します。
RETENTION GUARANTEEを確認・変更する
RETENTION GUARANTEE が有効なUNDO表領域では、未期限切れUNDOを守るため、DMLが領域不足で失敗しやすくなります。長時間クエリやFlashbackを守るための設定なので、解除する場合は業務要件を確認します。
SELECT tablespace_name,
retention
FROM dba_tablespaces
WHERE contents = 'UNDO';
-- 解除する場合。長時間クエリやFlashback要件を確認してから実行する
ALTER TABLESPACE UNDOTBS1 RETENTION NOGUARANTEE;
-- 保証を有効にする場合。十分なUNDO容量を確保してから使う
ALTER TABLESPACE UNDOTBS1 RETENTION GUARANTEE;
原因5:Data Pumpや一括更新が集中している
Data Pumpのインポート、移行バッチ、洗い替え、月次処理などが重なると、UNDOのピークが通常時と大きく変わります。定常監視では問題がなくても、特定の時間帯だけORA-30036が出るなら、ジョブの重なりを確認します。
Data Pump全体の使い方は Oracle Data Pump完全ガイド、ダイレクトパスインサートは ダイレクト・パス・インサート完全ガイド も参考になります。
ORA-01555との違い
ORA-30036 と ORA-01555 はどちらもUNDOに関係しますが、意味が違います。
片方だけを見て設定を変えると、もう片方が悪化することがあります。たとえばUNDO_RETENTIONを短くするとORA-30036は減る可能性がありますが、ORA-01555は増える可能性があります。
再発防止の監視SQL
ORA-30036は、発生してから対応すると業務影響が大きくなります。UNDO表領域の使用状況、ACTIVE領域、NOSPACEERRCNT、長時間トランザクションを定期的に見ます。
-- UNDO表領域の状態
SELECT tablespace_name,
status,
ROUND(SUM(bytes) / 1024 / 1024) AS mb
FROM dba_undo_extents
GROUP BY tablespace_name, status
ORDER BY tablespace_name, status;
-- 直近のUNDO不足発生回数
SELECT begin_time,
end_time,
undoblks,
txncount,
tuned_undoretention,
nospaceerrcnt,
ssolderrcnt
FROM v$undostat
ORDER BY begin_time DESC
FETCH FIRST 12 ROWS ONLY;
-- UNDOを多く使うトランザクション
SELECT s.sid,
s.serial#,
s.username,
s.module,
t.start_time,
t.used_ublk,
t.used_urec
FROM v$transaction t
JOIN v$session s
ON s.taddr = t.addr
ORDER BY t.used_ublk DESC;
監視では、使用率だけでなく NOSPACEERRCNT と長時間トランザクションを見るのがポイントです。使用率が低く見えても、特定処理の瞬間的なピークでORA-30036が出ることがあります。
本番対応フロー
- エラーメッセージからUNDO表領域名を確認する
- ディスク空き容量、ASM空き容量、データファイル上限を確認する
- 必要ならUNDO表領域にデータファイルを追加する
DBA_UNDO_EXTENTSでACTIVE/UNEXPIRED/EXPIREDの割合を見るV$TRANSACTIONでUNDOを多く使うセッションを特定するV$UNDOSTATでNOSPACEERRCNTとピーク時間帯を確認する- 長時間トランザクション、大量DML、ジョブ重複を調べる
- COMMIT粒度、チャンク化、ジョブ時間帯、UNDO表領域サイズを見直す
- UNDO_RETENTIONとRETENTION GUARANTEEの設定を確認する
- 対応後にORA-01555が増えていないかも確認する
やってはいけない対応
まとめ
ORA-30036は、UNDO表領域でUNDOセグメントを拡張できないときに発生します。本番で発生したら、まずUNDO表領域への領域追加やAUTOEXTEND設定で止血し、その後にACTIVEな長時間トランザクション、UNDO_RETENTION、RETENTION GUARANTEE、大量DML、ジョブ重複を調べます。
再発防止では、UNDO表領域のサイズを増やすだけでなく、COMMIT粒度、チャンク処理、ピーク時間帯のジョブ設計、V$UNDOSTAT の監視をセットで整えることが重要です。ORA-01555やTEMP不足とは対策が異なるため、エラーコードごとに正しく切り分けましょう。