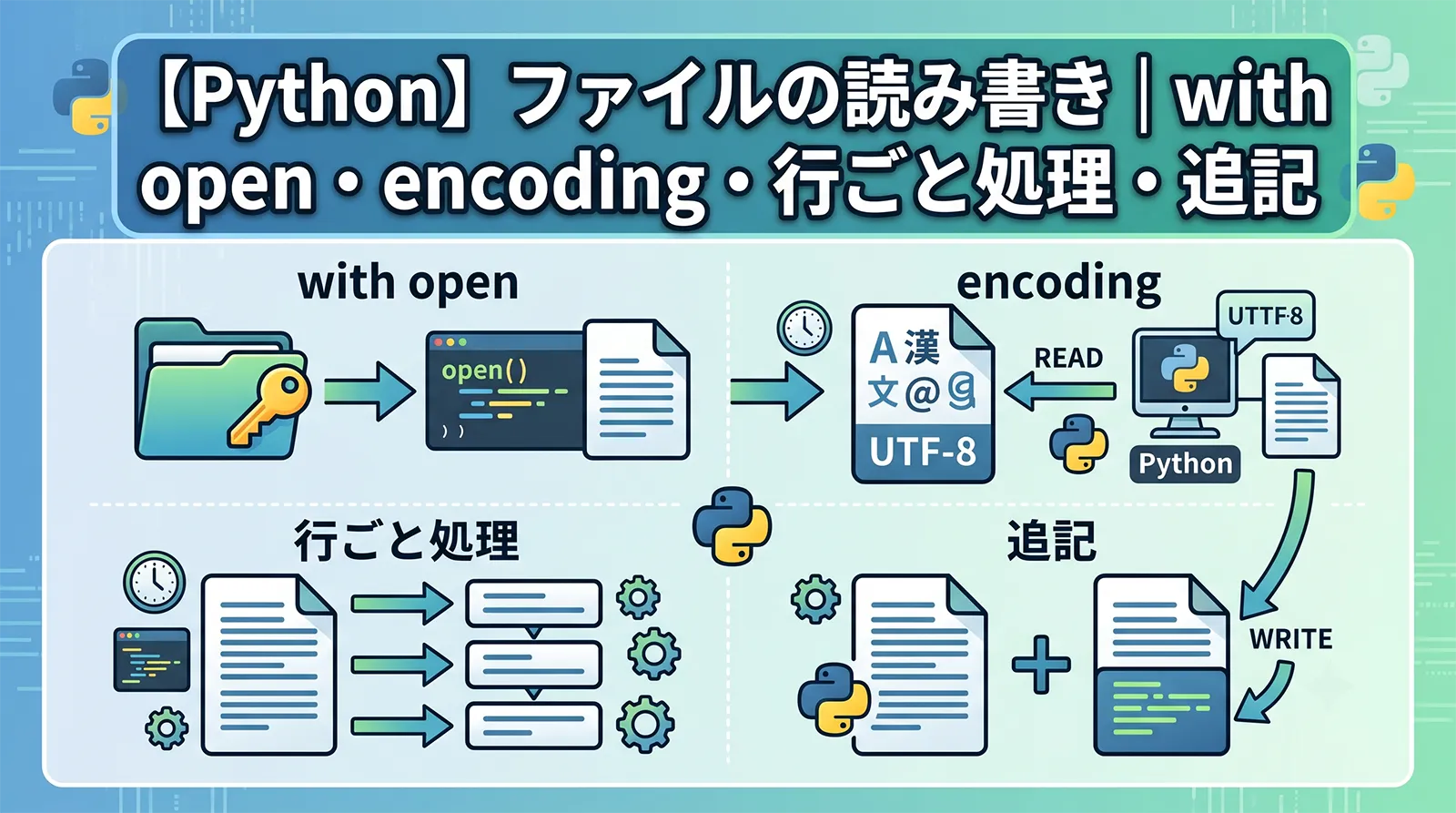
設定ファイルの読み込み、ログの書き出し、データの保存など、ファイルの読み書きはプログラムの基本です。Pythonではopen()でファイルを開き、with文と組み合わせて読み書きします。
もっとも注意したいのが文字コード(encoding)です。encoding="utf-8"を指定しないと、Windowsでは既定のcp932(Shift_JIS系)で読み書きされ、UTF-8のファイルを開いたときに文字化けやエラーになります。日本語を扱うなら、encodingの指定が欠かせません。この記事では、実機のPythonで確認しながら、ファイルの読み書きを整理します。
- 読み書きは
with open("file.txt", encoding="utf-8") as f:が基本形です。 encoding="utf-8"を必ず指定します。指定しないとWindowsでは文字化けやエラーになります。- 全体は
f.read()、行ごとはfor line in f:で処理します。 - 書き込みはモード
"w"(上書き)、追記は"a"です。"w"は既存の内容を消します。 withを使うと、ブロックを抜けるときに自動でファイルが閉じられます。- 読み込んだ行には末尾に改行
\nが付くため、.rstrip()で取り除きます。
ファイルが無いときのエラー対応は例外処理(try/except)、行をリストで扱うならリスト(list)の使い方、書き込む文字列の組み立てはf-stringと文字列フォーマットもあわせて参考になります。
ファイルを読む(with open)
ファイルを読むにはopen()でファイルを開き、read()で中身を取り出します。with文を使うと、処理が終わったときに自動でファイルが閉じられます。
# with を使うと自動で閉じられる(推奨)
with open("data.txt", encoding="utf-8") as f:
content = f.read() # ファイル全体を文字列で読む
print(content)
# 開くモードを省略すると読み込み("r")になる
# with open("data.txt", "r", encoding="utf-8") as f: と同じ
実機でも、with open(...) as f:のブロックを抜けたあと、f.closedがTrueになり、ファイルが自動で閉じられていることを確認しました。open()の第2引数(モード)を省略すると、読み込みモード"r"になります。
【最重要】encodingを指定しないと文字化けする
ここが日本語を扱うときの最大の注意点です。open()でencodingを省略すると、OSの既定の文字コードが使われます。Windowsの既定はcp932(Shift_JIS系)のため、UTF-8で保存されたファイルを開くと文字化けやエラーになります。
# NG: encoding を指定しない(Windows では cp932 で読もうとする)
# with open("utf8_file.txt") as f:
# f.read() # UnicodeDecodeError や文字化けになることがある
# OK: encoding="utf-8" を必ず指定する
with open("utf8_file.txt", encoding="utf-8") as f:
content = f.read()
# 書き込むときも同じ
with open("out.txt", "w", encoding="utf-8") as f:
f.write("日本語のテキスト")
実機で確認したところ、Windowsのopen()の既定エンコードはcp932で、UTF-8で保存した日本語ファイルをencodingなしで読むとUnicodeDecodeError: 'cp932' codec can't decode byte ...というエラーになりました。書き込み時も、encodingを指定しないとcp932で書かれてしまい、他のツール(UTF-8前提)で開くと化けます。読み書きのどちらでも、encoding="utf-8"を必ず付ける習慣にしてください。これだけで、文字化けの大半を防げます。
行ごとに読む(for / readlines)
ログのように1行ずつ処理したいときは、ファイルをforで直接回します。これは1行ずつ読むため、大きなファイルでもメモリを節約できます。
# for で1行ずつ(メモリ効率がよい・大きなファイル向き)
with open("log.txt", encoding="utf-8") as f:
for line in f:
print(line.rstrip("\n")) # 末尾の改行を取り除く
# 全行をリストで受け取る(小さなファイル向き)
with open("log.txt", encoding="utf-8") as f:
lines = f.readlines() # ['1行目\n', '2行目\n', ...]
# 改行を除いたリストにする
with open("log.txt", encoding="utf-8") as f:
lines = [line.rstrip("\n") for line in f]
実機で確認したところ、ファイルを行ごとに読むと、各行の末尾に改行\nが付いたままになります(readlines()も同様です)。そのまま使うと余計な空行が入るため、line.rstrip("\n")で末尾の改行を取り除くのが定番です。.strip()を使うと、前後の空白も一緒に取り除けます。大きなファイルはreadlines()で全部読むとメモリを使うため、for line in f:で1行ずつ処理するのがおすすめです。
ファイルに書き込む(w / write)
書き込むには、モードに"w"(write)を指定して開き、write()で書きます。"w"は既存の内容をすべて消して上書きする点に注意してください。
# "w" で書き込む(ファイルが無ければ作成、あれば上書き)
with open("out.txt", "w", encoding="utf-8") as f:
f.write("1行目\n") # 改行は自分で付ける
f.write("2行目\n")
# write は自動で改行しないので、\n を忘れずに
# 複数行をまとめて書く
lines = ["A\n", "B\n", "C\n"]
with open("out.txt", "w", encoding="utf-8") as f:
f.writelines(lines)
実機でも、"w"モードで開くと既存の内容が消え、新しい内容で上書きされました。注意点として、write()は自動で改行を付けません。行を分けたいなら、"1行目\n"のように改行\nを自分で付けます。
追記する(a モード)
既存の内容を消さずに末尾へ書き足したいときは、モードに"a"(append)を使います。ログを書き続けるときなどに使います。
# "a" で追記(既存の内容は消えず、末尾に足される)
with open("log.txt", "a", encoding="utf-8") as f:
f.write("追記行1\n")
f.write("追記行2\n")
# 毎回 "w" にすると上書きされて前の内容が消えるので注意
# ログのように足していくなら "a" を使う
実機でも、"a"モードで書き込むと、既存の内容の後ろに追記され、行数が増えていきました。ログのように書き足していきたいのに"w"を使うと、毎回上書きされて前の内容が消えてしまうので、用途で使い分けてください。
withを使う理由(自動クローズ)
ファイルは、使い終わったら閉じる必要があります。withを使わないと、自分でclose()を呼ぶ必要があり、途中でエラーが起きると閉じ忘れてしまいます。withなら、エラーが起きても確実に閉じられます。
# 古い書き方(close を忘れやすい・エラー時に閉じられない)
f = open("data.txt", encoding="utf-8")
content = f.read()
f.close() # 忘れたり、途中でエラーが起きると閉じられない
# with なら自動で閉じる(エラーが起きても確実に閉じる)
with open("data.txt", encoding="utf-8") as f:
content = f.read()
# ここで自動的に f が閉じられる
withは、ブロックを抜けるときに(途中でエラーが起きても)ファイルを自動で閉じます。閉じ忘れによるトラブルを防げるため、ファイルを開くときはwithを使うのが基本です。
開くモードの一覧
open()の第2引数で「どう開くか」を指定します。よく使うモードをまとめます。
| モード | 意味 |
|---|---|
"r" |
読み込み(既定)。ファイルが無いとエラー |
"w" |
書き込み。既存の内容を消して上書き(無ければ作成) |
"a" |
追記。末尾に書き足す(無ければ作成) |
"x" |
新規作成。すでにあるとエラー |
"r+" |
読み書き両用 |
"rb" / "wb" |
バイナリで読み/書き(画像など) |
画像や音声などのテキストでないファイルは、"rb"・"wb"のようにバイナリモード(b)で開きます。バイナリモードではencodingは指定しません(バイト列をそのまま扱うためです)。
よくある失敗
encodingを指定せず文字化け・エラーになる
Windowsの既定はcp932です。UTF-8のファイルはencoding="utf-8"を指定して読み書きします。
追記したいのに”w”で上書きする
"w"は既存の内容を消します。書き足したいなら"a"を使います。
writeで改行を付け忘れる
write()は自動で改行しません。行を分けるには"\n"を自分で付けます。
読んだ行の末尾の改行を処理しない
1行ずつ読むと末尾に\nが付きます。line.rstrip("\n")やline.strip()で取り除きます。
withを使わずcloseを忘れる
自分でclose()を呼ぶと忘れやすく、エラー時に閉じられません。withを使えば自動で閉じます。
よくある質問
encodingの指定漏れが原因のことが多いです。Windowsの既定はcp932のため、UTF-8のファイルはopen("file.txt", encoding="utf-8")のようにencoding="utf-8"を指定してください。書き込み時も同様です。"a"を指定します。with open("log.txt", "a", encoding="utf-8") as f:のようにすると、既存の内容を消さずに末尾へ書き足せます。"w"は上書きなので、追記には使いません。for line in f:で1行ずつ処理します。read()やreadlines()は全体をメモリに読み込むため、巨大なファイルでは1行ずつ処理するほうがメモリを節約できます。line.rstrip("\n")で末尾の改行だけを取り除けます。前後の空白もまとめて取り除きたいときはline.strip()を使います。1行ずつ読むと改行が付いたままになる点に注意します。withを使うと、ブロックを抜けるときに(途中でエラーが起きても)ファイルが自動で閉じられます。自分でclose()を呼ぶ方法は閉じ忘れやエラー時の問題が起きやすいため、withが推奨されます。まとめ
- 読み書きは
with open("file", encoding="utf-8") as f:が基本形です。 encoding="utf-8"を必ず指定します。Windowsの既定cp932だと文字化けします。- 全体は
f.read()、行ごとはfor line in f:(末尾の\nはrstrip)です。 - 書き込みは
"w"(上書き)、追記は"a"。"w"は既存の内容を消します。 write()は自動で改行しないため、"\n"を自分で付けます。withを使えば、エラーが起きてもファイルが自動で閉じられます。
Pythonのファイル操作は、with openとencoding="utf-8"を組み合わせるのが基本です。「encodingを必ず指定」「追記はa、上書きはw」の2点を押さえれば、文字化けや内容の消失といったトラブルを避けて、安全に読み書きできます。