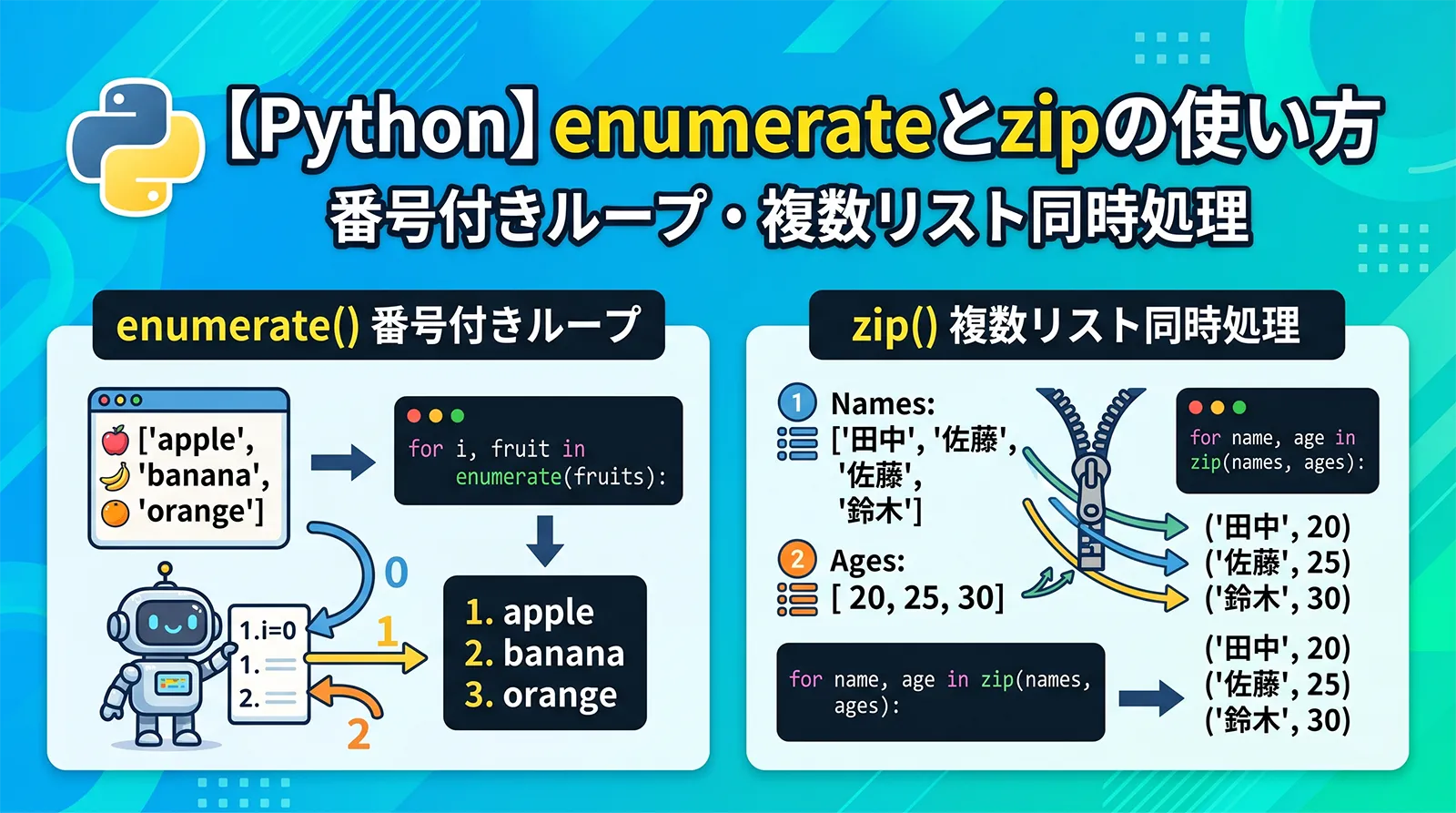
リストをループするとき、「何番目か」も一緒に知りたい、あるいは「2つのリストを同時に」処理したい、という場面はよくあります。Pythonでは、番号付きのループにenumerate()、複数のリストを並べて処理するのにzip()を使います。どちらもfor文と組み合わせる定番の関数です。
注意したいのは、zip()は長さの違うリストを渡すと、短いほうに合わせて止まることと、zip()の結果は一度しか回せないことです。知らないとデータが欠けたり、2回目のループが空になったりします。この記事では、実機のPythonで確認しながら、enumerateとzipを整理します。
for i, x in enumerate(リスト):で、番号iと要素xを同時に取り出せます。- 番号を1から始めたいときは
enumerate(リスト, 1)とします。 for a, b in zip(リスト1, リスト2):で、2つのリストを同時に処理できます。zip()は短いほうのリストに合わせて止まります(余った要素は無視)。dict(zip(キー, 値))で、2つのリストから辞書を作れます。zip()の結果は一度しか回せません。何度も使うならlist()にします。
ループの対象になるリスト(list)、zipから作る辞書(dict)、ループ処理を一行で書く内包表記もあわせて参考になります。
enumerate(番号付きでループ)
enumerate()を使うと、ループの中で番号(インデックス)と要素を同時に受け取れます。「何番目の項目か」を表示したいときに便利です。
fruits = ["りんご", "みかん", "ぶどう"]
for i, fruit in enumerate(fruits):
print(i, fruit)
# 0 りんご
# 1 みかん
# 2 ぶどう
# i は番号(0始まり)、fruit は要素
実機でも、enumerate(fruits)は(0, "りんご"), (1, "みかん")…と、番号と要素のペアを順に返しました。for i, fruit in ...と2つの変数で受け取ると、iに番号、fruitに要素が入ります。番号は標準で0から始まります。
range(len())より enumerate
番号付きループはrange(len(リスト))でも書けますが、enumerate()のほうが読みやすく、ミスも減ります。Pythonではenumerate()が推奨される書き方です。
fruits = ["りんご", "みかん", "ぶどう"]
# 古い書き方(読みにくい・fruits[i] の取り出しが必要)
for i in range(len(fruits)):
print(i, fruits[i])
# 推奨(番号と要素を直接受け取れる)
for i, fruit in enumerate(fruits):
print(i, fruit)
range(len(リスト))で番号を作り、リスト[i]で要素を取り出す書き方は、Pythonでは回りくどいとされています。enumerate()を使えば、番号と要素を同時に、添字なしで受け取れるため、コードが短く読みやすくなります。リスト[i]の書き間違いや範囲外アクセスも防げます。「番号がほしいからrange(len())」と書きたくなったら、まずenumerate()で書けないか考えるのがおすすめです。
enumerateの開始番号を変える start
番号を1から始めたいときは、enumerate()の第2引数に開始番号を渡します。「1番目、2番目…」と表示したいときに便利です。
fruits = ["りんご", "みかん", "ぶどう"]
# 1 から始める
for i, fruit in enumerate(fruits, 1):
print(f"{i}番目: {fruit}")
# 1番目: りんご
# 2番目: みかん
# 3番目: ぶどう
# start= と書いてもよい
for i, fruit in enumerate(fruits, start=1):
print(i, fruit)
実機でも、enumerate(fruits, 1)とすると番号が1, 2, 3から始まりました。第2引数(start)で好きな開始番号を指定できます。人に見せる「○番目」のような表示では、1始まりにすると分かりやすくなります。
zip(複数のリストを同時に)
zip()は、複数のリストを同じ位置どうしで組にして取り出します。名前のリストと年齢のリストを同時に処理する、といったことができます。
names = ["田中", "鈴木", "佐藤"]
ages = [20, 30, 40]
for name, age in zip(names, ages):
print(f"{name}さんは{age}歳")
# 田中さんは20歳
# 鈴木さんは30歳
# 佐藤さんは40歳
# 3つ以上も同時に渡せる
cities = ["東京", "大阪", "名古屋"]
for name, age, city in zip(names, ages, cities):
print(name, age, city)
実機でも、zip(names, ages)は("田中", 20), ("鈴木", 30)…と、同じ位置の要素を組にして返しました。for name, age in ...でそれぞれの変数に取り出せます。リストを3つ以上渡せば、その分だけ同時に処理できます。インデックスを使わずに複数リストを並べて扱えるのがzip()の便利な点です。
zipは短いほうに合わせて止まる
ここがzip()の注意点です。長さの違うリストを渡すと、もっとも短いリストに合わせて止まり、余った要素は無視されます。データが欠けていることに気づきにくいので注意します。
a = [1, 2, 3] b = ["x", "y"] print(list(zip(a, b))) # [(1, 'x'), (2, 'y')] # 3 は b に相手がいないので捨てられる(エラーにはならない)
実機で確認したところ、zip([1,2,3], ["x","y"])は[(1, 'x'), (2, 'y')]になり、余った3は黙って捨てられました(エラーにはなりません)。長さがそろっている前提のデータならよいのですが、片方が短いことに気づかないと、データが欠けたまま処理が進んでしまいます。すべての要素を残したい場合は、後述のzip_longestを使うか、事前にlen()で長さが同じか確認すると安全です。
zipで辞書を作る dict(zip())
「キーのリスト」と「値のリスト」から辞書を作りたいときは、dict(zip(キー, 値))が便利です。2つのリストを対応させて、一気に辞書にできます。
keys = ["name", "age", "city"]
values = ["田中", 20, "東京"]
person = dict(zip(keys, values))
print(person)
# {'name': '田中', 'age': 20, 'city': '東京'}
print(person["name"]) # 田中
実機でも、dict(zip(keys, values))で{'name': '田中', 'age': 20, 'city': '東京'}という辞書ができました。CSVのヘッダー行とデータ行を対応づけて辞書にする、といった処理でよく使うパターンです。
zip(*)で転置・展開
zip()に*を付けてリストを渡すと、組をほどく(転置する)ことができます。ペアのリストを、要素ごとのリストに分けたいときに使います。
pairs = [(1, "a"), (2, "b"), (3, "c")]
# zip(*pairs) で「番号の組」と「文字の組」に分ける
numbers, letters = zip(*pairs)
print(numbers) # (1, 2, 3)
print(letters) # ('a', 'b', 'c')
# 行と列を入れ替える(転置)にも使える
matrix = [[1, 2, 3], [4, 5, 6]]
print(list(zip(*matrix))) # [(1, 4), (2, 5), (3, 6)]
実機でも、zip(*pairs)で(1, 2, 3)と('a', 'b', 'c')に分けられました。zip()でまとめたものをzip(*)でほどく、という逆の関係になっています。zip(*行列)と書けば、行と列を入れ替える(転置する)こともできます。
長さが違うとき zip_longest
短いほうで止めず、長いほうに合わせたいときは、itertoolsのzip_longest()を使います。足りない部分は指定した値(fillvalue)で埋められます。
from itertools import zip_longest a = [1, 2, 3] b = ["x", "y"] # 足りない分を "-" で埋める print(list(zip_longest(a, b, fillvalue="-"))) # [(1, 'x'), (2, 'y'), (3, '-')]
実機でも、zip_longest(a, b, fillvalue="-")は[(1, 'x'), (2, 'y'), (3, '-')]となり、足りない部分が"-"で埋められました。fillvalueを指定しないとNoneで埋められます。すべての要素を漏らさず処理したいときは、通常のzip()ではなくこちらを使います。
zipは一度しか回せない
もう1つの注意点です。zip()が返すのはイテレータで、一度ループすると中身が消費されてしまいます。同じzipの結果を2回使おうとすると、2回目は空になります。
names = ["A", "B"]
ages = [1, 2]
z = zip(names, ages)
print(list(z)) # [('A', 1), ('B', 2)]
print(list(z)) # [] ← 2回目は空!(消費済み)
# 何度も使いたいなら、先に list にしておく
pairs = list(zip(names, ages))
print(pairs) # [('A', 1), ('B', 2)]
print(pairs) # [('A', 1), ('B', 2)](何度でもOK)
実機で確認したところ、z = zip(...)の結果をlist(z)で1回取り出したあと、もう一度list(z)すると[](空)になりました。zip()の結果は一度使うと消費されるイテレータだからです。forでループするのも消費にあたるため、同じzipの結果を複数回ループに使いたいときは、pairs = list(zip(...))のように先にリストへ変換しておきます。これはenumerate()やmap()など、ほかのイテレータを返す関数にも共通する注意点です。
よくある失敗
番号付きループをrange(len())で書く
回りくどく、ミスのもとです。enumerate()で番号と要素を同時に受け取ります。
zipで長さの違いに気づかない
短いほうで止まり、余りは黙って捨てられます。zip_longest()やlen()での確認を検討します。
zipの結果を2回使おうとする
一度ループすると消費されます。使い回すならlist(zip(...))にします。
enumerateの番号を1始まりにし忘れる
標準は0始まりです。1から始めたいときはenumerate(リスト, 1)とします。
zip(*)とzip()を混同する
zip()はまとめる、zip(*)はほどく(転置する)操作です。
よくある質問
for i, x in enumerate(リスト):と書くと、iに番号、xに要素が入ります。番号は標準で0から始まります。1から始めたいときはenumerate(リスト, 1)のように第2引数で開始番号を指定します。for a, b in zip(リスト1, リスト2):を使います。同じ位置の要素どうしが組になって取り出せます。3つ以上のリストも同時に渡せます。ただし長さが違うと短いほうで止まる点に注意してください。itertools.zip_longest()を使い、足りない部分をfillvalueで埋めます。dict(zip(キーのリスト, 値のリスト))で作れます。同じ位置のキーと値が対応した辞書になります。CSVのヘッダーと値を対応づけるときなどに便利です。zip()の結果は一度使うと消費されるイテレータのためです。複数回使いたいときは、pairs = list(zip(...))のように先にリストへ変換しておけば、何度でもループできます。まとめ
- 番号付きループは
for i, x in enumerate(リスト):。range(len())より読みやすいです。 - 開始番号は
enumerate(リスト, 1)で変えられます。 - 複数リストの同時処理は
for a, b in zip(リスト1, リスト2):。 zip()は短いほうで止まります。全部使うならzip_longest()。dict(zip(...))で辞書化、zip(*...)で転置できます。zip()の結果は一度しか回せません。使い回すならlist()に。
enumerateとzipを使いこなすと、ループまわりのコードがぐっと簡潔になります。とくに「番号がほしいならenumerate」「複数のリストを並べたいならzip」という使い分けと、zipの「短いほうで止まる」「一度しか回せない」という2つの性質を覚えておけば、思わぬデータ欠けやバグを避けられます。