SQL Serverでインデックスを作ったのに、実行計画を見ると Index Seek にならず、Index Scan や Table Scan になっていることがあります。インデックスが存在していても、SQLの書き方、データ型、条件の形、統計情報、取得列によっては、SQL Serverがそのインデックスを効率よく使えません。
この記事では、SQL Serverでインデックスが使われない原因を、暗黙変換、列側関数、LIKE、複合インデックスの列順、OR条件、Key Lookup、統計情報、実行計画の確認方法まで実務向けに整理します。
インデックスが使われないときは、まず実行計画で
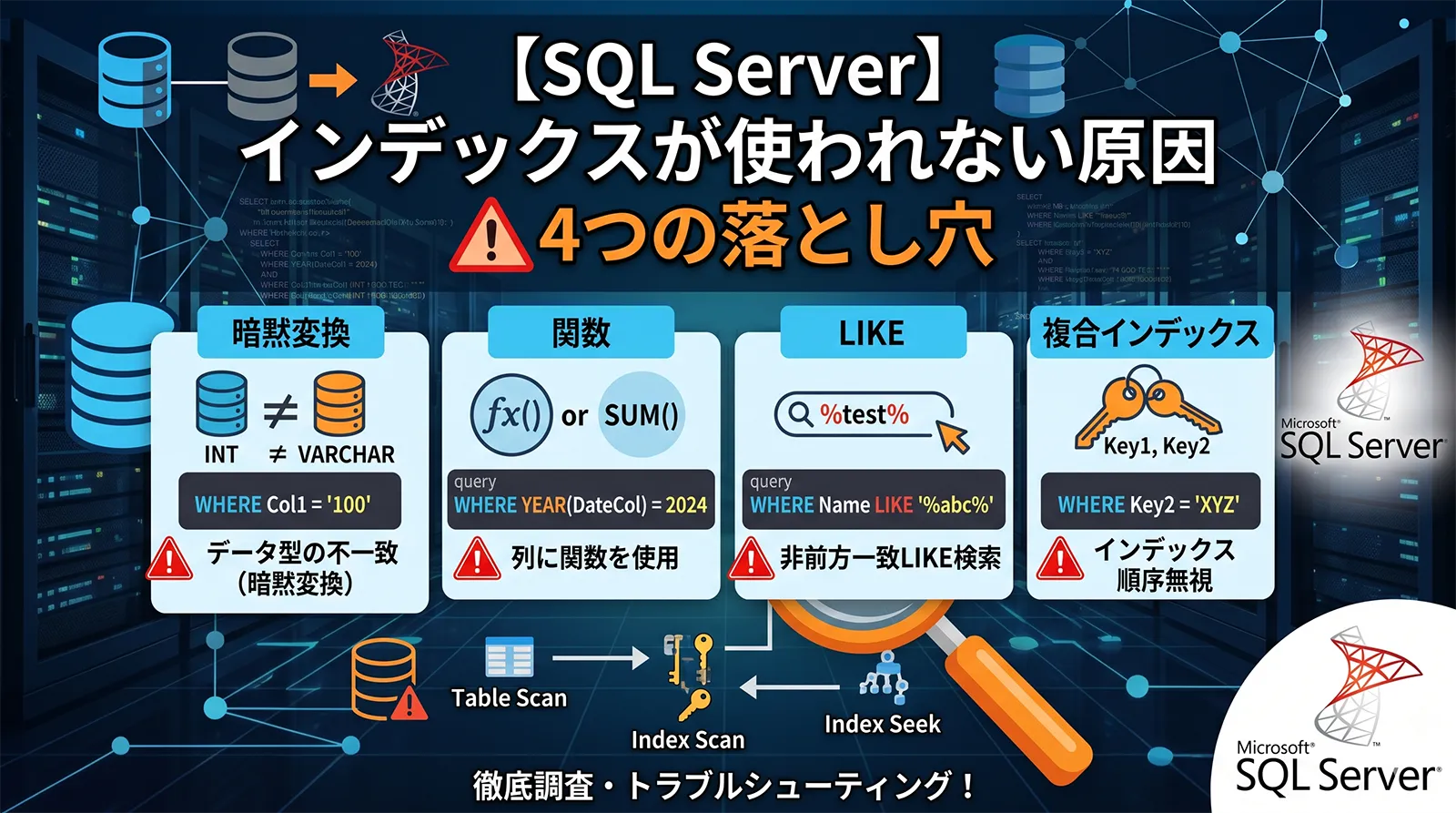
Seek Predicate、Predicate、CONVERT_IMPLICIT、Index Scan、Key Lookup、推定行数と実際の行数を確認します。よくある原因は、列側に関数をかけている、データ型が合わず暗黙変換が起きている、前方一致ではないLIKEを使っている、複合インデックスの先頭列を使っていない、取得列が多くLookupが大量発生している、統計情報が古い、計算列やフィルターインデックスの条件が合っていない、の7つです。- まず見るチェックリスト
- インデックスがあるのに使われない主な原因
- 原因1: 暗黙変換でインデックスが使われない
- 暗黙変換を実行計画から探す
- 原因2: 列側に関数をかけている
- 原因3: LIKEの先頭ワイルドカード
- 原因4: 複合インデックスの列順が合っていない
- 原因5: フィルターインデックスの条件が合っていない
- 原因6: 計算列インデックスの条件を満たしていない
- 原因7: OR条件で広く読まれる
- 原因8: Key Lookupが大量に発生している
- 原因9: 統計情報が古い
- 原因10: パラメータ値によって最適な計画が違う
- インデックス利用状況を確認する
- Missing Indexはそのまま作らない
- 改善前後を必ず測る
- やってはいけない対応
- よくある質問
- まとめ
まず見るチェックリスト
インデックスが使われない原因を探すときは、次の順番で確認すると迷いにくいです。
- 実行計画で
Index Seek、Index Scan、Table Scanのどれかを見る Seek PredicateとPredicateのどちらに条件が入っているかを見るCONVERT_IMPLICITや暗黙変換の警告がないかを見る- WHERE句で列側に関数や計算をかけていないかを見る
- LIKEが前方一致か、先頭ワイルドカードかを見る
- 複合インデックスの先頭列を条件に使っているかを見る
- フィルターインデックスのWHERE条件とクエリ条件が一致しているかを見る
- 計算列インデックスを使うためのSETオプションが合っているかを見る
Key Lookupが大量に繰り返されていないかを見る- 統計情報が古く、推定行数が外れていないかを見る
実行計画そのものの読み方は、次の記事で詳しく整理しています。
インデックスがあるのに使われない主な原因
| 原因 | 起きること | 確認する場所 |
|---|---|---|
| 暗黙変換 | 列側が変換され、Seekしにくくなる | CONVERT_IMPLICIT、実行計画の警告 |
| 列側関数 | インデックスキーの値をそのまま検索できない | WHERE句、Seek Predicate |
| LIKEの先頭ワイルドカード | 先頭から範囲を絞れない | LIKE '%abc'、LIKE '%abc%' |
| 複合インデックスの列順不一致 | 先頭列を使えず、広く読む | インデックス定義、WHERE句、ORDER BY |
| 取得列が多い | Key Lookup が大量発生する |
Lookup回数、出力列、INCLUDE列 |
| フィルターインデックスの条件不一致 | 小さいインデックスが使われない | インデックス定義のWHERE句、クエリ条件 |
| 計算列インデックスのSETオプション不一致 | 作成済みインデックスがオプティマイザーに無視される | SETオプション、計算列の決定性 |
| 統計情報が古い | 行数見積もりが外れ、別の計画が選ばれる | 推定行数と実際の行数、統計情報更新日時 |
原因1: 暗黙変換でインデックスが使われない
列とパラメータ、列とリテラルのデータ型が違うと、SQL Serverが暗黙変換を行うことがあります。Microsoft Learnでは、異なるデータ型の式を比較するとき、データ型の優先順位に従って低い優先順位の型が高い優先順位の型へ変換されると説明されています。この変換が列側に発生すると、インデックスを効率よく使えないことがあります。
-- CustomerCode列がvarchar(20)なのに、nvarcharパラメータで比較している例 DECLARE @CustomerCode nvarchar(20) = N'C001'; SELECT OrderID, CustomerCode, OrderDate FROM dbo.Orders WHERE CustomerCode = @CustomerCode;
列が varchar、パラメータが nvarchar のように型が合っていない場合、照合順序や型の優先順位によって、列側に CONVERT_IMPLICIT が出ることがあります。実行計画で暗黙変換の警告や CONVERT_IMPLICIT を確認します。
-- 列定義に合わせてパラメータ型をそろえる DECLARE @CustomerCode varchar(20) = 'C001'; SELECT OrderID, CustomerCode, OrderDate FROM dbo.Orders WHERE CustomerCode = @CustomerCode;
アプリケーション側のパラメータ型も重要です。.NETやORMからSQL Serverへ渡す型が、テーブル定義と合っているか確認します。文字列、数値、日付で型が微妙に違うだけでも、実行計画に影響することがあります。
暗黙変換を実行計画から探す
キャッシュされた実行計画XMLから CONVERT_IMPLICIT を含むSQLを探すこともできます。調査の入口として使い、見つかったSQLを個別に確認します。
SELECT TOP (50)
qs.execution_count,
qs.total_logical_reads,
qs.total_worker_time,
SUBSTRING(
st.text,
(qs.statement_start_offset / 2) + 1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2) + 1
) AS statement_text,
qp.query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp
WHERE CAST(qp.query_plan AS nvarchar(max)) LIKE '%CONVERT_IMPLICIT%'
ORDER BY qs.total_logical_reads DESC;
継続的に見るならQuery Storeも有効です。Query Storeで重いSQLを見つけ、その実行計画に暗黙変換がないか確認します。
原因2: 列側に関数をかけている
WHERE句で列側に関数や計算をかけると、インデックスキーの値をそのまま使って範囲を絞りにくくなります。典型例は、日付列に CONVERT や YEAR をかける書き方です。
-- 悪い例: OrderDate列に関数をかけている SELECT OrderID, OrderDate, CustomerID FROM dbo.Orders WHERE CONVERT(date, OrderDate) = '2026-05-01';
-- 改善例: 列側を加工せず、範囲条件にする SELECT OrderID, OrderDate, CustomerID FROM dbo.Orders WHERE OrderDate >= '2026-05-01' AND OrderDate < '2026-05-02';
この書き方なら、OrderDate のインデックスで範囲検索しやすくなります。日付のみ比較する方法は次の記事でも整理しています。
原因3: LIKEの先頭ワイルドカード
LIKE 'abc%' のような前方一致は、インデックスで範囲を絞れることがあります。一方、LIKE '%abc' や LIKE '%abc%' のように先頭がワイルドカードの場合、先頭から値を探せないため、広く読む必要が出ます。
| 条件 | インデックス利用のしやすさ | 理由 |
|---|---|---|
LIKE 'abc%' |
使いやすい | 先頭から範囲を絞れる |
LIKE '%abc' |
使いにくい | 先頭が不明で範囲を絞れない |
LIKE '%abc%' |
使いにくい | 任意位置検索になる |
LIKE @keyword + '%' |
条件次第 | パラメータ値と統計情報の影響を受ける |
-- 前方一致。Name列のインデックスを使いやすい SELECT CustomerID, CustomerName FROM dbo.Customers WHERE CustomerName LIKE 'tanaka%'; -- 部分一致。通常のB-treeインデックスでは絞りにくい SELECT CustomerID, CustomerName FROM dbo.Customers WHERE CustomerName LIKE '%tanaka%';
部分一致検索が重要な要件なら、通常のB-treeインデックスだけで解決しようとせず、全文検索、検索用の別列、N-gramのような検索設計を検討します。
原因4: 複合インデックスの列順が合っていない
複合インデックスは、列順が重要です。たとえば (CustomerID, OrderDate) のインデックスは、CustomerID を条件に使う検索に向いています。しかし OrderDate だけで検索する場合は、先頭列を使えないため、効きにくいことがあります。
CREATE INDEX IX_Orders_CustomerID_OrderDate ON dbo.Orders (CustomerID, OrderDate); -- 使いやすい: 先頭列CustomerIDを条件に使っている SELECT OrderID, CustomerID, OrderDate FROM dbo.Orders WHERE CustomerID = 100 AND OrderDate >= '2026-05-01'; -- 使いにくい: 先頭列CustomerIDを使っていない SELECT OrderID, CustomerID, OrderDate FROM dbo.Orders WHERE OrderDate >= '2026-05-01';
複合インデックスの列順は、WHERE句の等価条件、範囲条件、JOIN条件、ORDER BY、実行回数を見て決めます。単に条件に出てくる列を全部並べればよいわけではありません。
原因5: フィルターインデックスの条件が合っていない
フィルターインデックスは、テーブル全体ではなく一部の行だけを対象にする非クラスタ化インデックスです。Microsoft Learnでも、よく定義された部分集合を選択するクエリに適しており、フルテーブルの非クラスタ化インデックスより小さく、保守コストやストレージを減らせると説明されています。
-- 未処理の注文だけを対象にするフィルターインデックス CREATE INDEX IX_Orders_Unprocessed ON dbo.Orders (OrderDate) INCLUDE (CustomerID, TotalAmount) WHERE ProcessedFlag = 0; -- 使いやすい: フィルター条件と一致している SELECT OrderID, CustomerID, OrderDate, TotalAmount FROM dbo.Orders WHERE ProcessedFlag = 0 AND OrderDate >= '2026-05-01'; -- 使いにくい: フィルター条件がクエリから判断しにくい DECLARE @ProcessedFlag bit = 0; SELECT OrderID, CustomerID, OrderDate, TotalAmount FROM dbo.Orders WHERE ProcessedFlag = @ProcessedFlag AND OrderDate >= '2026-05-01';
フィルターインデックスを使わせたい場合は、クエリ条件がフィルター条件の部分集合だとSQL Serverが判断できる必要があります。また、フィルターインデックスのフィルター条件では LIKE はサポートされません。部分一致検索のためにフィルターインデックスを作る設計は避けます。
原因6: 計算列インデックスの条件を満たしていない
列側関数を避けられない場合、計算列を作ってその計算列にインデックスを作る方法があります。ただし、計算列インデックスには決定性、精度、データ型、SETオプションなどの条件があります。Microsoft Learnでは、QUOTED_IDENTIFIER をONにする必要があり、さらにSELECT実行側の接続でも必要なSETオプションが一致しないと、オプティマイザーがそのインデックスを無視すると説明されています。
-- 日付だけで検索するための計算列例 ALTER TABLE dbo.Orders ADD OrderDateOnly AS CONVERT(date, OrderDate) PERSISTED; CREATE INDEX IX_Orders_OrderDateOnly ON dbo.Orders (OrderDateOnly); SELECT OrderID, CustomerID, OrderDate FROM dbo.Orders WHERE OrderDateOnly = '2026-05-01';
-- 計算列インデックスやインデックス付きビューで重要なSETオプション SET ANSI_NULLS ON; SET ANSI_PADDING ON; SET ANSI_WARNINGS ON; SET ARITHABORT ON; SET CONCAT_NULL_YIELDS_NULL ON; SET QUOTED_IDENTIFIER ON; SET NUMERIC_ROUNDABORT OFF;
計算列インデックスは便利ですが、関数を使った検索をすべて計算列で解決するものではありません。まずは列側を加工しない範囲条件にできないかを検討し、それでも難しい場合に候補にします。
原因7: OR条件で広く読まれる
OR 条件では、複数の条件をまとめて評価するため、インデックスを効率よく使いにくいことがあります。条件ごとに使いたいインデックスが違う場合は、UNION ALL で分けると改善することがあります。
-- OR条件で広く読まれることがある SELECT OrderID, CustomerID, Status, OrderDate FROM dbo.Orders WHERE CustomerID = 100 OR Status = 'Cancelled'; -- 条件ごとに分ける案。重複が出る条件なら除外条件やUNIONを検討する SELECT OrderID, CustomerID, Status, OrderDate FROM dbo.Orders WHERE CustomerID = 100 UNION ALL SELECT OrderID, CustomerID, Status, OrderDate FROM dbo.Orders WHERE Status = 'Cancelled' AND CustomerID <> 100;
ただし、UNION ALL へ書き換えれば必ず速くなるわけではありません。重複条件、結果件数、ソート有無、実行計画を比較して判断します。
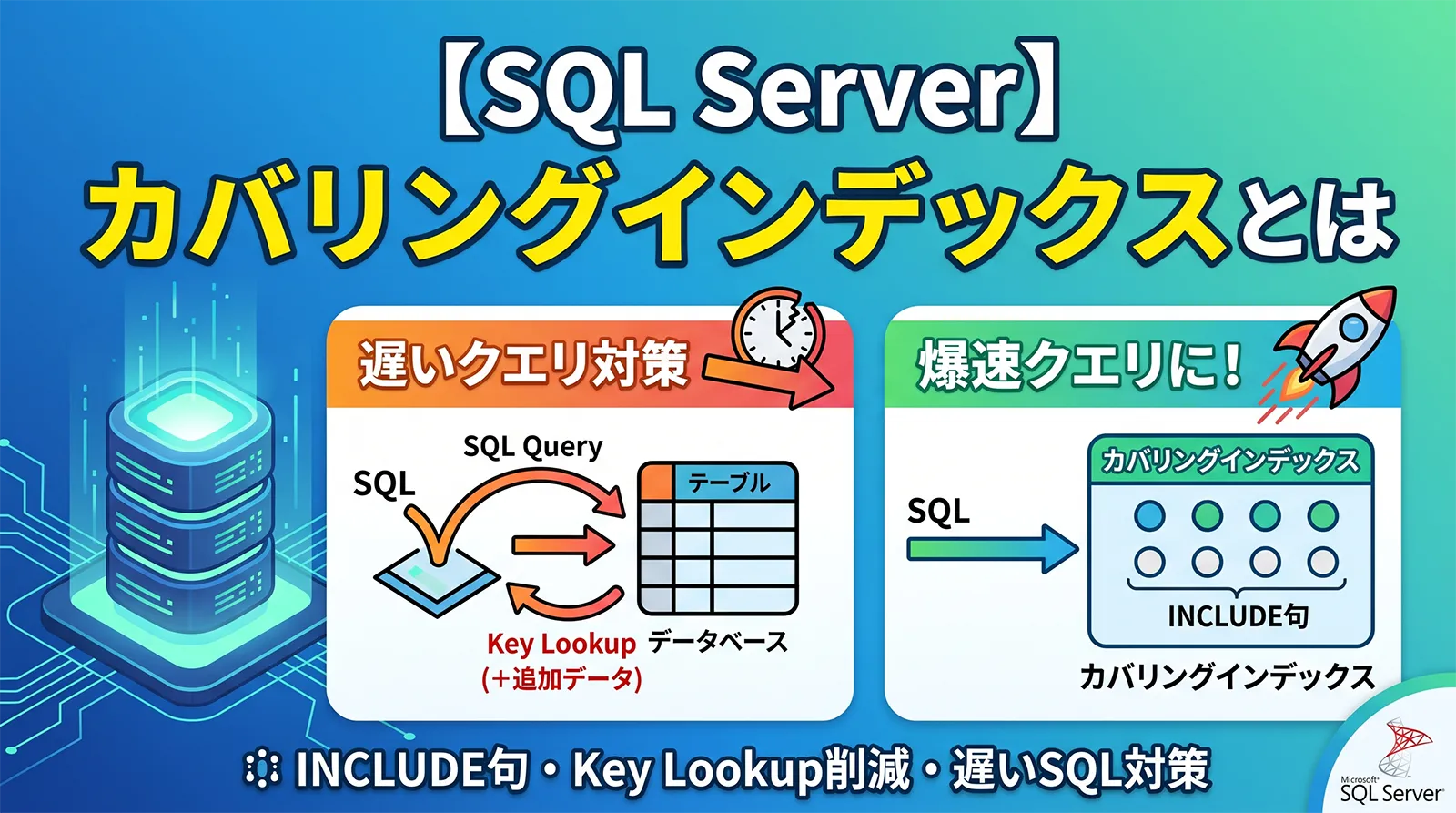
原因8: Key Lookupが大量に発生している
インデックス自体は使われていても、取得列がインデックスに含まれていないと、Key Lookup で不足列を取りに行くことがあります。少数行なら問題になりにくいですが、大量行でLookupが繰り返されると遅くなります。
CREATE INDEX IX_Orders_CustomerID
ON dbo.Orders (CustomerID);
-- CustomerIDではSeekできても、取得列が多いとLookupが発生することがある
SELECT
OrderID,
CustomerID,
OrderDate,
TotalAmount,
ShippingAddress
FROM dbo.Orders
WHERE CustomerID = 100;
よく使う取得列を INCLUDE すると、Lookupを減らせることがあります。Microsoft Learnでも、非キー列を含めることで、クエリが必要とする列をインデックス内で満たし、テーブルやクラスタ化インデックスへのアクセスを避けられると説明されています。
CREATE INDEX IX_Orders_CustomerID_Covering ON dbo.Orders (CustomerID) INCLUDE (OrderDate, TotalAmount, ShippingAddress);
ただし、INCLUDE列を増やしすぎるとインデックスが大きくなり、更新負荷も増えます。実行回数が多いSQL、業務上重要なSQL、logical readsが大きいSQLから優先して検討します。
原因9: 統計情報が古い
インデックスがあっても、統計情報が古いと行数見積もりが外れ、期待したインデックスが選ばれないことがあります。実行計画で推定行数と実際の行数が大きくズレる場合は、統計情報も確認します。
SELECT
s.name AS stats_name,
sp.last_updated,
sp.rows,
sp.rows_sampled,
sp.modification_counter
FROM sys.stats AS s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS sp
WHERE s.object_id = OBJECT_ID(N'dbo.Orders')
ORDER BY sp.modification_counter DESC;
原因10: パラメータ値によって最適な計画が違う
あるパラメータ値では少数行、別の値では大量行を返す場合、同じインデックスでも最適な実行計画が変わります。少数行向けの計画が大量行に再利用されると、Lookupが大量発生して遅くなることがあります。
Query Storeを使うと、同じSQLに複数の実行計画があるか、計画変更で遅くなったかを追いやすくなります。
インデックス利用状況を確認する
既存インデックスが実際に使われているかは、sys.dm_db_index_usage_stats で確認できます。ただし、この情報はSQL Server再起動やDBのデタッチなどでリセットされます。一時点の参考情報として扱います。
SELECT
OBJECT_SCHEMA_NAME(i.object_id) AS schema_name,
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
i.index_id,
i.type_desc,
us.user_seeks,
us.user_scans,
us.user_lookups,
us.user_updates,
us.last_user_seek,
us.last_user_scan,
us.last_user_lookup,
us.last_user_update
FROM sys.indexes AS i
LEFT JOIN sys.dm_db_index_usage_stats AS us
ON us.object_id = i.object_id
AND us.index_id = i.index_id
AND us.database_id = DB_ID()
WHERE OBJECTPROPERTY(i.object_id, 'IsUserTable') = 1
ORDER BY us.user_seeks DESC, us.user_scans DESC;
使われていないように見えるインデックスでも、月次処理や障害対応で使われることがあります。削除判断は、業務処理、実行頻度、メンテナンス履歴を確認してから行います。
Missing Indexはそのまま作らない
実行計画にMissing Indexが出ることがあります。これは有用なヒントですが、そのまま本番で作るものではありません。既存インデックスとの重複、列順、INCLUDE列、更新負荷、他SQLへの影響を確認します。
SELECT TOP (30)
DB_NAME(mid.database_id) AS database_name,
OBJECT_NAME(mid.object_id, mid.database_id) AS table_name,
migs.user_seeks,
migs.user_scans,
migs.avg_total_user_cost,
migs.avg_user_impact,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns
FROM sys.dm_db_missing_index_group_stats AS migs
JOIN sys.dm_db_missing_index_groups AS mig
ON mig.index_group_handle = migs.group_handle
JOIN sys.dm_db_missing_index_details AS mid
ON mid.index_handle = mig.index_handle
WHERE mid.database_id = DB_ID()
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC;
Missing Indexの提案は、実行されたSQL単体に寄った候補です。似たインデックスを増やしすぎると、INSERT/UPDATE/DELETEが遅くなり、容量も増えます。
改善前後を必ず測る
インデックスやSQLを直したら、実行計画だけでなく、STATISTICS IO、STATISTICS TIME、実行回数、logical readsを比較します。
SET STATISTICS IO ON; SET STATISTICS TIME ON; -- 改善前後で同じ条件・同じパラメータで比較する SELECT OrderID, CustomerID, OrderDate, TotalAmount FROM dbo.Orders WHERE CustomerID = 100 AND OrderDate >= '2026-05-01' AND OrderDate < '2026-06-01'; SET STATISTICS TIME OFF; SET STATISTICS IO OFF;
改善後に tempdb の使用量が減ることもあります。SortやHash Matchが減ったか、Spillが消えたかも確認します。
SQL Serverでtempdbが肥大化する原因と確認方法
やってはいけない対応
| NG対応 | なぜ危ないか | 代わりにやること |
|---|---|---|
| インデックスを闇雲に増やす | 更新負荷と容量が増え、他SQLに悪影響が出る | 重要SQLから実測して追加する |
| Missing Indexを全部作る | 重複インデックスが増えやすい | 既存インデックスと統合する |
| Scanをすべて悪者にする | 大量取得ではScanが妥当なこともある | 取得割合とlogical readsで判断する |
| 列側関数を放置する | SeekしにくいSQLが残る | 範囲条件や計算列を検討する |
| 型不一致をアプリ側で放置する | 暗黙変換が再発する | パラメータ型と列定義をそろえる |
| 効果測定なしで本番反映する | 速くなったか判断できない | 実行計画とIOを保存して比較する |
よくある質問
Index Scanは必ず悪いですか?
必ず悪いわけではありません。テーブルやインデックスの大部分を読むSQLでは、Scanのほうが妥当なことがあります。少数行を取りたいのにScanになっている場合に原因を調べます。
暗黙変換はどこで確認できますか?
実行計画の警告、Predicate、XML内の CONVERT_IMPLICIT で確認できます。列側に変換が出ている場合は、パラメータ型やリテラル型を列定義に合わせます。
LIKE検索でインデックスを使うにはどうしますか?
前方一致の LIKE 'abc%' は使いやすいです。先頭ワイルドカードの LIKE '%abc%' は通常のB-treeインデックスでは効きにくいため、全文検索や検索用設計を検討します。
複合インデックスは列を全部入れればよいですか?
いいえ。列順が重要です。等価条件、範囲条件、JOIN、ORDER BY、実行頻度、選択性を見て設計します。取得列はキー列ではなくINCLUDE列にするほうがよい場合もあります。
統計情報を更新すればインデックスが使われますか?
統計情報が古いことが原因なら改善する可能性があります。ただし、SQLの書き方や型不一致が原因なら、統計情報更新だけでは解決しません。
インデックスが使われているかどうかは何で判断しますか?
実行計画、STATISTICS IO、Query Store、sys.dm_db_index_usage_stats を組み合わせて判断します。単にIndex Seekが出ているかだけでなく、logical readsと実行時間も見ます。
まとめ
SQL Serverでインデックスが使われない原因は、インデックスが存在しないことだけではありません。暗黙変換、列側関数、LIKEの先頭ワイルドカード、複合インデックスの列順、フィルターインデックスの条件不一致、計算列インデックスのSETオプション不一致、OR条件、Key Lookup、統計情報の古さ、パラメータ値の偏りなどで、期待した実行計画にならないことがあります。
まず実行計画で Seek Predicate、Predicate、CONVERT_IMPLICIT、Key Lookup、推定行数と実際の行数を確認します。そのうえで、SQLの条件式、データ型、複合インデックスの列順、INCLUDE列、統計情報を見直し、STATISTICS IO と実行時間で改善前後を比較しましょう。