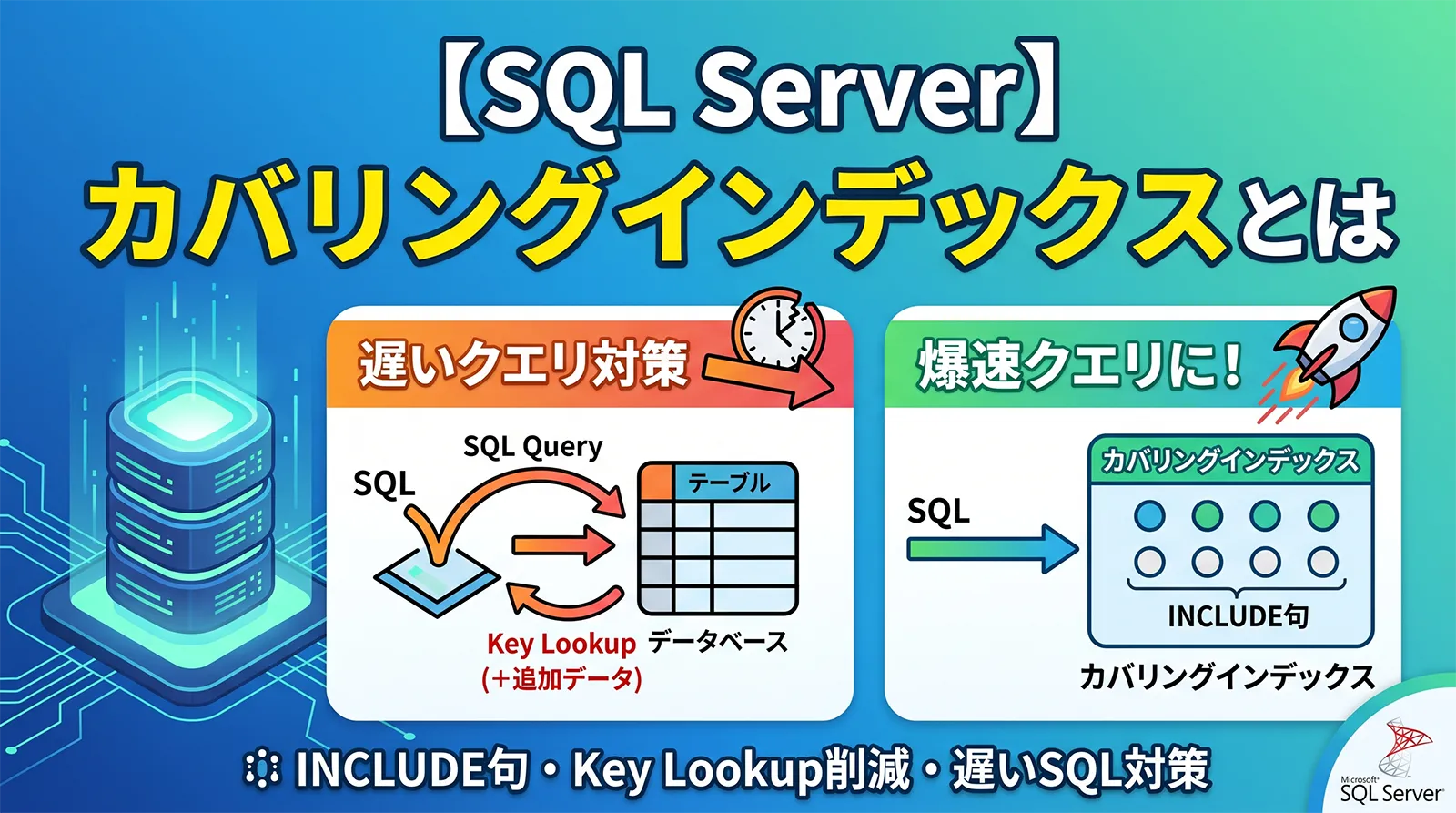
SQL Serverで遅いSQLの実行計画を見ると、Index Seek の後ろに Key Lookup が大量に出ていることがあります。これは、検索条件に使う列はインデックスにあるものの、SELECTで返したい列がインデックス内に足りず、SQL Serverがクラスタ化インデックスや実データ側へ追加で取りに行っている状態です。
このようなときに検討する代表的な対策が、カバリングインデックスです。クエリに必要な列をインデックスだけで満たせるようにして、不要なLookupを減らします。この記事では、SQL Serverのカバリングインデックスの考え方、INCLUDE句の使い方、キー列と付加列の選び方、作成前後の確認方法を実務向けに整理します。
カバリングインデックスは「SQLが必要とする列をインデックス内にそろえる」設計です。
WHERE、JOIN、ORDER BY、GROUP BY に効かせたい列はキー列、SELECTで返すだけの列は INCLUDE に置くのが基本です。ただし、INCLUDE列を増やしすぎると更新負荷と容量が増えるため、実行回数が多く、logical readsが大きいSQLから優先して検証します。判断の流れはシンプルです。まず遅いSQLを特定し、実行計画で Key Lookup と読み取り量を確認します。次にSQLで使う列を「絞り込み・結合・並び替えに使う列」と「返すだけの列」に分け、既存インデックスと重複しない形で候補を作ります。最後に作成前後の STATISTICS IO、実行時間、更新負荷を比べて、残すかどうかを決めます。
カバリングインデックスとは
カバリングインデックスとは、特定のクエリが参照する列をインデックスだけで満たせるようにしたインデックスです。SQL Serverの公式ドキュメントでも、クエリで参照されるすべての列がインデックスに含まれている状態は、そのクエリをカバーしていると説明されています。
たとえば、次のSQLをよく実行しているとします。
SELECT
OrderID,
CustomerID,
OrderDate,
TotalAmount,
Status
FROM dbo.Orders
WHERE CustomerID = 100
AND OrderDate >= '2026-05-01'
AND OrderDate < '2026-06-01'
ORDER BY OrderDate DESC;
このSQLでは、検索条件に CustomerID と OrderDate、並び替えに OrderDate、取得列に OrderID、TotalAmount、Status が必要です。これらをうまくインデックスに含めると、SQL Serverはインデックスだけを読んで結果を返しやすくなります。
Key Lookupが遅くなる理由
Key Lookup は、非クラスタ化インデックスで見つけた行に対して、足りない列をクラスタ化インデックス側から取り直す処理です。少数行なら問題になりにくいですが、対象行が多いとLookupが何度も繰り返され、読み取り回数が増えます。
| 状態 | 起きること | 見直すポイント |
|---|---|---|
| Index Seekだけで完結 | 必要な列がインデックス内にそろっている | 理想形。logical readsも確認する |
| Index Seek + Key Lookup | 検索はできるが、取得列が足りない | SELECT列を削るか、INCLUDE列を検討する |
| Lookup回数が多い | 行ごとに追加読み取りが発生する | カバリングインデックスの効果が出やすい |
| Scanのほうが選ばれる | Lookupより全体読み取りのほうが安いと判断される | 取得行数、統計情報、インデックス設計を確認する |
実行計画の基本的な読み方は、先に SQL Serverの実行計画の見方 で整理しています。この記事では、その中でも Key Lookup を減らす設計に絞って扱います。
INCLUDE句とは
INCLUDE句は、非クラスタ化インデックスに「キーではない列」を追加するための指定です。検索や並び替えのキーとして使う列ではなく、結果を返すために必要な列をインデックスのリーフレベルに持たせます。
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDate ON dbo.Orders (CustomerID, OrderDate DESC) INCLUDE (TotalAmount, Status);
この例では、CustomerID と OrderDate がキー列です。検索条件や並び替えに関わるため、インデックスの順序に意味があります。一方、TotalAmount と Status は返すだけの列なので、INCLUDE に置いています。
| 分類 | 置く列 | 理由 |
|---|---|---|
| キー列 | WHEREで絞る列 |
検索範囲を決めるため |
| キー列 | JOIN条件の列 |
結合先の探索に使うため |
| キー列 | ORDER BYやGROUP BYに効かせたい列 |
ソートや集計前の順序に関わるため |
| INCLUDE列 | SELECTで返すだけの列 | Lookupを避けるため |
| 原則入れない | ほとんど使わない列、巨大な列 | 更新負荷と容量が増えやすいため |
キー列とINCLUDE列の選び方
カバリングインデックスで失敗しやすいのは、必要そうな列を全部キー列に入れてしまうことです。キー列が増えすぎるとインデックスが大きくなり、並び順の意味もぼやけます。まずはSQLを分解して、列の役割を見ます。
SELECT
OrderID, -- 返すだけ
CustomerID, -- 条件にも返却にも使う
OrderDate, -- 条件と並び替えに使う
TotalAmount, -- 返すだけ
Status -- 返すだけ
FROM dbo.Orders
WHERE CustomerID = 100
AND OrderDate >= '2026-05-01'
AND OrderDate < '2026-06-01'
ORDER BY OrderDate DESC;
このSQLなら、まず候補は次のようになります。
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDate ON dbo.Orders (CustomerID, OrderDate DESC) INCLUDE (TotalAmount, Status);
OrderID はクラスタ化キーや主キーの構成によって、非クラスタ化インデックスに自動的に含まれることがあります。実際のテーブル定義によって扱いが変わるため、作成前に既存の主キー・クラスタ化インデックスを確認します。
INCLUDE句の制約と特徴
INCLUDE句は便利ですが、何でも自由に入れられるわけではありません。Microsoft Learnでは、非キー列は非クラスタ化インデックスで使えること、text、ntext、image 以外のデータ型を使えること、非キー列はインデックスキー列数やキーサイズの計算に含まれないことが説明されています。また、非キー列の順番は、そのインデックスを使うクエリの性能には影響しないとされています。
| 項目 | 内容 | 実務での見方 |
|---|---|---|
| 使えるインデックス | 非クラスタ化インデックス | クラスタ化インデックスのキー設計とは分けて考える |
| 使えるデータ型 | text、ntext、image 以外 |
古いLOB型は避け、必要なら型や取得列を見直す |
| キーサイズ | INCLUDE列はキー列数・キーサイズに含まれない | 検索に使わない列はキー列ではなくINCLUDEへ逃がせる |
| 列順 | INCLUDE列の順番は検索性能に影響しにくい | 順番で悩むより、含める列を絞るほうが重要 |
| クラスタ化キー | 非一意の非クラスタ化インデックスにはクラスタ化キーが内部的に含まれる | 主キー列を重複してINCLUDEする必要があるか確認する |
つまり、INCLUDE は「キー列にしたくないが、Lookupを避けるために必要な列」を置く場所です。検索条件や並び替えに効かせたい列までINCLUDEに入れてしまうと、期待した絞り込みやSort削減につながらないことがあります。
作成前に既存インデックスを確認する
新しいインデックスを作る前に、既存インデックスと重複していないかを確認します。似たインデックスがある場合は、新規追加ではなく既存インデックスの統合や置き換えを検討します。
SELECT
i.name AS index_name,
i.type_desc,
i.is_unique,
ic.key_ordinal,
ic.is_included_column,
c.name AS column_name
FROM sys.indexes AS i
JOIN sys.index_columns AS ic
ON ic.object_id = i.object_id
AND ic.index_id = i.index_id
JOIN sys.columns AS c
ON c.object_id = ic.object_id
AND c.column_id = ic.column_id
WHERE i.object_id = OBJECT_ID(N'dbo.Orders')
ORDER BY i.name, ic.key_ordinal, ic.index_column_id;
同じ先頭キー列を持つインデックスが複数ある場合は注意します。たとえば (CustomerID)、(CustomerID, OrderDate)、(CustomerID, OrderDate) INCLUDE (...) が乱立すると、更新処理のたびに複数の似たインデックスが更新されます。
インデックスサイズも確認する
カバリングインデックスは読み取りを減らす代わりに、インデックスサイズが増えます。作成後にどれくらい容量を使っているか、既存インデックスと比べて過剰に大きくなっていないかを確認します。
SELECT
OBJECT_SCHEMA_NAME(i.object_id) AS schema_name,
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
SUM(ps.used_page_count) * 8.0 / 1024 AS used_mb,
SUM(ps.row_count) AS row_count
FROM sys.indexes AS i
JOIN sys.dm_db_partition_stats AS ps
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE i.object_id = OBJECT_ID(N'dbo.Orders')
GROUP BY i.object_id, i.name
ORDER BY used_mb DESC;
読み取りSQLが少し速くなっても、巨大なINCLUDE列でインデックスが肥大化し、更新・バックアップ・メンテナンスの負荷が大きくなるなら採用しないほうがよい場合もあります。
作成前後で効果を測る
カバリングインデックスは、作れば必ず速くなるものではありません。作成前後で同じ条件のSQLを実行し、STATISTICS IO と実行計画を比較します。
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT
OrderID,
CustomerID,
OrderDate,
TotalAmount,
Status
FROM dbo.Orders
WHERE CustomerID = 100
AND OrderDate >= '2026-05-01'
AND OrderDate < '2026-06-01'
ORDER BY OrderDate DESC;
SET STATISTICS TIME OFF;
SET STATISTICS IO OFF;
見るべきポイントは、実行時間だけではありません。実行計画で Key Lookup が消えたか、logical readsが減ったか、Sortが減ったか、推定行数と実際の行数が大きくずれていないかを確認します。
| 確認項目 | 改善している状態 | 注意点 |
|---|---|---|
| Key Lookup | 消える、または回数が減る | 取得列を増やすと再発することがある |
| logical reads | 読み取りページ数が減る | キャッシュ状態の影響を受けるため複数回見る |
| Sort | 不要になる、または軽くなる | ORDER BYとキー列順が合っているか確認する |
| 実行時間 | 安定して短くなる | 初回だけで判断しない |
| 更新負荷 | 許容範囲に収まる | INSERT/UPDATE/DELETEが多い表では特に確認する |
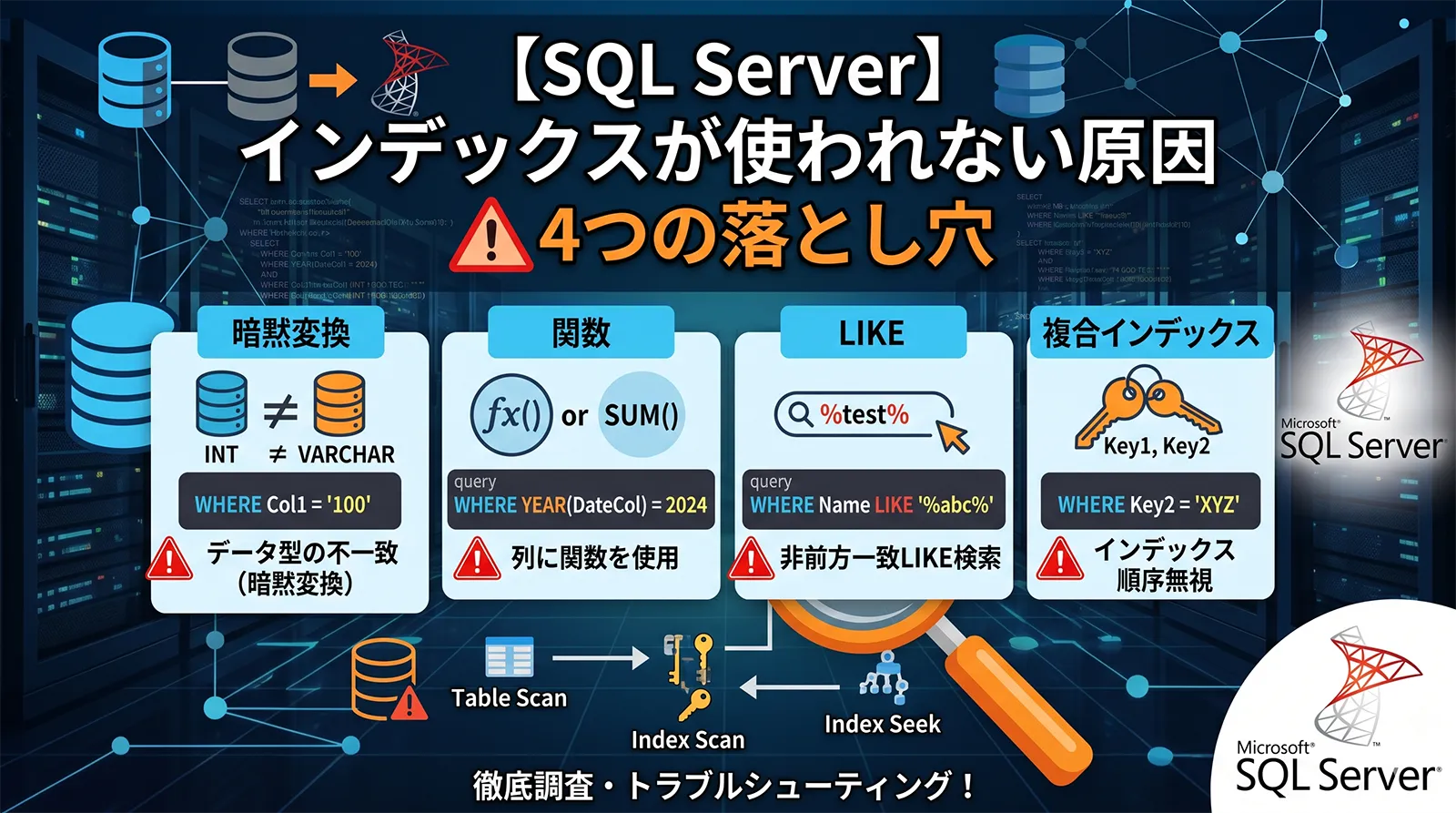
インデックスが使われない原因は SQL Serverでインデックスが使われない原因 でも整理しています。カバリングインデックスを作っても、暗黙変換や列への関数適用が残っていると期待どおりに使われないことがあります。
Missing Indexの提案をそのまま作らない
実行計画にMissing Indexの提案が出ることがあります。これは有用なヒントですが、そのまま本番投入するのは危険です。既存インデックスとの重複、列順、INCLUDE列、更新負荷、他SQLへの影響を確認します。
SELECT TOP (30)
DB_NAME(mid.database_id) AS database_name,
OBJECT_NAME(mid.object_id, mid.database_id) AS table_name,
migs.user_seeks,
migs.user_scans,
migs.avg_total_user_cost,
migs.avg_user_impact,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns
FROM sys.dm_db_missing_index_group_stats AS migs
JOIN sys.dm_db_missing_index_groups AS mig
ON mig.index_group_handle = migs.group_handle
JOIN sys.dm_db_missing_index_details AS mid
ON mid.index_handle = mig.index_handle
WHERE mid.database_id = DB_ID()
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC;
Missing Indexは、実行された特定のクエリから見た候補です。似た候補が複数出ている場合は、個別に作るのではなく、業務上重要なSQLをまとめて見て統合します。
Query Storeで優先順位を決める
どのSQLからカバリングインデックスを検討するか迷う場合は、Query Storeで実行回数、平均時間、読み取り量、計画変更を確認します。たまにしか実行されないSQLより、毎日大量に実行されるSQLのKey Lookupを減らすほうが効果が大きいことが多いです。
Query Storeで候補SQLを絞ったら、実行計画と STATISTICS IO を見て、本当にLookupが問題なのか、統計情報やパラメータスニッフィングが原因なのかを切り分けます。
INCLUDE列を増やしすぎるデメリット
INCLUDE列を増やすと、SELECTは速くなる可能性があります。しかし、インデックス自体は大きくなります。その結果、ディスク容量、メモリ使用量、バックアップサイズ、更新処理の負荷が増えます。
| やりがちな失敗 | 問題 | 対策 |
|---|---|---|
| SELECT列を全部INCLUDEする | インデックスが太くなりすぎる | 実行頻度が高いSQLの必須列に絞る |
| 似たカバリングインデックスを複数作る | 更新負荷と容量が増える | 既存インデックスと統合できないか見る |
| 巨大な文字列列を含める | 読み取り・更新・保守が重くなる | 本当に一覧に必要か、取得列を減らせないか検討する |
| 効果測定せずに本番投入する | 速くなったか判断できない | 作成前後のIOと実行計画を保存する |
| Missing Indexをそのまま作る | 重複インデックスが増える | 列順と既存インデックスを確認して再設計する |
カバリングインデックスが向いているSQL
カバリングインデックスは、すべてのSQLに必要なものではありません。効果が出やすいのは、検索条件がある程度固定され、実行回数が多く、取得列が比較的少ないSQLです。
| 向いているSQL | 理由 |
|---|---|
| 一覧画面の検索SQL | 条件と表示列が固定されやすく、実行回数が多い |
| APIの参照SQL | 同じ形で繰り返し実行されやすい |
| Key Lookupが大量発生しているSQL | INCLUDEで追加読み取りを減らせる可能性がある |
| ORDER BYが固定のSQL | キー列順でSortを減らせる可能性がある |
一方で、取得列が毎回大きく変わるSQLや、テーブルの大部分を読む集計SQLでは、カバリングインデックスだけで解決しないこともあります。その場合はSQLの書き換え、集計用テーブル、パーティション、列ストアインデックスなど別の選択肢も検討します。
作らないほうがよいケース
カバリングインデックスは強力ですが、万能ではありません。特に更新が多いテーブルでは、読み取り改善より更新負荷の増加が大きくなることがあります。
| 見送り候補 | 理由 | 代替案 |
|---|---|---|
| 実行頻度が低いSQL | 得られる改善効果が小さい | まずQuery Storeで頻度と累積コストを見る |
| 取得列が多すぎるSQL | インデックスがテーブルに近い大きさになる | SELECT列を減らす、画面/APIの返却項目を見直す |
| 更新が非常に多い表 | INSERT/UPDATE/DELETEのたびに追加インデックスも更新される | 読み取り用の別設計、バッチ化、集計テーブルを検討する |
| 条件が毎回大きく変わるSQL | 特定のインデックスでカバーしにくい | 動的条件の整理、主要パターンの分離を検討する |
| 根本原因が統計情報や暗黙変換 | インデックス追加だけでは使われない可能性がある | 統計情報更新、型合わせ、SQL書き換えを先に行う |
削除・変更するときの確認
カバリングインデックスを作ったあと、似た既存インデックスを削除したくなることがあります。ただし、別のSQLが使っている可能性があるため、すぐに削除しないほうが安全です。
SELECT
OBJECT_SCHEMA_NAME(i.object_id) AS schema_name,
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
us.user_seeks,
us.user_scans,
us.user_lookups,
us.user_updates,
us.last_user_seek,
us.last_user_scan,
us.last_user_lookup,
us.last_user_update
FROM sys.indexes AS i
LEFT JOIN sys.dm_db_index_usage_stats AS us
ON us.object_id = i.object_id
AND us.index_id = i.index_id
AND us.database_id = DB_ID()
WHERE OBJECTPROPERTY(i.object_id, 'IsUserTable') = 1
AND i.name IS NOT NULL
ORDER BY us.user_updates DESC, us.user_seeks DESC;
sys.dm_db_index_usage_stats はSQL Serverの再起動などでリセットされるため、これだけで削除判断をするのは危険です。業務処理の周期、障害対応時だけ使うSQL、月次処理なども確認します。
よくある質問
INCLUDE列の順番は性能に影響しますか?
通常、非キー列としての INCLUDE 列の順番は、検索や並び替えの性能には大きく影響しません。順番が重要なのは主にキー列です。キー列は、等価条件、範囲条件、並び替え、結合条件を見て設計します。
SELECT * のSQLにもカバリングインデックスを作るべきですか?
基本的には避けます。SELECT * をカバーしようとすると、インデックスがテーブルに近い大きさになりやすく、更新負荷も増えます。まず必要な列だけを返すようにSQLを見直します。
Key Lookupは必ず悪いですか?
必ず悪いわけではありません。少数行だけを取りに行くLookupなら問題にならないことも多いです。問題にするべきなのは、Lookupが大量に繰り返され、logical readsや実行時間を押し上げている場合です。
インデックスを作ったのに使われないのはなぜですか?
暗黙変換、列への関数適用、LIKEの前方ワイルドカード、統計情報の古さ、パラメータ値の偏り、列順の不一致などが原因になります。実行計画で Predicate、Seek Predicate、CONVERT_IMPLICIT、推定行数と実際の行数を確認します。
参考
Create indexes with included columns – SQL Server | Microsoft Learn
Clustered and nonclustered indexes – SQL Server | Microsoft Learn
まとめ
SQL Serverのカバリングインデックスは、特定のSQLに必要な列をインデックス内にそろえ、Key Lookup や余計な読み取りを減らすための設計です。検索・結合・並び替えに使う列はキー列、返すだけの列は INCLUDE に置くのが基本です。
ただし、INCLUDE列を増やしすぎると、インデックスが大きくなり、更新負荷も増えます。Query Storeや実行計画で重要なSQLを絞り、STATISTICS IO で作成前後のlogical readsを比較しながら、効果のあるインデックスだけを残すようにしましょう。