SQL Serverの実行計画を見ると、緑色の Missing Index、または「不足インデックス」の提案が表示されることがあります。一見すると、表示された CREATE INDEX をそのまま実行すれば遅いSQLが直りそうに見えます。しかし、Missing Indexはあくまでクエリ最適化時に作られる推定ベースのヒントであり、そのまま本番に作ると重複インデックスや更新負荷の増加を招くことがあります。
この記事では、SQL ServerのMissing Indexの見方、sys.dm_db_missing_index_details などのDMVで候補を確認するSQL、提案をそのまま作ってはいけない理由、既存インデックスとの統合、作成前後の検証手順を実務向けに整理します。
Missing Indexは「作るべきインデックスの答え」ではなく、「調査すべき候補」です。提案は単一クエリの最適化時の推定で作られ、列順・既存インデックスとの重複・更新負荷・インデックスサイズまでは十分に判断してくれません。まずDMVやQuery Storeで影響の大きいSQLを絞り、既存インデックスと統合できないか確認し、
STATISTICS IO と実行計画で効果測定してから採用します。Missing Indexとは
Missing Indexは、SQL Serverのクエリオプティマイザが「このような非クラスタ化インデックスがあれば、このクエリのコストを下げられる可能性がある」と判断したときに出す提案です。実行計画上のMissing Index表示や、DMVの sys.dm_db_missing_index_details、sys.dm_db_missing_index_groups、sys.dm_db_missing_index_group_stats から確認できます。
実行計画に出るため、遅いSQL調査の入口としてはとても便利です。ただし、実行されたあとに検証された結果ではなく、最適化時点の推定です。そのため、Missing Indexの提案は必ず既存インデックスや実測値と合わせて判断します。
Missing Indexをそのまま作ってはいけない理由
Microsoft Learnでも、Missing Indexの提案には制限があり、そのまま作る処方箋ではなく、インデックス分析・設計・検証の情報源のひとつとして扱うべきだと説明されています。
| 制限 | 内容 | 実務での注意 |
|---|---|---|
| 単一クエリの推定 | 最適化時の推定であり、実行後に検証されるわけではない | Query Storeや実測値で重要SQLか確認する |
| 列順が不完全 | 等価条件列の順序までは最適に並べてくれない | 選択性や既存インデックスを見て列順を決める |
| 提案は非クラスタ化行ストア中心 | 一意インデックスやフィルターインデックスは提案されない | 業務ルールに合う設計を別途検討する |
| INCLUDE列のサイズ評価が弱い | 大量の付加列を提案することがある | カバリング目的でも容量と更新負荷を見る |
| 似た提案が増えやすい | クエリごとに少し違う候補が出る | 既存インデックスと統合して数を抑える |
| 600グループ上限 | Missing Indexグループは最大600件まで | 放置すると新しい候補が収集されにくくなる |
実行計画でMissing Indexを見る
SSMSの実行計画では、Missing Indexの提案が緑色のメッセージとして表示されることがあります。ただし、グラフィカルな実行計画では複数候補のうち一部しか見えないことがあります。より正確に見るには、実行計画XMLで MissingIndexes や MissingIndex を検索します。
SELECT TOP (30)
qs.execution_count,
qs.total_logical_reads,
qs.total_worker_time,
SUBSTRING(
st.text,
(qs.statement_start_offset / 2) + 1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2) + 1
) AS statement_text,
qp.query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) AS qp
WHERE CAST(qp.query_plan AS nvarchar(max)) LIKE '%<MissingIndexes>%'
ORDER BY qs.total_logical_reads DESC;
プランキャッシュは再起動、メモリ圧迫、再コンパイルなどで消えます。継続的に見るならQuery Storeの実行計画も確認します。
DMVでMissing Index候補を一覧する
データベース内のMissing Index候補を一覧するには、Missing Index系DMVを結合します。よく使うのは sys.dm_db_missing_index_details、sys.dm_db_missing_index_groups、sys.dm_db_missing_index_group_stats です。
SELECT TOP (50)
DB_NAME(mid.database_id) AS database_name,
OBJECT_SCHEMA_NAME(mid.object_id, mid.database_id) AS schema_name,
OBJECT_NAME(mid.object_id, mid.database_id) AS table_name,
migs.user_seeks,
migs.user_scans,
migs.avg_total_user_cost,
migs.avg_user_impact,
migs.last_user_seek,
migs.last_user_scan,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns,
(migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS estimated_improvement
FROM sys.dm_db_missing_index_group_stats AS migs
JOIN sys.dm_db_missing_index_groups AS mig
ON mig.index_group_handle = migs.group_handle
JOIN sys.dm_db_missing_index_details AS mid
ON mid.index_handle = mig.index_handle
WHERE mid.database_id = DB_ID()
ORDER BY estimated_improvement DESC;
estimated_improvement は便利な並び替え指標ですが、絶対的な改善量ではありません。推定コスト、推定影響度、seek/scan回数を掛け合わせた目安として扱います。
優先度の低い候補を除外する
Missing Index候補が多い場合は、まず優先度の低いものを落とします。たとえば、実行回数が少ない、最後に使われた日時が古い、推定改善値が小さい、INCLUDE列が多すぎる候補は、いきなり作成せず後回しにします。
SELECT TOP (100)
OBJECT_SCHEMA_NAME(mid.object_id, mid.database_id) AS schema_name,
OBJECT_NAME(mid.object_id, mid.database_id) AS table_name,
migs.user_seeks,
migs.user_scans,
migs.last_user_seek,
migs.last_user_scan,
migs.avg_total_user_cost,
migs.avg_user_impact,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns,
LEN(ISNULL(mid.included_columns, '')) AS included_columns_text_length,
(migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS estimated_improvement,
CASE
WHEN (migs.user_seeks + migs.user_scans) < 10 THEN 'LOW_EXECUTIONS'
WHEN migs.avg_user_impact < 20 THEN 'LOW_IMPACT'
WHEN LEN(ISNULL(mid.included_columns, '')) > 1000 THEN 'TOO_MANY_INCLUDED_COLUMNS'
ELSE 'REVIEW'
END AS review_status
FROM sys.dm_db_missing_index_group_stats AS migs
JOIN sys.dm_db_missing_index_groups AS mig
ON mig.index_group_handle = migs.group_handle
JOIN sys.dm_db_missing_index_details AS mid
ON mid.index_handle = mig.index_handle
WHERE mid.database_id = DB_ID()
ORDER BY estimated_improvement DESC;
上の閾値は例です。重要なのは、Missing Index候補を一覧したあとに、すべてを同じ重みで扱わないことです。業務上重要な画面・API・バッチで繰り返し発生している候補から優先します。
DMVの列の読み方
| 列 | 意味 | インデックス設計での扱い |
|---|---|---|
equality_columns |
= のような等価条件に使われた列 |
キー列の前半候補。列順は選択性や既存インデックスを見て決める |
inequality_columns |
>、<、BETWEEN などの範囲条件列 |
等価条件列の後ろに置くことが多い |
included_columns |
SELECTや出力に必要な付加列 | INCLUDE 候補。ただし増やしすぎに注意する |
avg_user_impact |
インデックス追加でコストが下がる割合の推定 | 高くても実測で確認する |
user_seeks / user_scans |
候補が役立つと推定された回数 | 累積値なので起動時刻やリセットタイミングを見る |
CREATE INDEX文を生成する例
DMVの情報からCREATE INDEX文のたたき台を作ることはできます。ただし、このSQLが出力した文をそのまま本番実行するのではなく、レビュー用の候補として使います。
SELECT TOP (30)
'CREATE INDEX IX_' +
REPLACE(REPLACE(OBJECT_NAME(mid.object_id, mid.database_id), '[', ''), ']', '') +
'_missing_' + CONVERT(varchar(20), mid.index_handle) +
' ON ' + mid.statement + ' (' +
ISNULL(mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ', '
ELSE ''
END +
ISNULL(mid.inequality_columns, '') + ')' +
ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_candidate,
migs.user_seeks,
migs.user_scans,
migs.avg_total_user_cost,
migs.avg_user_impact
FROM sys.dm_db_missing_index_group_stats AS migs
JOIN sys.dm_db_missing_index_groups AS mig
ON mig.index_group_handle = migs.group_handle
JOIN sys.dm_db_missing_index_details AS mid
ON mid.index_handle = mig.index_handle
WHERE mid.database_id = DB_ID()
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans) DESC;
生成された文を見たら、次の観点で必ず修正します。インデックス名を命名規則に合わせる、列順を見直す、INCLUDE列を削る、既存インデックスと統合する、一意性やフィルター条件を考慮する、更新負荷と容量を確認する、という流れです。
既存インデックスと統合する
Missing Index候補を見る前に、対象テーブルの既存インデックスを確認します。同じ先頭列を持つ似たインデックスがすでにあるなら、新規作成ではなく統合や拡張で済むことがあります。
SELECT
i.name AS index_name,
i.type_desc,
i.is_unique,
ic.key_ordinal,
ic.is_included_column,
c.name AS column_name
FROM sys.indexes AS i
JOIN sys.index_columns AS ic
ON ic.object_id = i.object_id
AND ic.index_id = i.index_id
JOIN sys.columns AS c
ON c.object_id = ic.object_id
AND c.column_id = ic.column_id
WHERE i.object_id = OBJECT_ID(N'dbo.Orders')
ORDER BY i.name, ic.key_ordinal, ic.index_column_id;
似たインデックスが増えると、SELECTは速くなるかもしれませんが、INSERT、UPDATE、DELETE、バックアップ、メンテナンス、メモリ使用量に悪影響が出ます。既存インデックスの使用状況も合わせて見ます。
SELECT
OBJECT_SCHEMA_NAME(i.object_id) AS schema_name,
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
us.user_seeks,
us.user_scans,
us.user_lookups,
us.user_updates,
us.last_user_seek,
us.last_user_scan,
us.last_user_update
FROM sys.indexes AS i
LEFT JOIN sys.dm_db_index_usage_stats AS us
ON us.object_id = i.object_id
AND us.index_id = i.index_id
AND us.database_id = DB_ID()
WHERE i.object_id = OBJECT_ID(N'dbo.Orders')
AND i.name IS NOT NULL
ORDER BY us.user_updates DESC, us.user_seeks DESC;
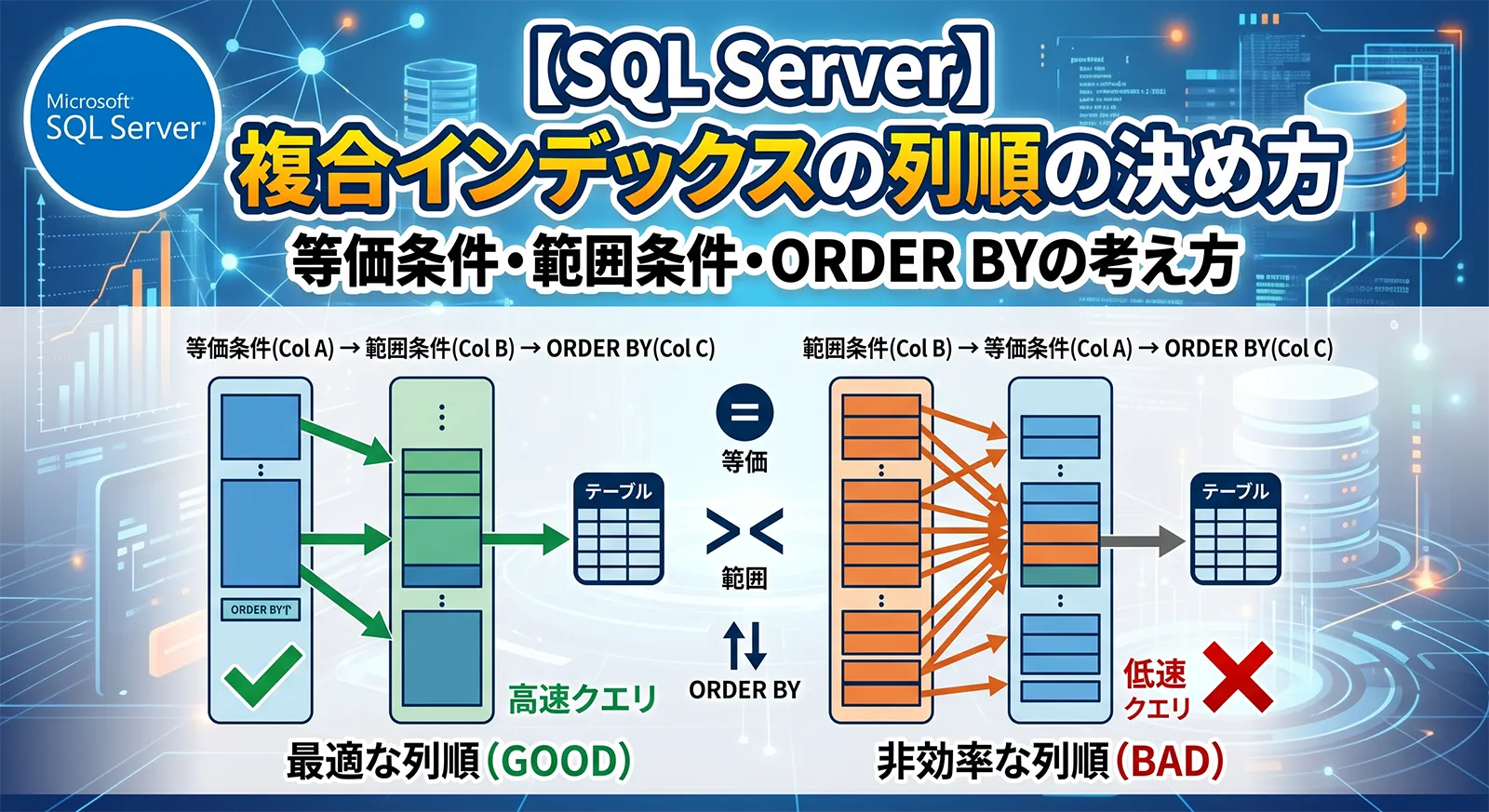
列順を決める
Missing Indexの提案では、等価条件列と範囲条件列は分かりますが、等価条件列の最適な順番まで完全には決めてくれません。一般的には、等価条件列を先に置き、その中では選択性の高い列を左側に置くことを検討します。その後ろに範囲条件列を置き、必要な返却列をINCLUDEに回します。
| 条件 | 置き場所の目安 | 例 |
|---|---|---|
| 等価条件 | キー列の前半 | CustomerID = @CustomerID |
| 範囲条件 | 等価条件列の後ろ | OrderDate >= @FromDate |
| 並び替え | キー列で吸収できるか確認 | ORDER BY OrderDate DESC |
| 返すだけの列 | INCLUDE |
TotalAmount、Status |
複合インデックスの列順は、今後単独記事でさらに深掘りできます。この記事では、Missing Index候補をそのまま採用せず、列の役割を分けて設計し直すことを重視します。
作成前にサイズと更新負荷を見る
候補インデックスの列が多いほど、インデックスは大きくなります。INCLUDE列が多い候補は、特にサイズと更新負荷を確認します。
SELECT
OBJECT_SCHEMA_NAME(i.object_id) AS schema_name,
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
SUM(ps.used_page_count) * 8.0 / 1024 AS used_mb,
SUM(ps.row_count) AS row_count
FROM sys.indexes AS i
JOIN sys.dm_db_partition_stats AS ps
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE i.object_id = OBJECT_ID(N'dbo.Orders')
GROUP BY i.object_id, i.name
ORDER BY used_mb DESC;
SQL Serverのインデックス断片化を確認・再構築する方法
作成前後で効果を検証する
インデックスを作る前後で、同じSQL、同じパラメータ、同じ条件で比較します。実行時間だけでなく、logical reads、実行計画、Key Lookupの有無、Sortの有無、更新負荷も見ます。
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
-- 作成前後で同じ条件で比較する
SELECT
OrderID,
CustomerID,
OrderDate,
TotalAmount,
Status
FROM dbo.Orders
WHERE CustomerID = 100
AND OrderDate >= '2026-05-01'
AND OrderDate < '2026-06-01';
SET STATISTICS TIME OFF;
SET STATISTICS IO OFF;
Missing Indexの提案を採用しても、暗黙変換、列への関数適用、LIKEの前方ワイルドカード、統計情報の古さが残っていると、期待どおりに使われないことがあります。
採用判断チェックリスト
最終的にインデックスを作る前に、次の項目を確認します。ひとつでも不安が残る場合は、検証環境での比較や既存インデックスとの統合案を先に作ります。
| 確認項目 | 採用しやすい状態 | 見送り・再設計しやすい状態 |
|---|---|---|
| 対象SQL | Query Storeで実行回数や累積読み取りが大きい | 一度だけ実行されたSQL、業務影響が小さいSQL |
| 既存インデックス | 同じ役割のインデックスがなく、統合案も明確 | 似たインデックスが複数あり、重複が増える |
| 列順 | 等価条件、範囲条件、ORDER BYの役割を説明できる | DMVの出力順をそのまま信じている |
| INCLUDE列 | 返却に必要な列だけに絞れている | SELECT列を全部入れてインデックスが大きくなる |
| 更新負荷 | INSERT/UPDATE/DELETEへの影響を許容できる | 更新が多い表で保守時間やログ容量が読めない |
| 効果測定 | 作成前後の実行計画とlogical readsを比較できる | 速くなったか確認する手段がない |
Query Storeで継続的に見る
Missing IndexのDMVやプランキャッシュは、再起動やフェイルオーバー、DBのオフライン化などで消えることがあります。継続的に見たい場合はQuery Storeを使い、実行回数やlogical readsの大きいSQLから優先順位を決めます。
SELECT TOP (20)
qsq.query_id,
SUM(qrs.count_executions) AS executions,
AVG(qrs.avg_logical_io_reads) AS avg_logical_reads,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) AS estimated_total_reads,
MAX(qsp.plan_id) AS sample_plan_id,
MIN(qsrsi.start_time) AS first_seen,
MAX(qsrsi.end_time) AS last_seen
FROM sys.query_store_query AS qsq
JOIN sys.query_store_plan AS qsp
ON qsp.query_id = qsq.query_id
JOIN sys.query_store_runtime_stats AS qrs
ON qrs.plan_id = qsp.plan_id
JOIN sys.query_store_runtime_stats_interval AS qsrsi
ON qsrsi.runtime_stats_interval_id = qrs.runtime_stats_interval_id
WHERE qsp.query_plan LIKE N'%<MissingIndexes>%'
AND qsrsi.start_time >= DATEADD(HOUR, -48, SYSDATETIME())
GROUP BY qsq.query_id
ORDER BY estimated_total_reads DESC;
Query Storeで候補を絞ると、単発の重いSQLではなく、累積で効いているSQLを見つけやすくなります。パラメータ値によって実行計画が変わる場合は、パラメータスニッフィングも合わせて確認します。
権限とリセットタイミング
Missing Index系DMVの参照には、SQL Serverでは VIEW SERVER STATE、SQL Server 2022以降では VIEW SERVER PERFORMANCE STATE が必要になる場合があります。Azure SQL Databaseではサービスレベルやロールによって必要権限が変わります。
また、Missing Index情報は永続化されません。SQL Serverの再起動、フェイルオーバー、DBのオフライン化、対象テーブルのメタデータ変更、そのテーブルへの ALTER INDEX などで消えることがあります。重要な候補は、定期的に保存するかQuery Storeから追えるようにしておきます。
SELECT sqlserver_start_time FROM sys.dm_os_sys_info;
やってはいけないパターン
| NG | なぜ危険か | 代わりにやること |
|---|---|---|
| 実行計画のMissing Indexをそのまま作る | 既存インデックスとの重複や列順の問題を見落とす | 既存インデックスと統合して候補を作り直す |
| 提案が出たSQLだけを見る | 他のSQLの更新負荷や実行計画に悪影響が出る | Query Storeでワークロード全体を見る |
| INCLUDE列を全部採用する | インデックスが大きくなりすぎる | 返却に本当に必要な列だけに絞る |
| 似たインデックスを何本も作る | 更新負荷、容量、保守時間が増える | 同じ先頭キーのインデックスを統合する |
| 効果測定なしで本番投入する | 速くなったか判断できない | STATISTICS IOと実行計画を保存して比較する |
よくある質問
Missing Indexが出たら必ずインデックス不足ですか?
必ずではありません。暗黙変換、統計情報の古さ、パラメータ値の偏り、SQLの書き方が原因で、別のインデックス候補が出ているだけの場合もあります。実行計画と実測値を確認してから判断します。
Missing Indexの推奨インデックス名をそのまま使ってよいですか?
避けたほうがよいです。生成SQLは調査用の候補です。命名規則に合わせ、対象テーブル、主要キー列、用途が分かる名前にします。
Missing IndexのDMVに出ないなら問題はありませんか?
そうとは限りません。提案はtrivial planでは出ないことがあり、再起動などで消えます。また、一意インデックスやフィルターインデックスのような候補は提案されません。実行計画、Query Store、業務要件を合わせて見ます。
作ったインデックスが使われているかはどう確認しますか?
実行計画で対象インデックスが使われているか、STATISTICS IO のlogical readsが減ったか、sys.dm_db_index_usage_stats のseek/scanが増えているかを確認します。ただし、usage statsも再起動などでリセットされます。
参考
Tune nonclustered indexes with missing index suggestions – Microsoft Learn
sys.dm_db_missing_index_details – Microsoft Learn
まとめ
SQL ServerのMissing Indexは、遅いSQL調査の入口として便利です。ただし、提案は単一クエリの最適化時の推定であり、列順、既存インデックスとの重複、INCLUDE列のサイズ、更新負荷、ワークロード全体への影響までは十分に判断してくれません。
Missing Indexを見つけたら、まずDMVやQuery Storeで影響の大きい候補を絞り、既存インデックスと統合できないか確認します。そのうえで STATISTICS IO、実行計画、Query Storeで作成前後を比較し、本当に効果のあるインデックスだけを採用しましょう。