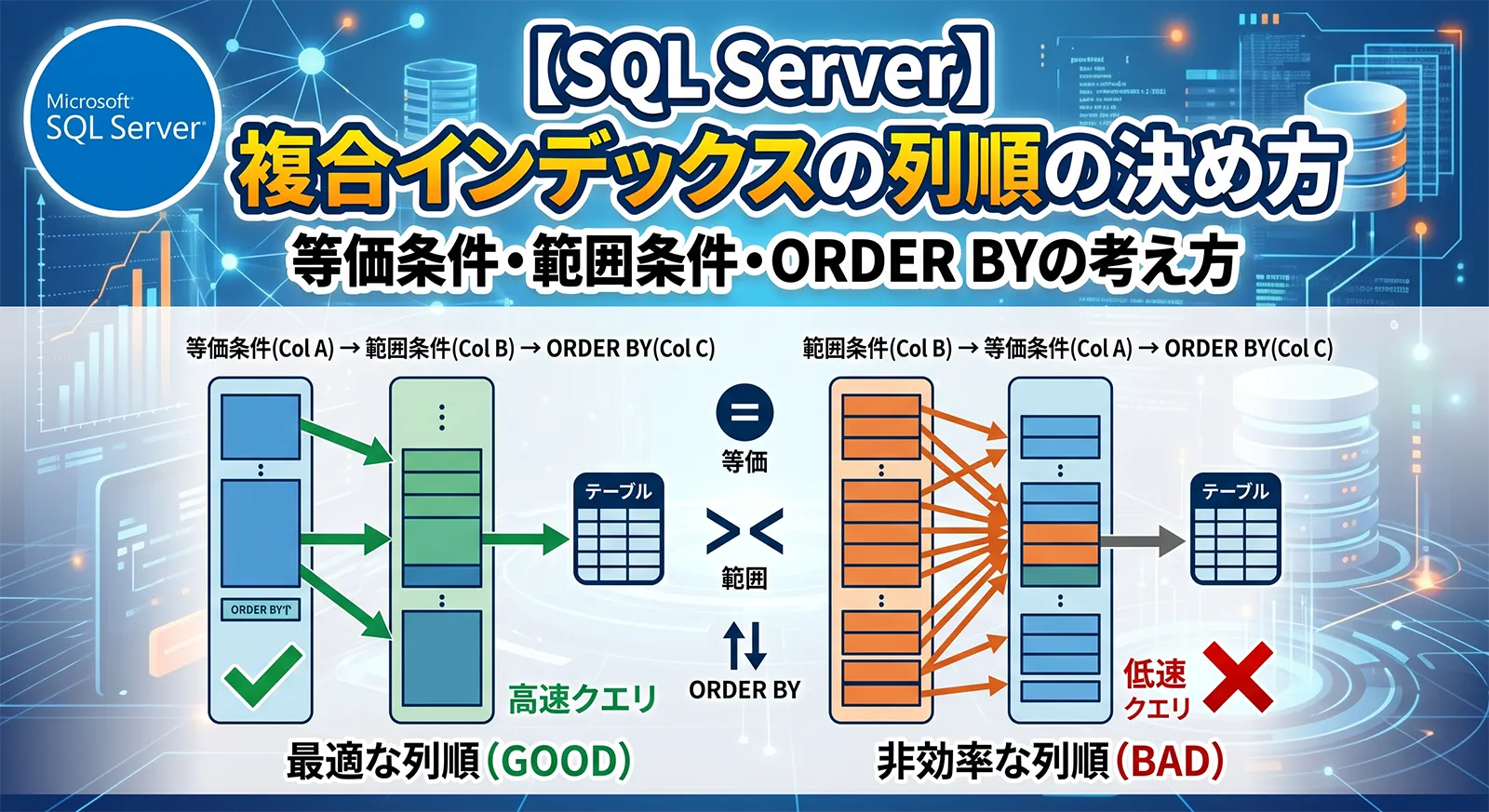
SQL Serverで複合インデックスを作るとき、いちばん迷いやすいのが列順です。(CustomerID, OrderDate) と (OrderDate, CustomerID) は似ていますが、検索条件、範囲条件、並び替え、JOINの使われ方によって効き方が変わります。列を全部入れればよいわけではなく、左側の列からどのように絞れるかが重要です。
この記事では、SQL Serverの複合インデックスの列順を、等価条件、範囲条件、ORDER BY、JOIN、INCLUDE句、Missing Index提案からの見直しまで、実務で判断しやすい形で整理します。
まず、
WHEREやJOINでよく使う等価条件列を左側に置きます。範囲条件列は等価条件列の後ろに置くことが多く、ORDER BYを消したい場合は並び順も含めてキー列を検討します。SELECTで返すだけの列はキー列にせず、INCLUDEに回します。ただし、固定ルールではなく、実行計画とSTATISTICS IOで確認して採用します。列順の早見表
迷ったときは、まず対象SQLを1本に絞り、そのSQLがどの条件で行数を減らしているかを見ます。次の表は、複合インデックスの列順を決めるときの出発点です。
| よくあるSQL | 候補にする列順 | 見るポイント |
|---|---|---|
WHERE CustomerID = ? AND OrderDate BETWEEN ? AND ? |
(CustomerID, OrderDate) |
等価条件で絞ってから、日付範囲を読む |
WHERE Status = ? ORDER BY OrderDate DESC |
(Status, OrderDate DESC) |
絞り込み後にSortを減らせるかを見る |
WHERE OrderDate BETWEEN ? AND ? |
(OrderDate) または (OrderDate, ...) |
日付検索だけが主目的なら日付列を左側に置く |
JOIN ... ON o.CustomerID = c.CustomerID |
WHERE条件とJOIN列を合わせて検討 | どちらの表から読み始める計画になるかを見る |
| SELECTで返すだけの列が多い | キー列ではなくINCLUDE |
Key Lookupを減らしつつ、キーを太くしすぎない |
この早見表は最終回答ではなく、検証する候補を作るためのものです。実際には、データ量、選択性、実行頻度、既存インデックス、更新負荷まで含めて判断します。
複合インデックスとは
複合インデックスは、複数列をキーとして持つインデックスです。たとえば次のインデックスは、CustomerID、OrderDateの順に並んだ非クラスタ化インデックスです。
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDate ON dbo.Orders (CustomerID, OrderDate);
このインデックスは、CustomerIDで絞るSQLには効きやすいですが、OrderDateだけで検索するSQLには効きにくいことがあります。SQL Serverのインデックスはキー列の順序に意味があり、左側の列から使えるかどうかが大きな判断ポイントになります。
列順を決める基本
Microsoft Learnのインデックス設計ガイドでは、複数列のキーでは、等価条件、範囲条件、BETWEEN、JOINに参加する列を考慮し、追加列は distinctness の高さも見て並べると説明されています。実務では、次の順で考えると整理しやすいです。
| 優先 | 列の種類 | 考え方 |
|---|---|---|
| 1 | 等価条件の列 | CustomerID = @CustomerID のように一点で絞る列 |
| 2 | JOIN条件の列 | 結合で頻繁に使われる列。対象SQLの駆動表も確認する |
| 3 | 範囲条件の列 | OrderDate >= @From のような範囲検索列 |
| 4 | ORDER BY / GROUP BYに効かせたい列 | Sortを消せるか、集計前の順序に合うかを見る |
| 5 | 返すだけの列 | キー列ではなくINCLUDEに回す候補 |
ただし、これは固定の公式ではありません。実行頻度、選択性、既存インデックス、更新負荷、対象SQLの数によって最適解は変わります。
等価条件を左側に置く例
次のSQLでは、CustomerIDが等価条件、OrderDateが範囲条件です。この場合、まずは (CustomerID, OrderDate) の順を候補にします。
SELECT
OrderID,
CustomerID,
OrderDate,
TotalAmount
FROM dbo.Orders
WHERE CustomerID = 100
AND OrderDate >= '2026-05-01'
AND OrderDate < '2026-06-01';
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDate ON dbo.Orders (CustomerID, OrderDate) INCLUDE (TotalAmount);
CustomerIDで対象顧客を絞り、その範囲内でOrderDateの期間を読む形です。このSQLに対して (OrderDate, CustomerID) を作ると、期間に含まれる全顧客の注文を広く読んでから、CustomerIDで絞るような計画になりやすくなります。
範囲条件を左に置くとどうなるか
範囲条件列を左側に置くと、その範囲を読んだあと、後続列での絞り込みが効きにくくなることがあります。すべてのケースで悪いわけではありませんが、範囲が広いと読み取り量が増えやすいです。
CREATE NONCLUSTERED INDEX IX_Orders_OrderDate_CustomerID ON dbo.Orders (OrderDate, CustomerID) INCLUDE (TotalAmount);
| 列順 | 向いているSQL | 注意点 |
|---|---|---|
(CustomerID, OrderDate) |
顧客ごとの期間検索 | CustomerIDを指定しない期間検索には弱いことがある |
(OrderDate, CustomerID) |
日付範囲を軸にした検索、日付順一覧 | 期間が広いとCustomerID条件の効果が薄くなることがある |
つまり、列順は「どの条件があるか」だけでなく、どの条件でどれくらい絞れるか、どのSQLが業務上重要かで決めます。
ORDER BYを消したい場合の列順
ORDER BYに合うキー列順を作ると、実行計画からSortを消せることがあります。SQL Serverでは、インデックスキー列に ASC / DESC を指定できます。
SELECT TOP (50)
OrderID,
CustomerID,
OrderDate,
TotalAmount
FROM dbo.Orders
WHERE CustomerID = 100
ORDER BY OrderDate DESC;
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDateDesc ON dbo.Orders (CustomerID, OrderDate DESC) INCLUDE (TotalAmount);
この例では、CustomerIDで絞ったうえで、OrderDate DESCの順に読み出せます。実行計画でSortが消えるか、Topと組み合わさって少ない読み取りで済むかを確認します。
JOIN条件を含む列順
JOINで使う列もインデックス設計の重要な候補です。ただし、JOIN列を必ず左端に置けばよいわけではありません。どちらの表から読み始めるか、JOIN前にWHEREでどれくらい絞れるかを見ます。
SELECT
o.OrderID,
o.CustomerID,
o.OrderDate,
c.CustomerName
FROM dbo.Orders AS o
JOIN dbo.Customers AS c
ON c.CustomerID = o.CustomerID
WHERE o.Status = 'Shipped'
AND o.OrderDate >= '2026-05-01'
AND o.OrderDate < '2026-06-01';
この場合、Orders側では Status と OrderDate で絞ってからJOINするのか、CustomerIDを軸にJOINするのかで候補が変わります。実行計画で駆動表、推定行数、実際の行数を確認します。
SELECT列はINCLUDEに回す
SELECTで返すだけの列までキー列に入れると、インデックスキーが太くなり、更新負荷や容量が増えます。検索、結合、並び替えに使わない列は INCLUDE に回すのが基本です。
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDate ON dbo.Orders (CustomerID, OrderDate) INCLUDE (TotalAmount, Status, ShippingMethod);
Microsoft Learnでも、検索やルックアップに使う列だけをキー列にし、クエリをカバーするための列は非キー列にする設計が推奨されています。INCLUDE列の順番は、クエリ性能には大きく影響しません。
Missing Index提案から列順を見直す
Missing Indexでは、equality_columns、inequality_columns、included_columns が表示されます。ただし、等価条件列の順番や既存インデックスとの統合までは十分に判断してくれません。
| Missing Indexの列 | 設計時の見直し |
|---|---|
equality_columns |
等価条件列。選択性、実行頻度、既存インデックスを見て順番を決める |
inequality_columns |
範囲条件列。等価条件列の後ろに置くことが多い |
included_columns |
返却列候補。全部採用せず、必要な列に絞る |
Missing Indexから候補を作る場合でも、最終的にはSQLの形を見て列順を設計し直します。
既存インデックスとの重複を確認する
複合インデックスを増やす前に、対象テーブルの既存インデックスを確認します。同じ先頭列を持つインデックスが複数ある場合、新規作成ではなく統合できることがあります。
SELECT
i.name AS index_name,
i.type_desc,
i.is_unique,
ic.key_ordinal,
ic.is_included_column,
ic.is_descending_key,
c.name AS column_name
FROM sys.indexes AS i
JOIN sys.index_columns AS ic
ON ic.object_id = i.object_id
AND ic.index_id = i.index_id
JOIN sys.columns AS c
ON c.object_id = ic.object_id
AND c.column_id = ic.column_id
WHERE i.object_id = OBJECT_ID(N'dbo.Orders')
ORDER BY i.name, ic.key_ordinal, ic.index_column_id;
似たインデックスが増えると、更新、容量、断片化保守、バックアップ、メモリ使用量に影響します。作る前に、既存インデックスを拡張するほうがよいか、新規作成するほうがよいかを比較します。
SQL Serverのインデックス断片化を確認・再構築する方法
インデックスが使われない列順の例
複合インデックスは、左側の列を使わないSQLに弱いことがあります。たとえば (CustomerID, OrderDate) がある状態で、OrderDate だけを検索するSQLです。
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_OrderDate ON dbo.Orders (CustomerID, OrderDate); -- CustomerIDを指定していないため、効きにくいことがある SELECT OrderID, CustomerID, OrderDate FROM dbo.Orders WHERE OrderDate >= '2026-05-01' AND OrderDate < '2026-06-01';
このSQLが重要なら、日付軸のインデックスを別に検討するか、既存インデックスとの統合が可能かを確認します。ただし、似たインデックスを増やしすぎると更新負荷が増えるため、Query Storeで実行頻度を確認します。
作成前後で効果を測る
列順を決めたら、必ず作成前後で実測します。実行計画でSeek PredicateとPredicateの違い、Sortの有無、Key Lookupの有無、logical readsを確認します。
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT
OrderID,
CustomerID,
OrderDate,
TotalAmount
FROM dbo.Orders
WHERE CustomerID = 100
AND OrderDate >= '2026-05-01'
AND OrderDate < '2026-06-01'
ORDER BY OrderDate DESC;
SET STATISTICS TIME OFF;
SET STATISTICS IO OFF;
統計情報が古いと、列順が適切でも実行計画が期待どおりにならないことがあります。推定行数と実際の行数が大きくずれている場合は、統計情報も確認します。
よくある失敗パターン
| 失敗 | 問題 | 見直し |
|---|---|---|
| WHEREに出る列を全部キー列にする | インデックスが太くなり、更新負荷が増える | 役割を見てキー列とINCLUDE列に分ける |
| 範囲条件を左端に置く | 範囲が広いと後続列で絞りにくい | 等価条件列を左に置けないか検討する |
| ORDER BYを無視する | Sortが残って重い | 並び順を含めたキー列を検討する |
| Missing Indexをそのまま作る | 列順や既存インデックスとの重複を見落とす | 候補を設計し直す |
| 似たインデックスを増やし続ける | 更新・保守・容量の負荷が増える | 既存インデックスと統合する |
採用判断チェックリスト
| 確認 | 見ること |
|---|---|
| 対象SQL | Query Storeで実行回数や累積読み取りが大きいか |
| 条件の種類 | 等価条件、範囲条件、JOIN、ORDER BYを分けたか |
| 列順 | 左側の列から効く理由を説明できるか |
| INCLUDE | 返すだけの列をキー列にしていないか |
| 既存インデックス | 似たインデックスを増やしていないか |
| 効果測定 | 作成前後のlogical readsと実行計画を比較したか |
よくある質問
等価条件列は必ず選択性が高い順に並べますか?
選択性は重要ですが、それだけでは決めません。JOIN、ORDER BY、他SQLとの共用、既存インデックスとの統合も見ます。等価条件列が複数ある場合は、実行頻度が高いSQLでどう使われるかを優先します。
範囲条件列は必ず最後ですか?
多くの場合は等価条件列の後ろに置きますが、日付範囲検索が主目的の一覧や集計では日付列を左側に置くこともあります。範囲の広さと対象SQLの重要度で判断します。
ORDER BY用のDESC指定は必要ですか?
必要になることがあります。ORDER BYの方向とインデックスキーの方向が合うとSortを消せる場合があります。ただし、SQL Serverはインデックスを逆方向に読むこともできるため、複数列の昇順・降順の組み合わせを実行計画で確認します。
複合インデックスとカバリングインデックスは違いますか?
観点が違います。複合インデックスは複数のキー列を持つインデックスです。カバリングインデックスは、クエリに必要な列をキー列またはINCLUDE列で満たして、Lookupを減らす設計です。実務では両方を組み合わせることが多いです。
参考
SQL Server index architecture and design guide – Microsoft Learn
Create indexes with included columns – Microsoft Learn
まとめ
SQL Serverの複合インデックスは、列を並べる順番で効き方が変わります。まず等価条件やJOINでよく使う列を左側に置き、範囲条件やORDER BYの列を後ろに続けるのが基本です。SELECTで返すだけの列はキー列にせず、INCLUDEに回します。
ただし、列順は固定ルールだけでは決まりません。対象SQLの実行頻度、選択性、既存インデックス、SortやKey Lookupの有無、更新負荷を見て、STATISTICS IO と実行計画で効果を確認しながら設計しましょう。